
四、Kafka 核心原始碼剖析
一、Kafka消費者原始碼介紹
1.分割槽消費模式原始碼介紹

分割槽消費模式直接由客戶端(任何高階語言編寫)使用Kafka提供的協議向伺服器傳送RPC請求獲取資料,伺服器接受到客戶端的RPC請求後,將資料構造成RPC響應,返回給客戶端,客戶端解析相應的RPC響應獲取資料。Kafka支援的協議眾多,使用比較重要的有:獲取訊息的FetchRequest和FetchResponse獲取offset的OffsetRequest和OffsetResponse提交offset的OffsetCommitRequest和OffsetCommitResponse獲取Metadata的Metadata Request和Metadata Response生產訊息的ProducerRequest和ProducerResponse
2.組消費模式原始碼介紹
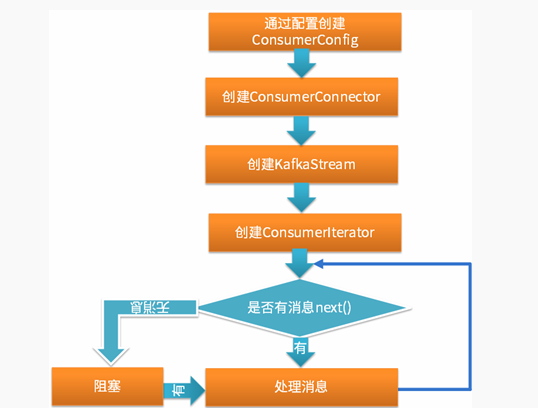

3.兩種消費模式伺服器端原始碼對比
分割槽消費模式具有以下特點:指定消費topic、partition和offset通過向伺服器傳送RPC請求進行消費;需要自己提交offset;需要自己處理各種錯誤,如:leader切換錯誤需要自己處理消費者負載均衡策略組消費模式具有以下特點:最終也是通過向伺服器傳送RPC請求完成的(和分割槽消費模式一樣);組消費模式由Kafka伺服器端處理各種錯誤,然後將訊息放入佇列再封裝為迭代器(佇列為FetchedDataChunk物件) ,客戶端只需在迭代器上迭代取出訊息;由Kafka伺服器端週期性的通過scheduler提交當前消費的offset,無需客戶端負責
Kafka伺服器端處理消費者負載均衡監控工具Kafka Offset Monitor 和Kafka Manager 均是基於組消費模式;
所以,儘可能使用組消費模式,除非你需要:自己管理offset(比如為了實現訊息投遞的其他語義);自己處理各種錯誤(根據自己業務的需求);
二、Kafka生產者原始碼介紹
1.同步傳送模式原始碼介紹
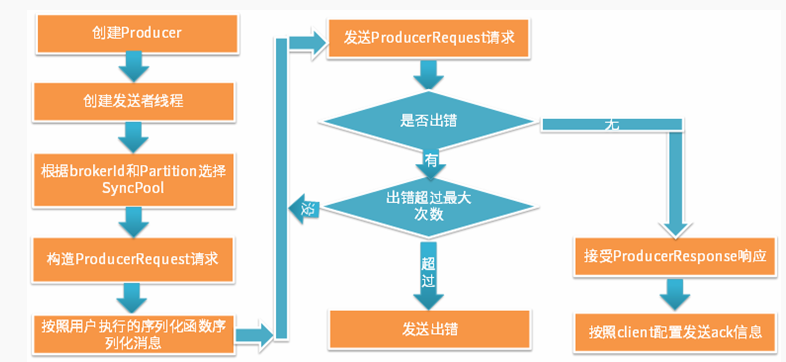
2.非同步傳送模式原始碼介紹
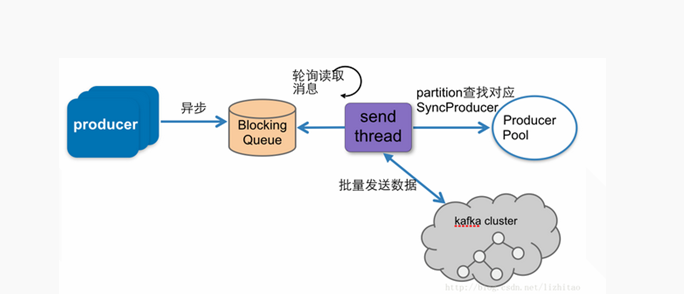
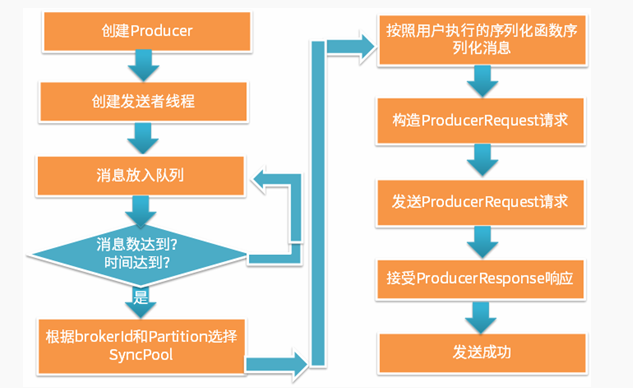
3.兩種生產模式伺服器端原始碼對比
同步傳送模式具有以下特點:同步的向伺服器傳送RPC請求進行生產;傳送錯誤可以重試;可以向客戶端傳送ack;非同步傳送模式具有以下特點:最終也是通過向伺服器傳送RPC請求完成的(和同步傳送模式一樣);非同步傳送模式先將一定量訊息放入佇列中,待達到一定數量後再一起傳送;非同步傳送模式不支援傳送ack,但是Client可以呼叫回撥函式獲取傳送結果;
所以,效能比較高的場景使用非同步傳送,準確性要求高的場景使用同步傳送
三、Kafka Server Reactor設計模型
1.認識Java NIO
Java NIO由以下幾個核心部分組成 :Channels;Buffers;Selectors
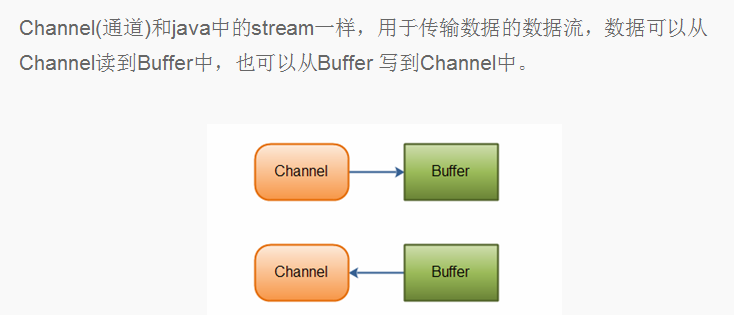
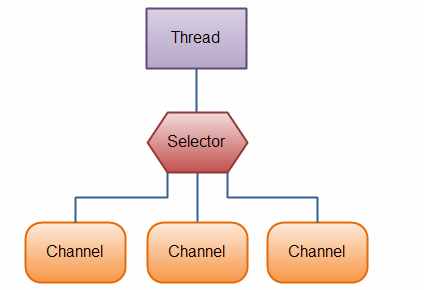
2.認識Linux epoll模型
