
自然語言處理中的Attention機制
Attention in NLP
Advantage:
- integrate information over time
- handle variable-length sequences
- could be parallelized
Seq2seq
Encoder–Decoder framework:
Encoder:
Sutskeveretal.(2014) used an LSTM as f and
Decoder:
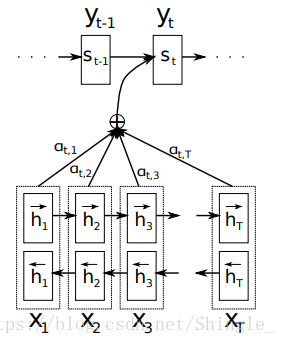
LEARNING TO ALIGN AND TRANSLATE
Decoder:
each conditional probability:
context vector :
in [1], is computed by:
Kinds of attention
Hard and soft attention
hard attention 會專注於很小的區域,而 soft attention 的注意力相對發散
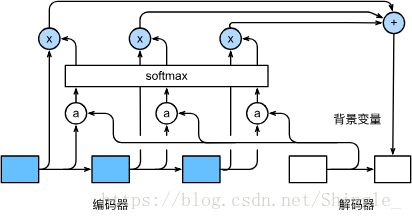
Global and local attention
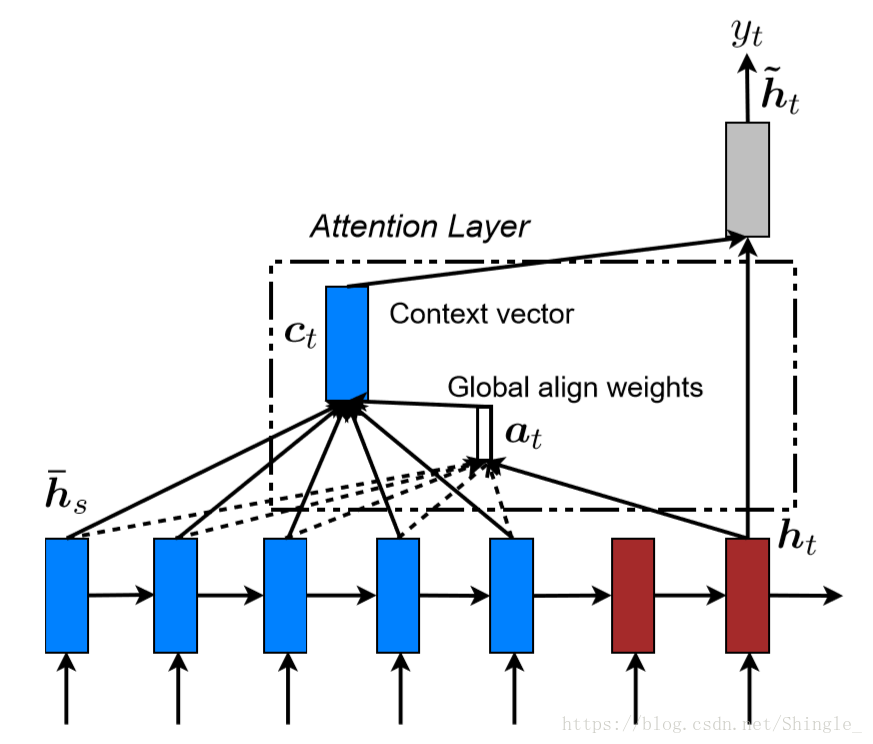
四種alignment function計算方法:
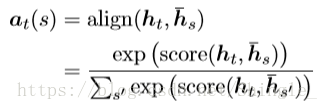
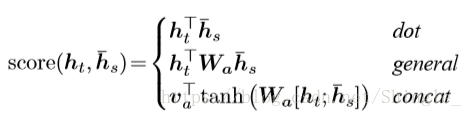
小結:
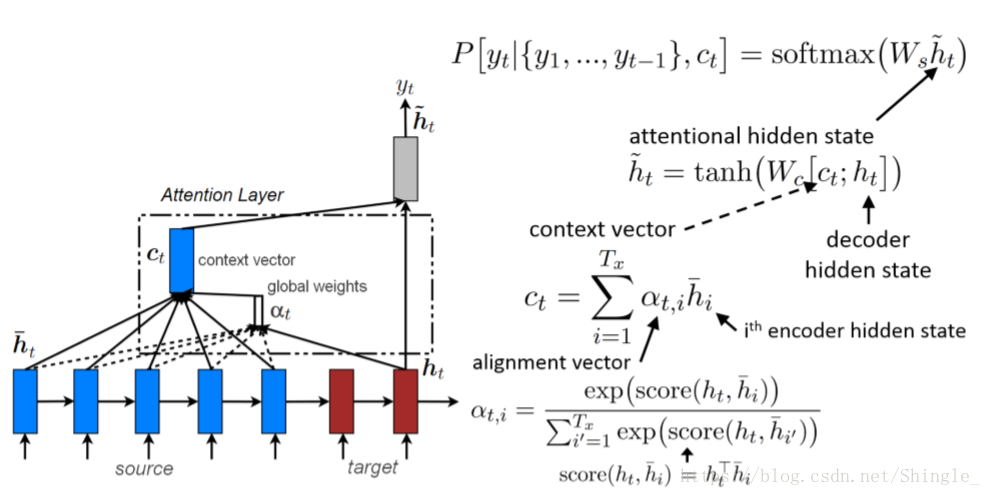
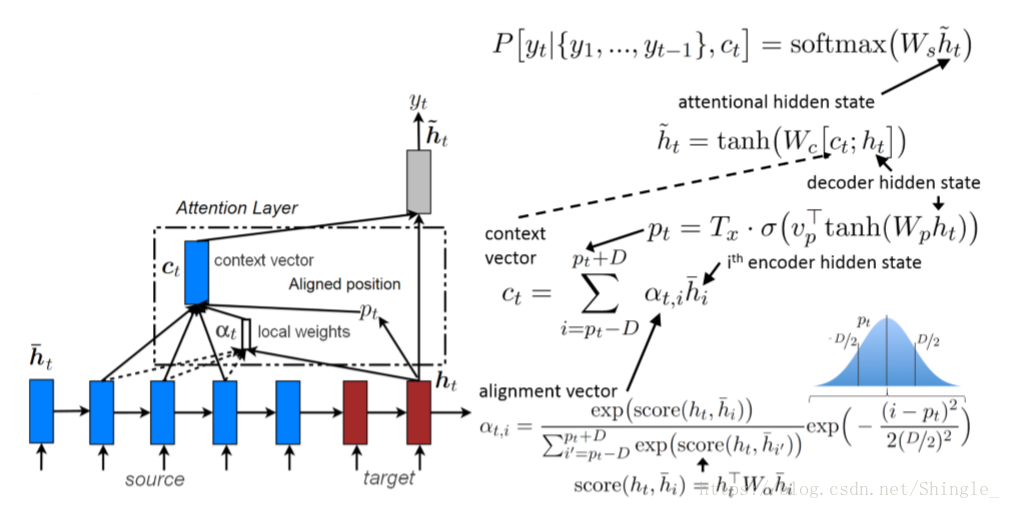
attention in feed-forword NN
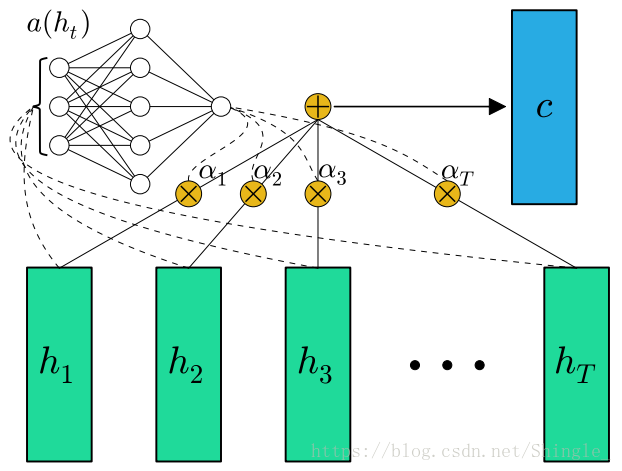
simplified version of attention:
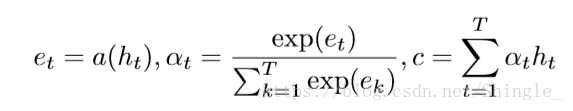
Hierarchical Attention
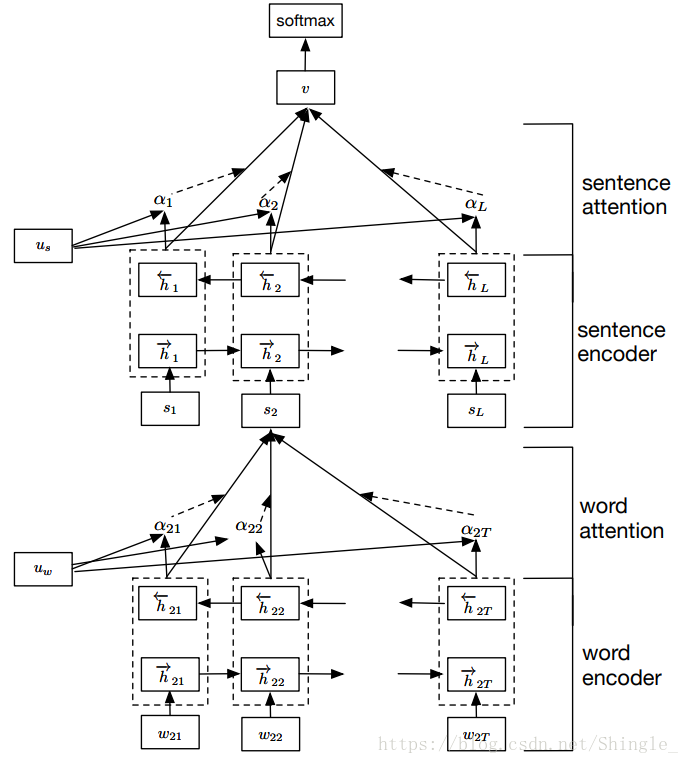
word level attention:
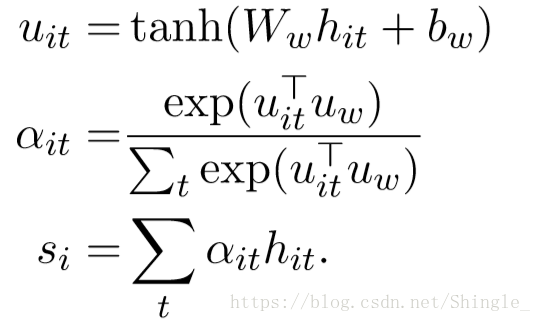
sentence level attention:
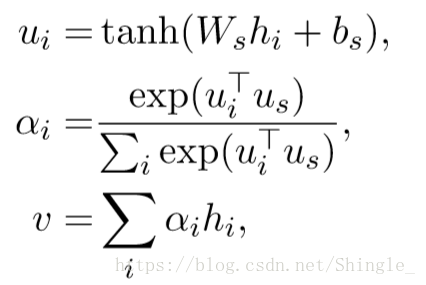
inner attention mechanism:
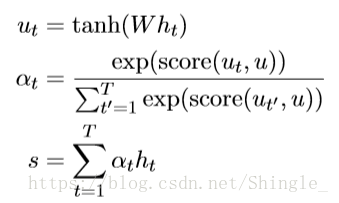
annotation is first passed to a dense layer. An alignment coefficient is then derived by comparing the output of the dense layer with a trainable context vector (initialized randomly) and normalizing with a softmax. The attentional vector is finally obtained as a weighted sum of the annotations.
score can in theory be any alignment function. A straightforward approach is to use dot. The context vector can be interpreted as a representation of the optimal word, on average. When faced with a new example, the model uses this knowledge to decide which word it should pay attention to. During training, through backpropagation, the model updates the context vector, i.e., it adjusts its internal representation of what the optimal word is.
Note: The context vector in the definition of inner-attention above has nothing to do with the context vector used in seq2seq attention!
self-attention
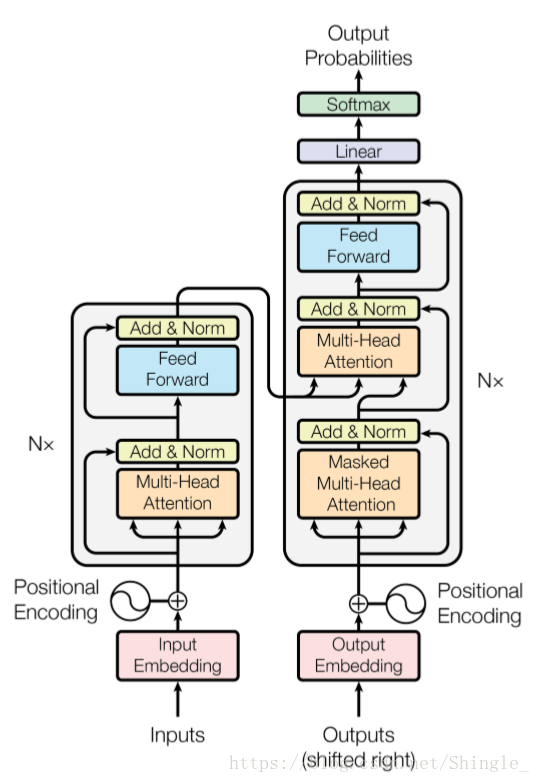
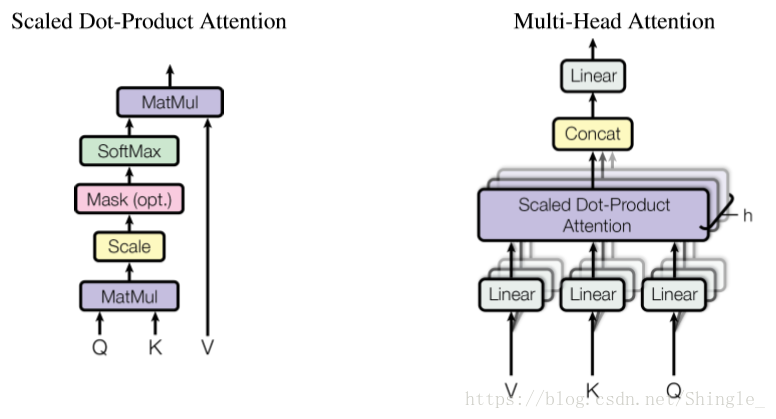
Self-Attention 即 K=V=Q,例如輸入一個句子,那麼裡面的每個詞都要和該句子中的所有詞進行 Attention 計算。目的是學習句子內部的詞依賴關係,捕獲句子的內部結構。
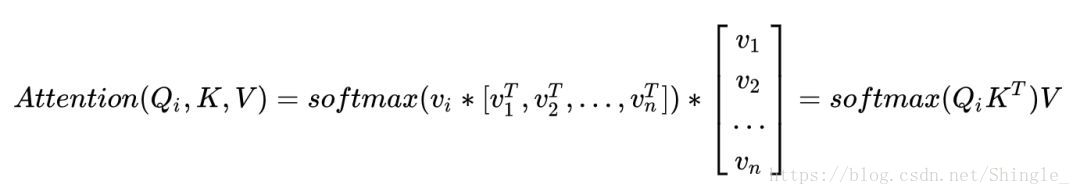
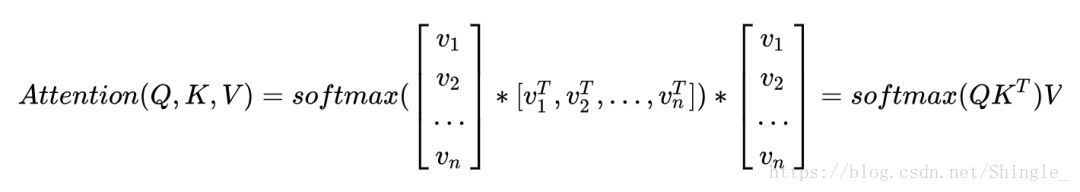

Conclusion
Attention 函式的本質可以被描述為一個查詢(query)到一系列(鍵key-值value)對的對映。
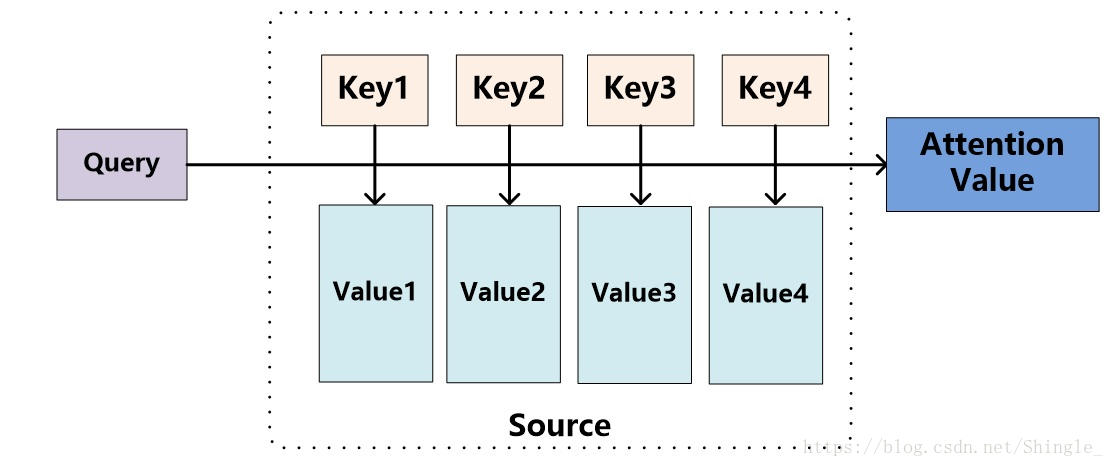
將Source中的構成元素想象成是由一系列的<Key,Value>資料對構成,此時給定Target中的某個元素Query,通過計算Query和各個Key的相似性或者相關性,得到每個Key對應Value的權重係數,然後對Value進行加權求和,即得到了最終的Attention數值。所以本質上Attention機制是對Source中元素的Value值進行加權求和,而Query和Key用來計算對應Value的權重係數
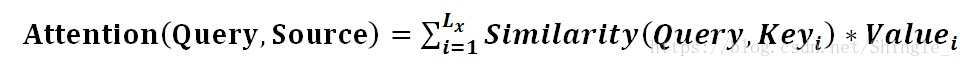
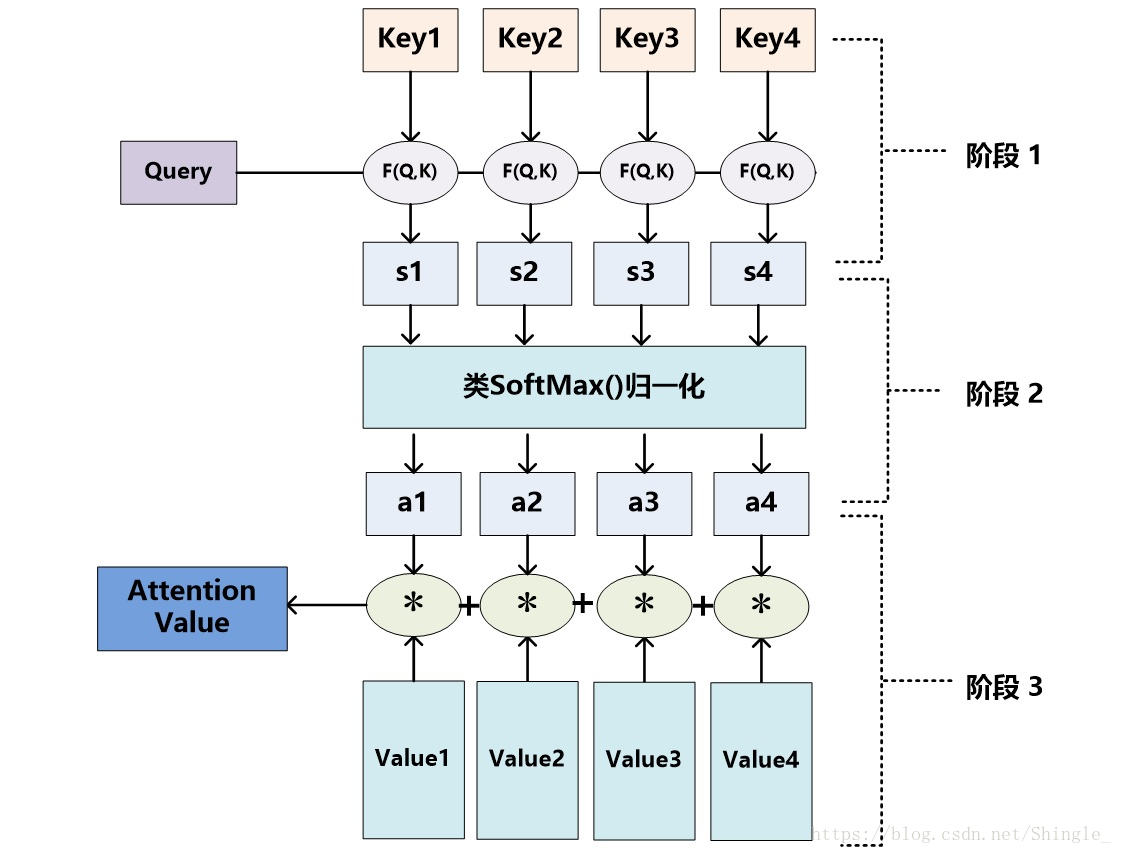
Attention機制的具體計算過程,如果對目前大多數方法進行抽象的話,可以將其歸納為三個階段:第一個階段根據Query和Key計算兩者的相似性或者相關性;第二個階段對第一階段的原始分值進行歸一化處理;第三個階段根據權重係數對Value進行加權求和。
- 在一般任務的Encoder-Decoder框架中,輸入Source和輸出Target內容是不一樣的,比如對於英-中機器翻譯來說,Source是英文句子,Target是對應的翻譯出的中文句子,Attention機制發生在Target的元素Query和Source中的所有元素之間。K=V
- Self Attention是Source內部元素之間或者Target內部元素之間發生的Attention機制,也可以理解為Target=Source這種特殊情況下的注意力計算機制。Q=K=V
Paper:
[1] 《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》 https://arxiv.org/pdf/1409.0473v7.pdf
[2] 《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》 http://cn.arxiv.org/pdf/1502.03044v3.pdf
[2] 《Effective Approaches to Attention-based Neural Machine Translation》 http://cn.arxiv.org/pdf/1508.04025v5.pdf
Blog:
Implement: