
實用詳解spark的讀取方法textFile和wholeTextFiles
談清楚區別,說明道理,從案例start:
1 資料準備
用hdfs存放資料,且結合的hue服務上傳準備的資料,我的hue上資料截圖:
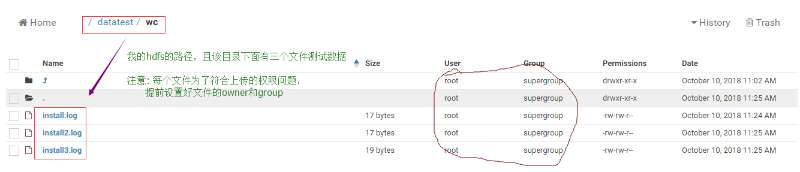
三個檔案下的資料分別為:
l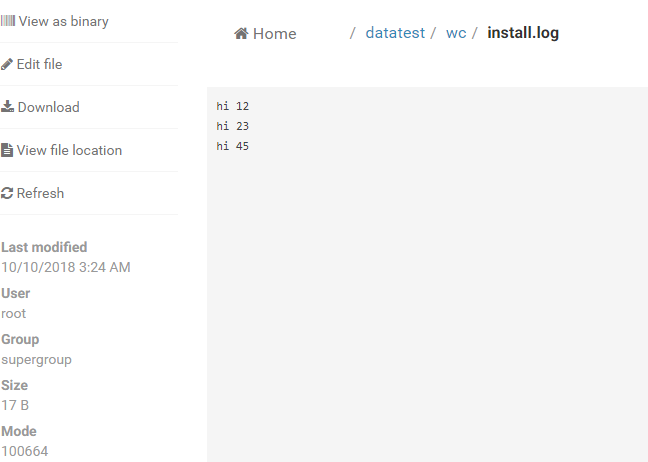
AND
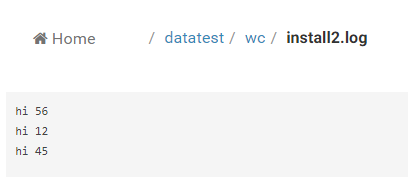
AND
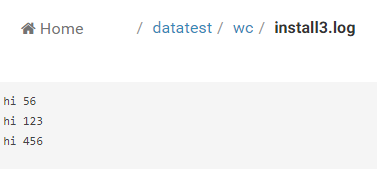
以上是3個檔案的資料,每一行用英文下的空格隔開;
2 測試 sc.textFile()和sc.wholeTextFiles()的效果
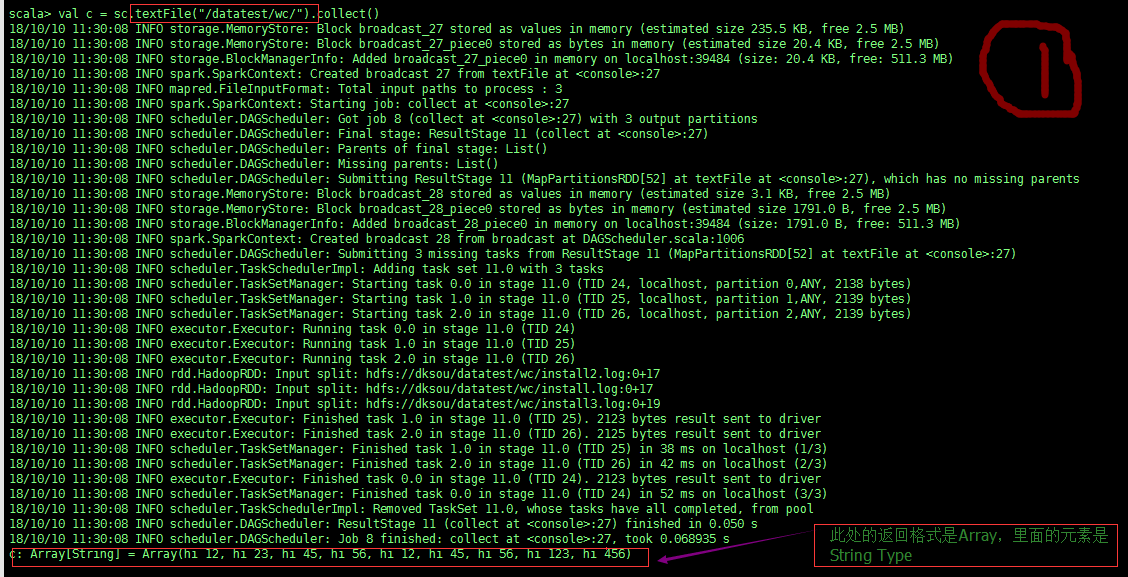
sc.testFile() 如圖:
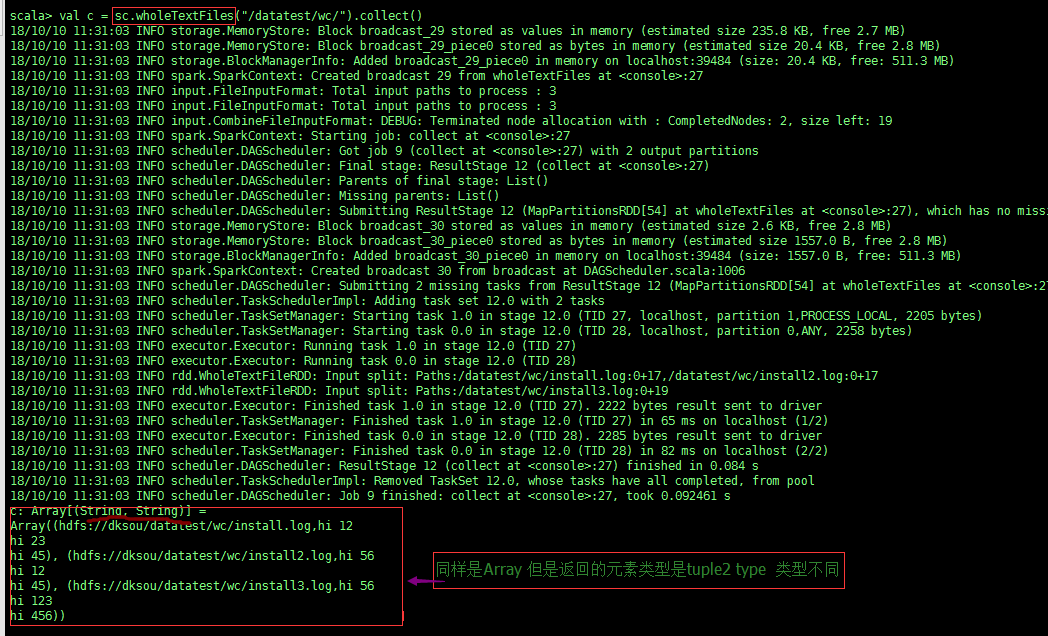
sc.wholetextFiles() 如下圖:
注意 一定要仔細觀察紅色方框圈起來的差異,經過以上兩次截圖中實驗的對比,我們得出重要的結論:
sc.textFiles(path) 能將path 裡的所有檔案內容讀出,以檔案中的每一行作為一條記錄的方式,
檔案的每一行 相當於 List中以 “,”號 隔開的一個元素,因此可以在每個partition中用for i in data的形式遍歷處理Array裡的資料;
而使用 sc.wholeTextFiles()時: 返回的是[(K1, V1), (K2, V2)...]的形式,其中K是檔案路徑,V是檔案內容,這裡我們要注意的重點是: 官方一句話:''Each file is read as a single record'' 這句話,每個檔案作為一個記錄!這說明這裡的 V 將不再是 list 的方式為你將檔案每行拆成一個 list的元素, 而是將整個文字的內容以字串的形式讀進來,也就是說val = '...line1...\n...line2...\n' 這時需要你自己去拆分每行!而如果你還是用for i in val的形式來便利 val那麼i得到的將是每個字元.
3 兩種讀取檔案下與partition的數量關係
理論最後總結,先上2張實用資料測試截圖:

PK

從上面的操作來看,總結如下:
用textFile時,它的partition的數量是與資料夾下的檔案數量(例項中用3個xxx.log檔案)相關,一個檔案就是一個partition(既然3個檔案就是:partition=3)。wholeTextFiles的partition數量是根據使用者指定或者檔案大小來(檔案內的資料量少 有hdfs原始碼預設確定的)確定,與hdfs目錄下的檔案數量無關! 所以說:wholeTextFile通常用於讀取許多小檔案的需求。
適用為主,學習借鑑~