
關於Jmeter引數化的編碼問題
大家用jmeter最常遇到的是請求引數中文亂碼問題(至於返回值亂碼問題由於處理簡單也不影響測試,就不在這裡說了),而對於這個問題,很多人不能從根本上去分析和理解,所以就無法從根本上去迴避和解決,以下我就通過幾種情況來分別說明:
在這之前,先做好測試案例:
(1)準備CSV資料檔案,內容只有三列:1,test,測試

注意:這裡的檔名含路徑,linux下必須是csvData/ID2.csv(如果用反斜槓,在linux下就找不到檔案,而jmeter4.0非常糟糕的一點是正斜槓儲存完後也會變成反斜槓,只能通過編輯器批量修改,為了避免麻煩,可以不用像我這樣,只要把指令碼和csv儲存在bin下就行,這樣只需要輸入檔名ID2.csv即可)。
(2)分別準備三個請求,這三類請求基本覆蓋了常見的引數化亂碼問題
一個是在請求名稱中帶所有引數,用的是BeanShell

一個是key-value引數格式的請求

一個是Body Data格式的請求

下面我們就可以開始測試了。
場景一:預設ANSI/ASCII格式的引數化檔案
我們在設定CSV資料檔案時,檔案編碼置空不做選擇,進行測試後發現在windows下兩請求編碼正常(第3個請求後面再說):

而在Linux下卻是亂碼

我們做一下設定,在設定CSV資料檔案時,加上GBK編碼

這時再測試,就會發現linux下和windows下都正常編碼了。


註釋:設定CSV資料檔案,編碼項是可選的,但不一定會有GBK選項,要麼手填,要麼修改jmeter.properties

場景二:用UTF-8格式的引數化檔案(最好是用編輯器儲存為UTF-8 無bom頭)
同樣預設情況下設定CSV資料檔案時,檔案編碼置空不做選擇

我們將UTF-8格式的ID2.csv同時覆蓋到windows和linux下進行測試
我們發現windows下顯示亂碼了

而linux下卻正常了

同樣我們做一下設定,在設定CSV資料檔案時,加上UTF-8編碼

儲存後再進行測試,發現windows下和linux下都正常了

通過以上兩個場景的對比測試,我們發現一個道理,就是設定CSV資料檔案時,檔案編碼的配置是在告訴jmeter,將以什麼編碼格式顯示引數檔案的資料,如果不配置即按作業系統的預設編碼格式顯示(windows下是GBK或gb2312,linux下是UTF-8)。而一旦出現顯示的編碼格式與csv檔案的編碼格式不統一時,就會出現亂碼。為了避免錯亂,我們就統一將CSV儲存為UTF-8格式,統一在設定CSV資料檔案的面板中,檔案編碼選擇UTF-8。
場景三:對Body Data格式請求的中文引數測試
在確保以上兩個場景的問題處理完後,我們是否就解決了亂碼問題,答案是否定的。因為以上的方式只是保證jmter傳送的URL請求格式不會有亂碼,但不能保證body或json中是否沒有亂碼。在前兩個請求都正常的情況下,我們在看看第三個請求的結果:
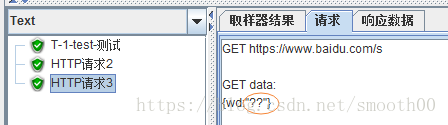
為什麼會這樣,我們通過解開jmeter的原始碼,就能找到答案(以下是節選PostWriter.java中的兩段原始碼):
public static final String ENCODING = StandardCharsets.ISO_8859_1.name();
public String sendPostData(URLConnection connection, HTTPSamplerBase sampler) throws IOException {
// Buffer to hold the post body, except file content
StringBuilder postedBody = new StringBuilder(1000);
HTTPFileArg[] files = sampler.getHTTPFiles();
String contentEncoding = sampler.getContentEncoding();
if(contentEncoding == null || contentEncoding.length() == 0) {
contentEncoding = ENCODING;
}
//此處省略程式碼.......
return postedBody.toString();
}通過以上程式碼可以看出,PostData是需要設定編碼格式的,而且預設編碼字元是ISO_8859_1(第一行程式碼),編碼讀取的是Content Encoding,這個在jmeter的http請求面板上就能看到。我們配置成UTF-8試試:

發現還是亂碼,但是這個亂碼能看出已經能夠識別出utf-8字元了:
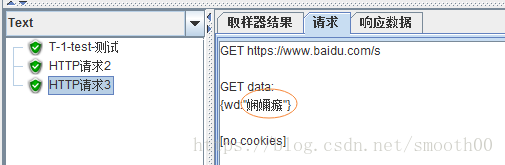
這也說明了編碼還是不一致,死記萬能的UTF-8是行不通的,我們換個GBK或gb2312試試:
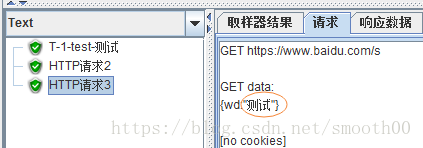
正常顯示中文了!!!!!
場景四:還有種編碼叫URLEncoder
不是所有的請求,直接傳送中文就能正常得到響應,這還要取決於web應用服務端的相關編碼處理。先了解一下什麼是URLEncoder:url編碼是一種瀏覽器用來打包表單輸入的格式。瀏覽器從表單中獲取所有的name和其中的值 ,將它們以name/value引數編碼(移去那些不能傳送的字元,將資料排行等等)作為URL的一部分或者分離地發給伺服器。
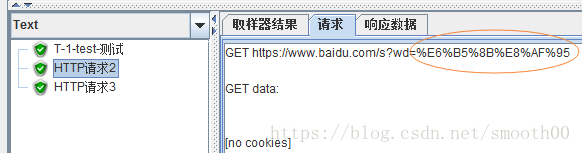
為了避免明文傳送中文或是去除/轉譯非法字元,URL編碼是非常必要的,在http請求中對URL引數進行URL編碼的方式如下(勾選編碼):

進行URL編碼後的請求效果如下:
當然也可以通過BeanShell PreProcessor來實現對{name}引數URL編碼,如下:
vars.put("name",URLEncoder.encode("${name}","UTF-8"));有了編碼,就有解碼URLDecoder.decode,這是在應用服務端實現的。我們也可以在jmeter上模擬解碼過程,如下:
vars.put("name",URLDecoder.decode("${name}","utf-8"));針對中文引數化的編碼問題,我們就舉這四個場景,當然解決的方式不僅限於上面所羅列的。思路是一樣的,方法是多樣的,包括直接修改jmeter的原始碼,重新編譯一個你自己的jmeter也行。通過以上的方式,我們也發現utf-8編碼是相對通用的,因為在linux下和windows下都能得到相應的解決和處理。
附:其他注意事項
1、預設linux可能不支援中文,可以通過以下方式簡單處理:
編輯i18n配置檔案: vi /etc/sysconfig/i18n
進行如下配置並儲存退出:
#LANG="en_US.UTF-8"
LANG="zh_CN.UTF-8"
SYSFONT="latarcyrheb-sun16"
執行以下命令即時生效
source /etc/sysconfig/i18n
2、在linux下對於jmeter的csv引數檔案不要命名為ID.CSV
原因不明,至少在jmeter4.0下測試發現了問題,這樣命名的檔案,要麼是傳送訊息為亂碼,要麼是讀取不到引數。
3、將csv引數統一為UTF-8編碼是解決編碼相容性的好辦法,以下提供一個我自己寫的在linux下批量轉換csv為utf-8編碼的指令碼:
#!/bin/bash
### 將 values_here 替換為輸入編碼
#FROM_ENCODING="value_here"
### 輸出編碼 (UTF-8)
TO_ENCODING="UTF-8"
### 轉換命令
#CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
### 使用迴圈轉換多個檔案
for file in *.csv; do
rm -f ${file%.csv}.csv.bak #先清理備份檔案
mv ${file%.csv}.csv ${file%.csv}.csv.bak #轉換前先備份檔案
#以下為獲取csv檔案的原編碼格式
FROM_ENCODING=$(file -i ${file%.csv}.csv.bak | awk '{print $3}' | sed '1s/charset=//g')
#對於識別不了的編碼暫時歸為GBK
if [ "$FROM_ENCODING" = "unknown-8bit" ];then
FROM_ENCODING=$(echo "GBK")
fi
CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
$CONVERT "${file%.csv}.csv.bak" -o "$file"
#$CONVERT "$file" -o "${file%.csv}.csv"
done
exit 0將指令碼放在csv檔案目錄下,給指令碼賦可執行許可權,執行完後就能將當前目錄下的csv編碼格式全轉成utf-8