C++11常用特性的使用經驗總結
概述及目錄(原創部落格,版權所有,轉載請註明出處 http://www.cnblogs.com/feng-sc)
C++11已經出來很久了,網上也早有很多優秀的C++11新特性的總結文章,在編寫本部落格之前,博主在工作和學習中學到的關於C++11方面的知識,也得益於很多其他網友的總結。本部落格文章是在學習的基礎上,加上博主在日常工作中的使用C++11的一些總結、經驗和感悟,整理出來,分享給大家,希望對各位讀者有幫助,文章中的總結可能存在很多不完整或有錯誤的地方,也希望讀者指出。大家可以根據如下目錄跳到自己需要的章節。
1、關鍵字及新語法
C++11相比C++98增加了許多關鍵字及新的語法特性,很多人覺得這些語法可有可無,沒有新特性也可以用傳統C++去實現。
也許吧,但個人對待新技術總是抱著渴望而熱衷的態度對待,也許正如很多人所想,用傳統語法也可以實現,但新技術可以讓你的設計更完美。這就如同在原來的維度裡,你要完成一件事情,需要很多個複雜的步驟,但在新語法特性裡,你可以從另外的維度,很乾脆,直接就把原來很複雜的問題用很簡單的方法解決了,我想著就是新的技術帶來的一些程式設計體驗上非常好的感覺。大家也不要覺得程式碼寫得越複雜就先顯得越牛B,有時候在理解的基礎上,儘量選擇“站在巨人的肩膀上”,可能你會站得更高,也看得更遠。
本章重點總結一些常用c++11新語法特點。後續會在本人理解的基礎上,會繼續在本部落格內更新或增加新的小章節。
1.1、auto關鍵字及用法
A、auto關鍵字能做什麼?
auto並沒有讓C++成為弱型別語言,也沒有弱化變數什麼,只是使用auto的時候,編譯器根據上下文情況,確定auto變數的真正型別。

//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
auto AddTest(int a, int b)
{
return a + b;
}
int main()
{
auto index = 10;
auto str = "abc";
auto ret = AddTest(1,2);
std::cout << "index:" << index << std::endl;
std::cout << "str:" << str << std::endl;
std::cout << "res:" << ret << std::endl;
}
是的,你沒看錯,程式碼也沒錯,auto在C++14中可以作為函式的返回值,因此auto AddTest(int a, int b)的定義是沒問題的。
執行結果:

B、auto不能做什麼?
auto作為函式返回值時,只能用於定義函式,不能用於宣告函式。
//Test.h 示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#pragma once
class Test
{
public:
auto TestWork(int a ,int b);
};
如下函式中,在引用標頭檔案的呼叫TestWork函式是,編譯無法通過。
但如果把實現寫在標頭檔案中,可以編譯通過,因為編譯器可以根據函式實現的返回值確定auto的真實型別。如果讀者用過inline類成員函式,這個應該很容易明白,此特性與inline類成員函式類似。
//Test.h 示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#pragma once
class Test
{
public:
auto TestWork(int a, int b)
{
return a + b;
}
};
1.2、nullptr關鍵字及用法
為什麼需要nullptr? NULL有什麼毛病?
我們通過下面一個小小的例子來發現NULL的一點問題:
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
class Test
{
public:
void TestWork(int index)
{
std::cout << "TestWork 1" << std::endl;
}
void TestWork(int * index)
{
std::cout << "TestWork 2" << std::endl;
}
};
int main()
{
Test test;
test.TestWork(NULL);
test.TestWork(nullptr);
}
執行結果:

NULL在c++裡表示空指標,看到問題了吧,我們呼叫test.TestWork(NULL),其實期望是呼叫的是void TestWork(int * index),但結果呼叫了void TestWork(int index)。但使用nullptr的時候,我們能呼叫到正確的函式。
1.3、for迴圈語法
習慣C#或java的同事之前使用C++的時候曾吐槽C++ for迴圈沒有想C#那樣foreach的用法,是的,在C++11之前,標準C++是無法做到的。熟悉boost庫讀者可能知道boost裡面有foreach的巨集定義BOOST_FOREACH,但個人覺得看起並不是那麼美觀。
OK,我們直接以簡單示例看看用法吧。
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
int main()
{
int numbers[] = { 1,2,3,4,5 };
std::cout << "numbers:" << std::endl;
for (auto number : numbers)
{
std::cout << number << std::endl;
}
}
以上用法不僅僅侷限於資料,STL容器都同樣適用。
2、STL容器
C++11在STL容器方面也有所增加,給人的感覺就是越來越完整,越來越豐富的感覺,可以讓我們在不同場景下能選擇跟具合適的容器,提高我們的效率。
本章節總結C++11新增的一些容器,以及對其實現做一些簡單的解釋。
2.1、std::array
個人覺得std::array跟陣列並沒有太大區別,對於多維資料使用std::array,個人反而有些不是很習慣吧。
std::array相對於陣列,增加了迭代器等函式(介面定義可參考C++官方文件)。
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <array>
int main()
{
std::array<int, 4> arrayDemo = { 1,2,3,4 };
std::cout << "arrayDemo:" << std::endl;
for (auto itor : arrayDemo)
{
std::cout << itor << std::endl;
}
int arrayDemoSize = sizeof(arrayDemo);
std::cout << "arrayDemo size:" << arrayDemoSize << std::endl;
return 0;
}
執行結果:

打印出來的size和直接使用陣列定義結果是一樣的。
2.2、std::forward_list
std::forward_list為從++新增的線性表,與list區別在於它是單向連結串列。我們在學習資料結構的時候都知道,連結串列在對資料進行插入和刪除是比順序儲存的線性表有優勢,因此在插入和刪除操作頻繁的應用場景中,使用list和forward_list比使用array、vector和deque效率要高很多。
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <forward_list>
int main()
{
std::forward_list<int> numbers = {1,2,3,4,5,4,4};
std::cout << "numbers:" << std::endl;
for (auto number : numbers)
{
std::cout << number << std::endl;
}
numbers.remove(4);
std::cout << "numbers after remove:" << std::endl;
for (auto number : numbers)
{
std::cout << number << std::endl;
}
return 0;
}
執行結果:

2.3、std::unordered_map
std::unordered_map與std::map用法基本差不多,但STL在內部實現上有很大不同,std::map使用的資料結構為二叉樹,而std::unordered_map內部是雜湊表的實現方式,雜湊map理論上查詢效率為O(1)。但在儲存效率上,雜湊map需要增加雜湊表的記憶體開銷。
下面程式碼為C++官網例項原始碼例項:
//webset address: http://www.cplusplus.com/reference/unordered_map/unordered_map/bucket_count/
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
std::unordered_map<std::string, std::string> mymap =
{
{ "house","maison" },
{ "apple","pomme" },
{ "tree","arbre" },
{ "book","livre" },
{ "door","porte" },
{ "grapefruit","pamplemousse" }
};
unsigned n = mymap.bucket_count();
std::cout << "mymap has " << n << " buckets.\n";
for (unsigned i = 0; i<n; ++i)
{
std::cout << "bucket #" << i << " contains: ";
for (auto it = mymap.begin(i); it != mymap.end(i); ++it)
std::cout << "[" << it->first << ":" << it->second << "] ";
std::cout << "\n";
}
return 0;
}
執行結果:

執行結果與官網給出的結果不一樣。實驗證明,不同編譯器編譯出來的結果不一樣,如下為linux下gcc 4.6.3版本編譯出來的結果。或許是因為使用的雜湊演算法不一樣,個人沒有深究此問題。

2.4、std::unordered_set
std::unordered_set的資料儲存結構也是雜湊表的方式結構,除此之外,std::unordered_set在插入時不會自動排序,這都是std::set表現不同的地方。
我們來測試一下下面的程式碼:
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <iostream>
#include <string>
#include <unordered_set>
#include <set>
int main()
{
std::unordered_set<int> unorder_set;
unorder_set.insert(7);
unorder_set.insert(5);
unorder_set.insert(3);
unorder_set.insert(4);
unorder_set.insert(6);
std::cout << "unorder_set:" << std::endl;
for (auto itor : unorder_set)
{
std::cout << itor << std::endl;
}
std::set<int> set;
set.insert(7);
set.insert(5);
set.insert(3);
set.insert(4);
set.insert(6);
std::cout << "set:" << std::endl;
for (auto itor : set)
{
std::cout << itor << std::endl;
}
}
執行結果:

3、多執行緒
在C++11以前,C++的多執行緒程式設計均需依賴系統或第三方介面實現,一定程度上影響了程式碼的移植性。C++11中,引入了boost庫中的多執行緒部分內容,形成C++標準,形成標準後的boost多執行緒程式設計部分介面基本沒有變化,這樣方便了以前使用boost介面開發的使用者切換使用C++標準介面,把容易把boost介面升級為C++介面。
我們通過如下幾部分介紹C++11多執行緒方面的介面及使用方法。
3.1、std::thread
std::thread為C++11的執行緒類,使用方法和boost介面一樣,非常方便,同時,C++11的std::thread解決了boost::thread中構成引數限制的問題,我想著都是得益於C++11的可變引數的設計風格。
我們通過如下程式碼熟悉下std::thread使用風格。
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <thread>
void threadfun1()
{
std::cout << "threadfun1 - 1\r\n" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "threadfun1 - 2" << std::endl;
}
void threadfun2(int iParam, std::string sParam)
{
std::cout << "threadfun2 - 1" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(5));
std::cout << "threadfun2 - 2" << std::endl;
}
int main()
{
std::thread t1(threadfun1);
std::thread t2(threadfun2, 10, "abc");
t1.join();
std::cout << "join" << std::endl;
t2.detach();
std::cout << "detach" << std::endl;
}
執行結果:

有以上輸出結果可以得知,t1.join()會等待t1執行緒退出後才繼續往下執行,t2.detach()並不會並不會把,detach字元輸出後,主函式退出,threadfun2還未執行完成,但是在主執行緒退出後,t2的執行緒也被已經被強退出。
3.2、std::atomic
std::atomic為C++11分裝的原子資料型別。
什麼是原子資料型別?
從功能上看,簡單地說,原子資料型別不會發生資料競爭,能直接用在多執行緒中而不必我們使用者對其進行新增互斥資源鎖的型別。從實現上,大家可以理解為這些原子型別內部自己加了鎖。
我們下面通過一個測試例子說明原子型別std::atomic_int的特點。
下面例子中,我們使用10個執行緒,把std::atomic_int型別的變數iCount從100減到1。
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <thread>
#include <atomic>
#include <stdio.h>
std::atomic_bool bIsReady = false;
std::atomic_int iCount = 100;
void threadfun1()
{
if (!bIsReady) {
std::this_thread::yield();
}
while (iCount > 0)
{
printf("iCount:%d\r\n", iCount--);
}
}
int main()
{
std::atomic_bool b;
std::list<std::thread> lstThread;
for (int i = 0; i < 10; ++i)
{
lstThread.push_back(std::thread(threadfun1));
}
for (auto& th : lstThread)
{
th.join();
}
}
執行結果:

注:螢幕太短的原因,上面結果沒有截完屏
從上面的結果可以看到,iCount的最小結果都是1,單可能不是最後一次列印,沒有小於等於0的情況,大家可以程式碼複製下來多執行幾遍對比看看。
3.3、std::condition_variable
C++11中的std::condition_variable就像Linux下使用pthread_cond_wait和pthread_cond_signal一樣,可以讓執行緒休眠,直到別喚醒,現在在從新執行。執行緒等待在多執行緒程式設計中使用非常頻繁,經常需要等待一些非同步執行的條件的返回結果。
OK,在此不多解釋,下面我們通過C++11官網的例子看看。
1 // webset address: http://www.cplusplus.com/reference/condition_variable/condition_variable/%20condition_variable
2 // condition_variable example
3 #include <iostream> // std::cout
4 #include <thread> // std::thread
5 #include <mutex> // std::mutex, std::unique_lock
6 #include <condition_variable> // std::condition_variable
7
8 std::mutex mtx;
9 std::condition_variable cv;
10 bool ready = false;
11
12 void print_id(int id) {
13 std::unique_lock<std::mutex> lck(mtx);
14 while (!ready) cv.wait(lck);
15 // ...
16 std::cout << "thread " << id << '\n';
17 }
18
19 void go() {
20 std::unique_lock<std::mutex> lck(mtx);
21 ready = true;
22 cv.notify_all();
23 }
24
25 int main()
26 {
27 std::thread threads[10];
28 // spawn 10 threads:
29 for (int i = 0; i<10; ++i)
30 threads[i] = std::thread(print_id, i);
31
32 std::cout << "10 threads ready to race...\n";
33 go(); // go!
34
35 for (auto& th : threads) th.join();
36
37 return 0;
38 }
執行結果:

上面的程式碼,在14行中呼叫cv.wait(lck)的時候,執行緒將進入休眠,在呼叫33行的go函式之前,10個執行緒都處於休眠狀態,當22行的cv.notify_all()執行後,14行的休眠將結束,繼續往下執行,最終輸出如上結果。
4、智慧指標記憶體管理
在記憶體管理方面,C++11的std::auto_ptr基礎上,移植了boost庫中的智慧指標的部分實現,如std::shared_ptr、std::weak_ptr等,當然,想boost::thread一樣,C++11也修復了boost::make_shared中構造引數的限制問題。把智慧指標新增為標準,個人覺得真的非常方便,畢竟在C++中,智慧指標在程式設計設計中使用的還是非常廣泛。
什麼是智慧指標?網上已經有很多解釋,個人覺得“智慧指標”這個名詞似乎起得過於“霸氣”,很多初學者看到這個名詞就覺得似乎很難。
簡單地說,智慧指標只是用物件去管理一個資源指標,同時用一個計數器計算當前指標引用物件的個數,當管理指標的物件增加或減少時,計數器也相應加1或減1,當最後一個指標管理物件銷燬時,計數器為1,此時在銷燬指標管理物件的同時,也把指標管理物件所管理的指標進行delete操作。
如下圖所示,簡單話了一下指標、智慧指標物件和計數器之間的關係:

下面的小章節中,我們分別介紹常用的兩個智慧指標std::shared_ptr、std::weak_ptr的用法。
4.1、std::shared_ptr
std::shared_ptr包裝了new操作符動態分別的記憶體,可以自由拷貝複製,基本上是使用最多的一個智慧指標型別。
我們通過下面例子來了解下std::shared_ptr的用法:
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <memory>
class Test
{
public:
Test()
{
std::cout << "Test()" << std::endl;
}
~Test()
{
std::cout << "~Test()" << std::endl;
}
};
int main()
{
std::shared_ptr<Test> p1 = std::make_shared<Test>();
std::cout << "1 ref:" << p1.use_count() << std::endl;
{
std::shared_ptr<Test> p2 = p1;
std::cout << "2 ref:" << p1.use_count() << std::endl;
}
std::cout << "3 ref:" << p1.use_count() << std::endl;
return 0;
}
執行結果:

從上面程式碼的執行結果,需要讀者瞭解的是:
1、std::make_shared封裝了new方法,boost::make_shared之前的原則是既然釋放資源delete由智慧指標負責,那麼應該把new封裝起來,否則會讓人覺得自己呼叫了new,但沒有呼叫delete,似乎與誰申請,誰釋放的原則不符。C++也沿用了這一做法。
2、隨著引用物件的增加std::shared_ptr<Test> p2 = p1,指標的引用計數有1變為2,當p2退出作用域後,p1的引用計數變回1,當main函式退出後,p1離開main函式的作用域,此時p1被銷燬,當p1銷燬時,檢測到引用計數已經為1,就會在p1的解構函式中呼叫delete之前std::make_shared建立的指標。
4.2、std::weak_ptr
std::weak_ptr網上很多人說其實是為了解決std::shared_ptr在相互引用的情況下出現的問題而存在的,C++官網對這個只能指標的解釋也不多,那就先甭管那麼多了,讓我們暫時完全接受這個觀點。
std::weak_ptr有什麼特點呢?與std::shared_ptr最大的差別是在賦值是,不會引起智慧指標計數增加。
我們下面將繼續如下兩點:
1、std::shared_ptr相互引用會有什麼後果;
2、std::weak_ptr如何解決第一點的問題。
A、std::shared_ptr相互引用的問題示例:
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <memory>
class TestB;
class TestA
{
public:
TestA()
{
std::cout << "TestA()" << std::endl;
}
void ReferTestB(std::shared_ptr<TestB> test_ptr)
{
m_TestB_Ptr = test_ptr;
}
~TestA()
{
std::cout << "~TestA()" << std::endl;
}
private:
std::shared_ptr<TestB> m_TestB_Ptr; //TestB的智慧指標
};
class TestB
{
public:
TestB()
{
std::cout << "TestB()" << std::endl;
}
void ReferTestB(std::shared_ptr<TestA> test_ptr)
{
m_TestA_Ptr = test_ptr;
}
~TestB()
{
std::cout << "~TestB()" << std::endl;
}
std::shared_ptr<TestA> m_TestA_Ptr; //TestA的智慧指標
};
int main()
{
std::shared_ptr<TestA> ptr_a = std::make_shared<TestA>();
std::shared_ptr<TestB> ptr_b = std::make_shared<TestB>();
ptr_a->ReferTestB(ptr_b);
ptr_b->ReferTestB(ptr_a);
return 0;
}
執行結果:

大家可以看到,上面程式碼中,我們建立了一個TestA和一個TestB的物件,但在整個main函式都執行完後,都沒看到兩個物件被析構,這是什麼問題呢?
原來,智慧指標ptr_a中引用了ptr_b,同樣ptr_b中也引用了ptr_a,在main函式退出前,ptr_a和ptr_b的引用計數均為2,退出main函式後,引用計數均變為1,也就是相互引用。
這等效於說:
ptr_a對ptr_b說,哎,我說ptr_b,我現在的條件是,你先釋放我,我才能釋放你,這是天生的,造物者決定的,改不了。
ptr_b也對ptr_a說,我的條件也是一樣,你先釋放我,我才能釋放你,怎麼辦?
是吧,大家都沒錯,相互引用導致的問題就是釋放條件的衝突,最終也可能導致記憶體洩漏。
B、std::weak_ptr如何解決相互引用的問題
我們在上面的程式碼基礎上使用std::weak_ptr進行修改:
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <memory>
class TestB;
class TestA
{
public:
TestA()
{
std::cout << "TestA()" << std::endl;
}
void ReferTestB(std::shared_ptr<TestB> test_ptr)
{
m_TestB_Ptr = test_ptr;
}
void TestWork()
{
std::cout << "~TestA::TestWork()" << std::endl;
}
~TestA()
{
std::cout << "~TestA()" << std::endl;
}
private:
std::weak_ptr<TestB> m_TestB_Ptr;
};
class TestB
{
public:
TestB()
{
std::cout << "TestB()" << std::endl;
}
void ReferTestB(std::shared_ptr<TestA> test_ptr)
{
m_TestA_Ptr = test_ptr;
}
void TestWork()
{
std::cout << "~TestB::TestWork()" << std::endl;
}
~TestB()
{
std::shared_ptr<TestA> tmp = m_TestA_Ptr.lock();
tmp->TestWork();
std::cout << "2 ref a:" << tmp.use_count() << std::endl;
std::cout << "~TestB()" << std::endl;
}
std::weak_ptr<TestA> m_TestA_Ptr;
};
int main()
{
std::shared_ptr<TestA> ptr_a = std::make_shared<TestA>();
std::shared_ptr<TestB> ptr_b = std::make_shared<TestB>();
ptr_a->ReferTestB(ptr_b);
ptr_b->ReferTestB(ptr_a);
std::cout << "1 ref a:" << ptr_a.use_count() << std::endl;
std::cout << "1 ref b:" << ptr_a.use_count() << std::endl;
return 0;
}
執行結果:

由以上程式碼執行結果我們可以看到:
1、所有的物件最後都能正常釋放,不會存在上一個例子中的記憶體沒有釋放的問題。
2、ptr_a 和ptr_b在main函式中退出前,引用計數均為1,也就是說,在TestA和TestB中對std::weak_ptr的相互引用,不會導致計數的增加。在TestB解構函式中,呼叫std::shared_ptr<TestA> tmp = m_TestA_Ptr.lock(),把std::weak_ptr型別轉換成std::shared_ptr型別,然後對TestA物件進行呼叫。
5、其他
本章節介紹的內容如果按照分類來看,也屬於以上語法類別,但感覺還是單獨拿出來總結好些。
下面小節主要介紹std::function、std::bind和lamda表示式的一些特點和用法,希望對讀者能有所幫助。
5.1、std::function、std::bind封裝可執行物件
std::bind和std::function也是從boost中移植進來的C++新標準,這兩個語法使得封裝可執行物件變得簡單而易用。此外,std::bind和std::function也可以結合我們一下所說的lamda表示式一起使用,使得可執行物件的寫法更加“花俏”。
我們下面通過例項一步步瞭解std::function和std::bind的用法:
Test.h檔案
//Test.h 示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
class Test
{
public:
void Add()
{
}
};
main.cpp檔案
//main.cpp 示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
#include <functional>
#include <iostream>
#include "Test.h"
int add(int a,int b)
{
return a + b;
}
int main()
{
Test test;
test.Add();
return 0;
}
解釋:
上面程式碼中,我們實現了一個add函式和一個Test類,Test類裡面有一個Test函式也有一個函式Add。
OK,我們現在來考慮一下這個問題,假如我們的需求是讓Test裡面的Add由外部實現,如main.cpp裡面的add函式,有什麼方法呢?
沒錯,我們可以用函式指標。
我們修改Test.h
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
class Test
{
public:
typedef int(*FunType)(int, int);
void Add(FunType fun,int a,int b)
{
int sum = fun(a, b);
std::cout << "sum:" << sum << std::endl;
}
};
修改main.cpp的呼叫
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html .... .... Test test; test.Add(add, 1, 2); ....
執行結果:

到現在為止,完美了嗎?如果你是Test.h的提供者,你覺得有什麼問題?
我們把問題升級,假如add實現是在另外一個類內部,如下程式碼:
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
class TestAdd
{
public:
int Add(int a,int b)
{
return a + b;
}
};
int main()
{
Test test;
//test.Add(add, 1, 2);
return 0;
}
假如add方法在TestAdd類內部,那你的Test類沒轍了,因為Test裡的Test函式只接受函式指標。你可能說,這個不是我的問題啊,我是介面的定義者,使用者應該遵循我的規則。但如果現在我是客戶,我們談一筆生意,就是我要購買使用你的Test類,前提是需要支援我傳入函式指標,也能傳入物件函式,你做不做這筆生意?
是的,你可以選擇不做這筆生意。我們現在再假設你已經好幾個月沒吃肉了(別跟我說你是素食主義者),身邊的蒼蠅肉、蚊子肉啊都不被你吃光了,好不容易等到有機會吃肉,那有什麼辦法呢?
這個時候std::function和std::bind就幫上忙了。
我們繼續修改程式碼:
Test.h
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
class Test
{
public:
void Add(std::function<int(int, int)> fun, int a, int b)
{
int sum = fun(a, b);
std::cout << "sum:" << sum << std::endl;
}
};
解釋:
Test類中std::function<int(int,int)>表示std::function封裝的可執行物件返回值和兩個引數均為int型別。
main.cpp
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
int add(int a,int b)
{
std::cout << "add" << std::endl;
return a + b;
}
class TestAdd
{
public:
int Add(int a,int b)
{
std::cout << "TestAdd::Add" << std::endl;
return a + b;
}
};
int main()
{
Test test;
test.Add(add, 1, 2);
TestAdd testAdd;
test.Add(std::bind(&TestAdd::Add, testAdd, std::placeholders::_1, std::placeholders::_2), 1, 2);
return 0;
}
解釋:
std::bind第一個引數為物件函式指標,表示函式相對於類的首地址的偏移量;
testAdd為物件指標;
std::placeholders::_1和std::placeholders::_2為引數佔位符,表示std::bind封裝的可執行物件可以接受兩個引數。
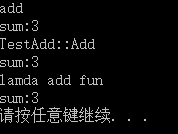
執行結果:

是的,得出這個結果,你就可以等著吃肉了,我們的Test函式在函式指標和類物件函式中都兩種情況下都完美執行。
5.2、lamda表示式
在眾多的C++11新特性中,個人覺得lamda表示式不僅僅是一個語法新特性,對於沒有用過java或C#lamda表示式讀者,C++11的lamda表示式在一定程度上還衝擊著你對傳統C++程式設計的思維和想法。
我們先從一個簡單的例子來看看lamda表示式:
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
1 int main()
2 {
3 auto add= [](int a, int b)->int{
4 return a + b;
5 };
6 int ret = add(1,2);
7 std::cout << "ret:" << ret << std::endl;
8 return 0;
9 }
解釋:
第3至5行為lamda表示式的定義部分
[]:中括號用於控制main函式與內,lamda表示式之前的變數在lamda表示式中的訪問形式;
(int a,int b):為函式的形參
->int:lamda表示式函式的返回值定義
{}:大括號內為lamda表示式的函式體。
執行結果:

我使用lamda表示式修改5.1中的例子看看:
main.cpp
//示例程式碼1.0 http://www.cnblogs.com/feng-sc/p/5710724.html
.....
int main()
{
Test test;
test.Add(add, 1, 2);
TestAdd testAdd;
test.Add(std::bind(&TestAdd::Add, testAdd, std::placeholders::_1, std::placeholders::_2), 1, 2);
test.Add([](int a, int b)->int {
std::cout << "lamda add fun" << std::endl;
return a + b;
},1,2);
return 0;
}
執行結果: