
小橙書閱讀指南(十二)——無向圖、深度優先搜尋和路徑查詢演算法
阿新 • • 發佈:2018-12-15
在計算機應用中,我們把一系列相連線的節點組成的資料結構,叫做圖。今天我們將要介紹它的一種形式——無向圖,以及針對這種結構的深度優先搜尋和路徑查詢演算法。
一、無向圖資料結構
介面:
/** * 圖論介面 */ public interface Graph { /** * 頂點數 * * @return */ int vertexNum(); /** * 邊數 * * @return */ int edgeNum(); /** * 向圖中新增一條v-w的邊 * *@param v * @param w */ void addEdge(int v, int w); /** * 和v相鄰的所有頂點 * * @param v * @return */ Iterable<Integer> adjoin(int v); /** * v的維度 * * @param v * @return */ int degree(int v); }
實現類:
public class Graph implementsalgorithms.graphs.ifs.Graph { private final int vertex; // 頂點 private int edge; // 邊 private ArrayList<Integer>[] adj; public Graph(int v) { this.vertex = v; this.edge = 0; adj = (ArrayList<Integer>[]) new ArrayList[v]; for (int i = 0; i < v; i++) { adj[i]= new ArrayList<>(); } } @Override public int vertexNum() { return vertex; } @Override public int edgeNum() { return edge; } @Override public void addEdge(int v, int w) { validateVertex(v); validateVertex(w); adj[v].add(w); adj[w].add(v); edge++; } @Override public Iterable<Integer> adjoin(int v) { return adj[v]; } @Override public int degree(int v) { return adj[v].size(); } private void validateVertex(int v) { if (v < 0 || v > this.vertex) { throw new IllegalArgumentException(); } } }
二、深度搜索優先演算法
對於圖的處理我們常常通過系統地檢查每一個頂點和每一條邊來獲取圖的各種性質。對於圖的問題我們最經常被問及的是:a點和b點連通嗎?如果連通如何到達?為了描述方便,我們使用自然數描述圖的每一個頂點。
假設有以下圖的結構
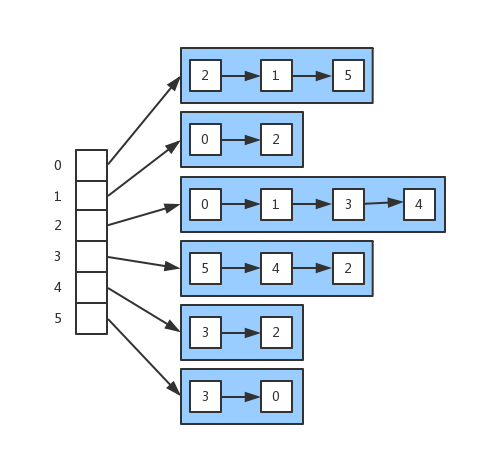
左側陣列表示節點,右側代表與節點連線的其他節點。該結構的標準畫法如下:
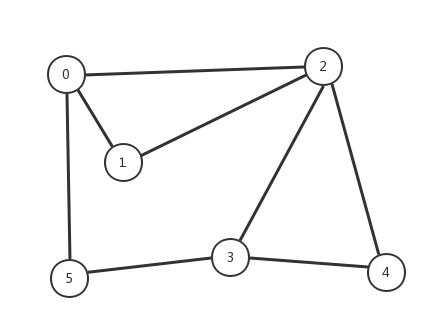
演算法描述:深度優先搜尋從起點出發(0)遍歷(2,1,5)並遞迴(2)與它連結的點,被搜尋到的點將不會被再次遞迴直到所有的點都被搜尋到為止。
深度優先搜尋介面與實現:
// 介面 public interface Search { boolean marked(int v); int count(); } /** * 圖論:深度優先搜尋 */ public class DepthFirstSearch implements Search { private boolean[] marked; private int count; public DepthFirstSearch(Graph g, int s) { marked = new boolean[g.vertexNum()]; validateVertex(s); dfs(g, s); } /** * 以遞迴的方式從s起點出發,標記每一個經過的頂點,未被標記的頂點為不連通 * * @param g * @param v */ private void dfs(Graph g, int v) { marked[v] = true; count++; for (int x : g.adjoin(v)) { if (!marked[x]) { dfs(g, x); } } } @Override public boolean marked(int v) { validateVertex(v); return marked[v]; } @Override public int count() { return count; } // throw an IllegalArgumentException unless {@code 0 <= vertexNum < V} private void validateVertex(int v) { int V = marked.length; if (v < 0 || v >= V) throw new IllegalArgumentException(); } }
這套演算法的核心是dfs函式。我們要理解深度優先演算法就必須弄清楚演算法遞迴的過程。marked陣列記錄節點的訪問情況,變數x和v的遞迴過程如下:
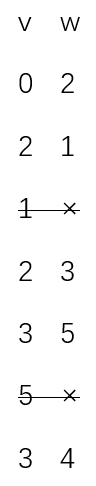
標準畫法:
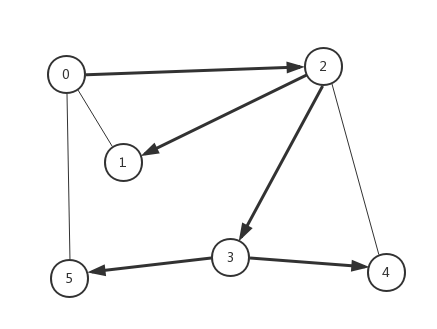
深度優先演算法按照上面的路徑搜尋圖,由此我們可以獲知深度搜索演算法的兩個特徵:
1.搜尋路徑沿一條路徑向下擴充套件,每一個節點只會被遍歷一次(每一個節點都可以知道在搜尋路徑上的上一個節點,並唯一確定)。
2.搜尋路徑上的任意兩點代表可達,但並非最短路徑。
這樣我們就可以回答本文最早提出的有關圖的第一個問題:a點和b點連通嗎?顯然,以a為起點搜尋整個圖,如果b點在路徑上則表示連通。
三、使用深度優先搜尋的路徑演算法
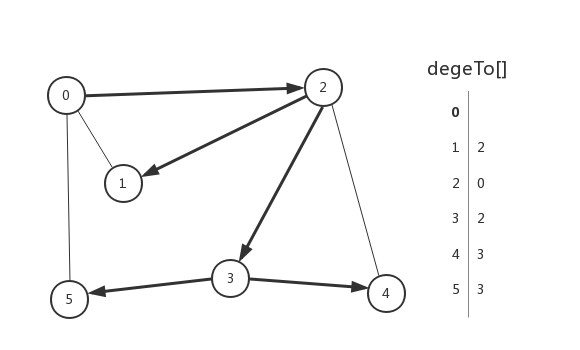
要回答有關圖的第二個問題:如果連通如何到達?回憶上一段我們總結的深度搜索演算法的第一個特徵,我們可以使用陣列結構在儲存每一個節點的上一個節點。
路徑搜尋介面和實現:
/** * 尋找路徑 */ public interface Paths { boolean hasPathTo(int vertex); Iterable<Integer> pathTo(int vertex); } /** * 基於深度優先搜尋的路徑搜尋演算法 */ public class DepthFirstPaths implements Paths { private final int s; private boolean[] marked; private int[] edgeTo; public DepthFirstPaths(Graph g, int s) { this.s = s; marked = new boolean[g.vertexNum()]; edgeTo = new int[g.vertexNum()]; dfs(g, s); } private void dfs(Graph g, int v) { marked[v] = true; for (int w : g.adjoin(v)) { if (!marked[w]) { edgeTo[w] = v; dfs(g, w); } } } @Override public boolean hasPathTo(int vertex) { return marked[vertex]; } @Override public Iterable<Integer> pathTo(int vertex) { if (!hasPathTo(vertex)) { return null; } Stack<Integer> path = new Stack<>(); for (int i = vertex; i != s; i = edgeTo[i]) { path.push(i); } path.push(s); return path; } }
演算法的標準畫法:
相關連結: