python sklearn包——cross validation筆記
preface:做實驗少不了交叉驗證,平時常用from sklearn.cross_validation import train_test_split,用train_test_split()函式將資料集分為訓練集和測試集,但這樣還不夠。當需要除錯引數的時候便要用到K-fold。scikit給我們提供了函式,我們只需要呼叫即可。
sklearn包中cross validation的介紹:在這裡。其中滷煮對3.1.2. cross validation iterators這一小節比較注意。先做這一小節的筆記,後續再新增。cross_validation函式下的函式如下圖所示。

Figure 1: cross validation下的函式
3.1.2.1. k-fold
將樣例劃分為K份,若K=len(樣例),即為留一交叉驗證,K-1份作為訓練。從sklearn中自帶的KFold函式說明中也可以看到其用法。其中n_folds預設為3折交叉驗證,2/3作為訓練集,1/3作為測試集。

Figure 3-1-2-1-1:KFold用法
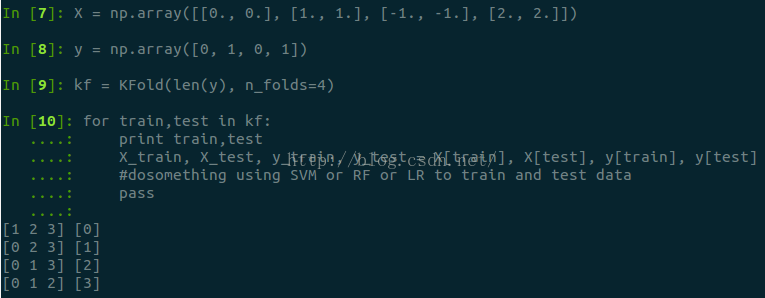
Figure 3-1-2-1-2: KFold使用例子
3.1.2.2. Stratified k-fold
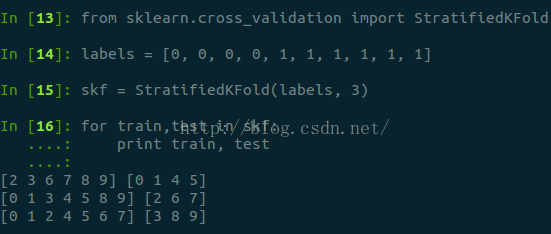
StratifiedKFold()這個函式較常用,比KFold的優勢在於將k折資料按照百分比劃分資料集,每個類別百分比在訓練集和測試集中都是一樣,這樣能保證不會有某個類別的資料在訓練集中而測試集中沒有這種情況,同樣不會在訓練集中沒有全在測試集中,這樣會導致結果糟糕透頂。
Figure 3-1-2-2-1:StratifiedKFold函式使用
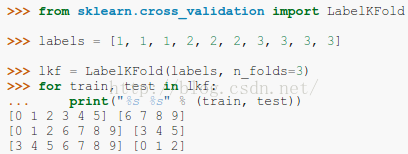
3.1.2.3. Label k-fold
LabelKFold()函式則是根據樣例label來交叉驗證,某個樣例的資料必須是屬於訓練集或者測試集時,可用這個函式。奇怪的是滷煮在sklearn中使用異常,沒有這個函式。。。
Figure 3-1-2-3:LabelKFold()函式使用