epoll 是一種IO多路複用技術 ,在linux核心中廣泛使用。常見的三種IO多路複用技術為select模型、poll模型和epoll模型。select 模型需要輪詢所有的套接字檢視是否有事件發生 。缺點: (1)套接字最大支援1024個;(2)主動輪詢效率很低;(3) 事件發生後需要將套接字從核心空間拷貝到使用者空間,效率低poll模型和select模型原理一樣,但是修正了select模型最大套接字限制的缺點;epoll模型修改主動輪詢為被動通知,當有事件發生時,被動接收通知。所以epoll模型註冊套接字後,主程式可以做其他事情,當事件發生時,接收到通知後再去處理。修正了select模型的三個缺點(第三點使用共享記憶體修正)。Java NIO的Selector模型底層使用的就是epoll IO多路複用模型
3.Kafka Server Reactor模型
Kafka SocketServer是基於Java NIO開發的,採用了Reactor的模式(已被大量實踐證明非常高效,在Netty和Mina中廣泛使用)。Kafka Reactor的模式包含三種角色:Acceptor;Processor ;Handler;Kafka Reacator包含了1個Acceptor負責接受客戶端請求,N個Processor執行緒負責讀寫資料(為每個Connection創建出一個Processor去單獨處理,每個Processor中均引用獨立的Selector),M個Handler來處理業務邏輯。在Acceptor和Processor,Processor和Handler之間都有佇列來緩衝請求。
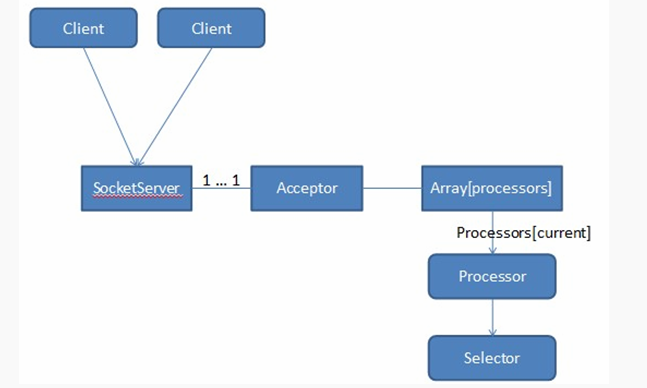
Acceptor的主要職責是監聽客戶端的連線請求,並建立和客戶端的資料傳輸通道,然後為這個客戶端指定一個Processor,它的工作就到此結束,這樣它就可以去響應下一個客戶端的連線請求了;Processor的主要職責是負責從客戶端讀取資料和將響應返回給客戶端,它本身不處理具體的業務邏輯,每個Processor都有一個Selector,用來監聽多個客戶端,因此可以非阻塞地處理多個客戶端的讀寫請求,Processor將資料放入RequestChannel的RequestQueue 中和從ResponseQueue讀取響應 ;Handler(kafka.server.KafkaRequestHandler,kafka.server.KafkaApis)的職責是從RequestChannel中的RequestQueue取出Request,處理以後再將Response新增到RequestChannel中的ResponseQueue中;
四、Kafka Partition Leader選舉機制
1.大資料常用的選主機制
Leader選舉演算法非常多,大資料領域常用的有 以下兩種:Zab(zookeeper使用);Raft;……
它們都是Paxos演算法的變種。
Zab協議有四個階段:Leader election;Discovery(或者epoch establish);Synchronization(或者sync with followers)Broadcast比如3個節點選舉leader,編號為1,2,3。1先啟動,選擇自己為leader,然後2啟動首先也選擇自己為 leader,由於1,2都沒過半,選擇編號大的為leader,所以1,2都選擇2為leader,然後3啟動發現1,2已經協商好且數量過半,於是3也選擇2為leader,leader選舉結束。
在Raft中,任何時候一個伺服器可以扮演下面角色之一Leader: 處理所有客戶端互動,日誌複製等,一般只有一個Leader;Follower: 類似選民,完全被動Candidate候選人: 可以被選為一個新的領導人
啟動時在叢集中指定一些機器為Candidate ,然後Candidate開始向其他機器(尤其是Follower)拉票,當某一個Candidate的票數超過半數,它就成為leader。
2.常用選主機制的缺點
由於Kafka叢集依賴zookeeper叢集,所以最簡單最直觀的方案是,所有Follower都在ZooKeeper上設定一個Watch,一旦Leader宕機,其對應的ephemeral znode會自動刪除,此時所有Follower都嘗試建立該節點,而建立成功者(ZooKeeper保證只有一個能建立成功)即是新的Leader,其它Replica即為Follower。
前面的方案有以下缺點:split-brain (腦裂): 這是由ZooKeeper的特性引起的,雖然ZooKeeper能保證所有Watch按順序觸發,但並不能保證同一時刻所有Replica“看”到的狀態是一樣的,這就可能造成不同Replica的響應不一致 ;herd effect (羊群效應): 如果宕機的那個Broker上的Partition比較多,會造成多個Watch被觸發,造成叢集內大量的調整;ZooKeeper負載過重 : 每個Replica都要為此在ZooKeeper上註冊一個Watch,當叢集規模增加到幾千個Partition時ZooKeeper負載會過重
3.Kafka Partition選主機制
Kafka 的Leader Election方案解決了上述問題,它在所有broker中選出一個controller,所有Partition的Leader選舉都由controller決定。controller會將Leader的改變直接通過RPC的方式(比ZooKeeper Queue的方式更高效)通知需為此作為響應的Broker。Kafka 叢集controller的選舉過程如下 :每個Broker都會在Controller Path (/controller)上註冊一個Watch。當前Controller失敗時,對應的Controller Path會自動消失(因為它是ephemeral Node),此時該Watch被fire,所有“活”著的Broker都會去競選成為新的Controller(建立新的Controller Path),但是隻會有一個競選成功(這點由Zookeeper保證)。競選成功者即為新的Leader,競選失敗者則重新在新的Controller Path上註冊Watch。因為Zookeeper的Watch是一次性的,被fire一次之後即失效,所以需要重新註冊。
Kafka partition leader的選舉過程如下 (由controller執行):從Zookeeper中讀取當前分割槽的所有ISR(in-sync replicas)集合呼叫配置的分割槽選擇演算法選擇分割槽的leader

所以,對於下圖partition 0先選擇broker 2,之後選擇broker 0作為leader;對於partition 1 先選擇broker 0,之後選擇broker 1作為leader;partition 2先選擇broker 1,之後選擇broker 2作為leader。
