
深度學習-54:生成式對抗網路GAN(原理、模型和演進)
深度學習-52:生成式對抗網路GAN(原理、模型和演進)
一般的學習模型都是基於一個假設的隨機分佈,然後通過訓練真實資料來擬合出模型。網路模型複雜並且資料集規模也不小,這種方法簡直就是憑藉天生蠻力解決問題。Goodfellow認為正確使用資料的方式,先對資料集的特徵資訊有insight之後,再幹活。在2014年,Goodfellow等提出生成式對抗網路GAN(Generative adversarial networks)。
GAN網路由一個生成器和一個判別器構成。生成器和判別器使用多層感知機。GAN網路的架構,如下圖所示。
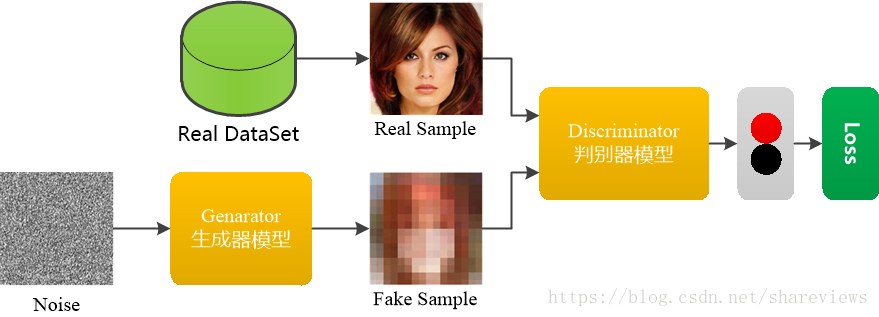
1 GAN模型的創新
GAN模型時通過對抗過程來估計生成模型的新框架。在GAN模型框架中,生成模型與判別模型進行非合作零和博弈。生成模型可以被認為類似於造假者團隊,試圖生產虛假貨幣並在沒有檢測的情況下使用它,而判別模型則是類似於警察,試圖檢測假幣。這場比賽中的比賽開始了兩個團隊都在改進他們的方法,直到偽造品與真品無法區分用品。
GAN模型的的主要創新:
- 擁有生成網路G和辨別網路D,生成模型G的思想是將一個噪聲包裝成一個逼真的樣本,判別模型D則需要判斷送入的樣本是真實的還是假的樣本;
- 生成網路G和辨別網路D使用獨立學習模型,辨別模型D對樣本的判別能力不斷上升,生成模型G的造假能力也不斷上升;
- GAN的優化是一個極小極大博弈問題,最終的目的是Generator的輸出Discriminator時很難判斷是真實or偽造的,即極大化的判斷能力,極小化將的輸出判斷為偽造的概率。
2 GAN模型的結構
生成對抗網路(GAN)的結構:
- GAN由一個生成器和一個判別器構成;
- GAN的生成器捕捉真實資料樣本的潛在分佈, 並生成新的資料樣本;
- GAN的判別器是一個二分類器, 判別輸入是真實資料還是生成的樣本;
- GAN的生成器和判別器均可以使用深度學習模型;
- GAN的優化過程是極小極大博弈(Minimax game)問題, 優化目標是達到納什均衡。
2.1 模型構建
生成對抗網路(GAN)基於博弈模型,其中生成模型(Generator)必須與其對手判別模型(Discriminator)競爭。生成模型直接生成假樣本, 判別模型嘗試區分生成器生成的樣本(假樣本)和訓練資料中抽取的樣本(真樣本)。生成對抗網路(GAN)是一種生成模型,由生成器Generator和辨別器Discriminator組成。生成模型(Generator)嘗試瞭解真實資料樣本的特徵分佈, 並生成新的資料樣本。判別模型(Discriminator)一個二分類器, 判別輸入是真實資料還是生成的樣本。生成模型(Generator)和判別模型(Discriminator)均可以使用感知機或者深度學習模型。優化過程是極小極大博弈(Minimax game)問題, 優化目標是達到納什均衡,即直到判別模型(Discriminator)無法識別生成模型(Generator)生成的假樣本是真是假。
2.2 訓練模型
生成對抗網路(GAN)基於博弈模型,由生成器(Generator)和辨別器(Discriminator)組成。生成器(Generator)的假樣本和訓練資料的真樣本輸入到辨別器(Discriminator)。在訓練的過程中,對於真實資料,判別器嘗試向其分配一個接近1的概率(smooth引數將labels設為略小於1的值,如0.9)。生成對抗網路(GAN)使用Tensorlow提供的 tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels)函式可以計算代價。
對於真實資料,我們使用label=1計算代價函式來訓練判別器,其代價函式的計算方法為:
loss = tf.nn.sigmoid_cross_entropy_with_logits
d_loss_real = loss(d_logits_real, labels=tf.ones_like(d_logits_real)*(1-smooth))
對於生成器,我們使用label=0計算代價函式來訓練判別器,其代價函式的計算方法為:
loss = tf.nn.sigmoid_cross_entropy_with_logits
d_loss_fake = loss(d_logits_fake, labels=tf.zeros_like(d_logits_fake))
所以判別器的代價函式為:d_loss = d_loss_real + d_loss_fake
生成器嘗試做相反的事情,它經訓練嘗試輸出能使辨別器分配接近概率1的樣本。生成器的代價函式為
loss = tf.nn.sigmoid_cross_entropy_with_logits
g_loss = loss(d_logits_fake, labels=tf.ones_like(d_logits_fake))
GANs和很多其他模型不同,GANs在訓練時需要同時執行兩個優化演算法,我們需要為discriminator和generator分別定義一個優化器,一個用來來最小化discriminator的損失,另一個用來最小化generator的損失。即loss = d_loss + g_loss
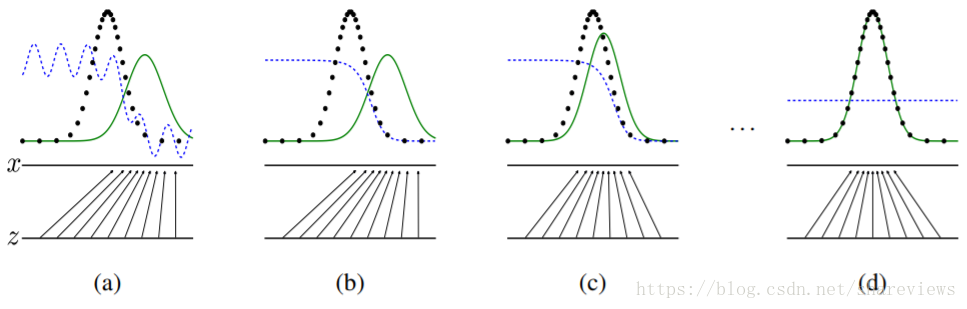
黑色虛線是真實資料的高斯分佈,綠色的線是生成網路學習到的偽造分佈,藍色的線是判別網路判定為真實圖片的概率,標x的橫線代表服從高斯分佈x的取樣空間,標z的橫線代表服從均勻分佈z的取樣空間。從上圖中可以看出,經過多次迭代,可以看出生成模型(Generator)學習了從z的空間到x的空間的對映關係。簡單來說就是生成模型(Generator)和原始資料集的特徵近似相同,訓練工作就結束了,生成模型(Generator)生成的資料已經假假真真不可辨識了。
3 GAN模型的演進
Google論文:Are GANs Created Equal? A Large-Scale Study(Google)。論文中使用了minimax損失函式和用non-saturating損失函式的GAN,分別簡稱為MM GAN和NS GAN,對比了WGAN、WGAN GP、LS GAN、DRAGAN、BEGAN等GAN模型變體,發現效能大同小異。這個結論是選擇困難症的福音呀。
3.1 CGAN
原始GAN不要求一個假設的資料分佈,即不需要formulate p(x),而是使用一種分佈直接進行取樣sampling,從而真正達到理論上可以完全逼近真實資料。為了解決GAN太過自由這個問題,CGAN提出了一種帶條件約束的GAN,在生成模型(G)和判別模型(D)的建模中均引入條件變數y,使用額外資訊y對模型增加條件,可以指導資料生成過程。
3.2 GCGAN
DCGAN是繼GAN之後比較好的改進,提升了GAN訓練的穩定性以及生成結果質量。DCGAN為GAN的訓練提供了一個很好的網路拓撲結構,表明生成的特徵具有向量的計算特性。
3.3 WGAN
WGAN主要從損失函式的角度對GAN做了改進,損失函式改進之後的WGAN即使在全連結層上也能得到很好的表現結果,WGAN對GAN的改進主要有:判別器最後一層去掉sigmoid; 生成器和判別器的loss不取log。
3.4 WGAN-GP
WGAN-GP是WGAN之後的改進版,主要改進了連續性限制的條件。WGAN-GP提出了一種新的lipschitz連續性限制手法—梯度懲罰,解決了訓練梯度消失梯度爆炸的問題;比標準WGAN擁有更快的收斂速度,並能生成更高質量的樣本;提供穩定的GAN訓練方式,幾乎不需要怎麼調參,成功訓練多種針對圖片生成和語言模型的GAN架構。
3.5 LSGAN
常見的GAN模型使用minimax作為損失函式,最小二乘GAN(LSGAN)使用最小二乘損失函式代替了GAN的損失函式。LSGAN模型緩解了GAN訓練不穩定和生成影象質量差多樣性不足的問題。
3.6 BEGAN
BEGAN和其他GAN不一樣,這裡的D使用的是auto-encoder結構,D的輸入是圖片,輸出是經過編碼解碼後的圖片。BEGAN提出了一種新的簡單強大GAN,使用標準的訓練方式,不加訓練trick也能很快且穩定的收斂。