
Attention機制學習(一)傳統Attention機制
前言
縱觀神經網路的發展歷程,從最原始的MLP,到CNN,到RNN,到LSTM,GRU,再到現在的Attention機制,人們不斷的在網路裡面加入一些先驗知識,使得網路不過於“發散”,能夠朝著人們希望的方向去發展。
這些先驗知識是指:區域性視野知識、序列遞迴知識、結構遞迴知識,已經長短時的記憶。現在,人們加入了注意力這種先驗知識。
本文將介紹應用在NLP領域的attention機制,包括傳統的attention機制以及最新的transformer機制。
啥子叫注意力?
注意力機制可以看做一種通用的思想,是指人在工作的是注意力往往會集中在整個場景中的某些焦點上。
舉個例子哈,大家在中學做語文的閱讀理解的時候,有一個常見的題目就是找整篇文章的中心句。這個時候,我們往往都把注意力集中在開頭段、結尾段,中間的內容不是說不重要,但是在找中心句的時候,我們往往把注意力偏重於開頭結尾。這就是一種注意力的體現。
再舉個例子:

這是一種街景圖,假設現在我們處在這個場景中,我想找周圍有沒有超市,那麼對於這麼一個映入我眼瞼的影象,我肯定會認為超市應該在街道的兩邊,不會在空中。於是,我會把我的注意力集中在前方的左右兩邊的商店。
又比如,還是在這個場景中,假設開車在這條道路上,急著去見妹紙,那麼我的注意力自然就是紅綠燈咯。
這兩個例子基本就能體現出注意力機制的核心思想:對於一個複雜的輸入,不同的問題會把注意力側重於不同的地方。
那再看看在機器翻譯的一個小小的attention的例子。
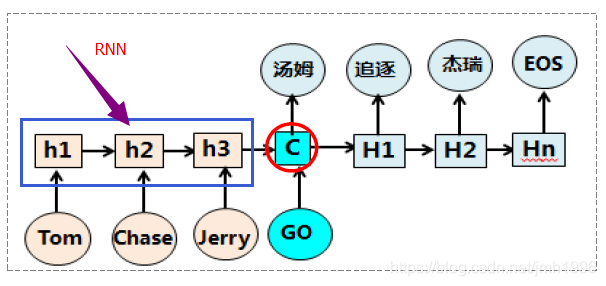
這是一個很典型的基於RNN網路的機器翻譯模型,模型先依次往網路輸入 Tom,Chase,Jerry,然後最後得到待翻譯句子的向量表達
,這個
理應結合了輸入的所有資訊。然後翻譯的時候,“湯姆”就基於
給計算出來了。
但是,我們隱隱約約感受到這樣的模型似乎在翻譯成“湯姆”的時候,把Tom chase Jerry 這三個詞都視為同等重要來翻譯,但實際上 這個詞的翻譯的 注意力應該在“Tom”這個詞的附近。說的更直白一些,“湯姆”這個翻譯結果對輸入各個詞的關注度應該有所側重,如果用權重衡量的話,Tom 可能佔用了0.7的關注度,其他兩個詞可能分別佔用0.2和0.1的關注度。
基本思想就是這樣子的了,通過關注度的高低大小來體現注意力的傾向。
注意力機制核心思想
假設, 中 表示輸入的一部分, 表達輸入的一部分。現在在某個任務的時候,我們給輸入的各個 有個打分 ,那些任務高度關注的 打分就高。那麼應該怎麼做?
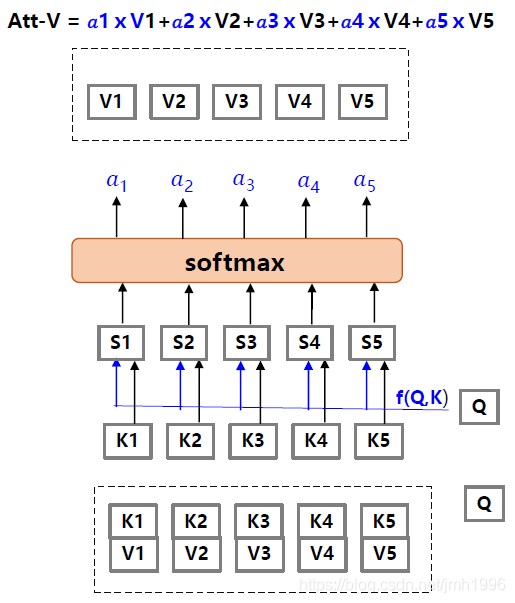
如上圖所示,做的方法很簡單的,首先
表示一個與當前任務有關的矩陣,它可以協助選擇出那個
的權重大。
於是先拿
和
做一次
運算得到不同
,然後在對這些
進行歸一化,得到對應的規範權重。最後,在依這些權重計算
的線性組合
。
通常,K和V是相等的。
而這個加權後
的線性組合
就是傳說中的注意力值,這個值就對
這幾個值有所側重。
我們再看打分函式
一般是那些函式:
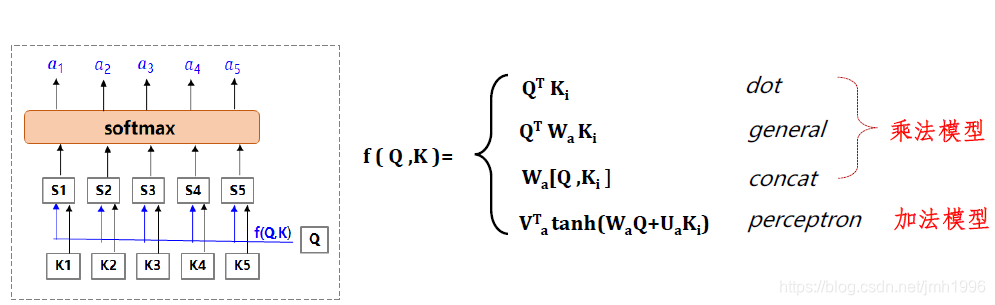
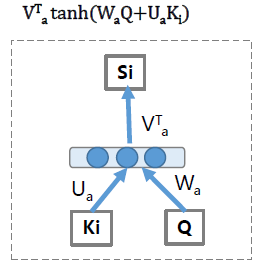
它可以是個標註向量內積,也可以是橢圓內積,或者concat,當然也可以專門設計一個小型的MLP來完成這個f的功能。
注意力的分類
求注意力的時候,不同分配限制會有不同的注意力。
例如:
軟注意力
對概率的分配沒有任何限制。
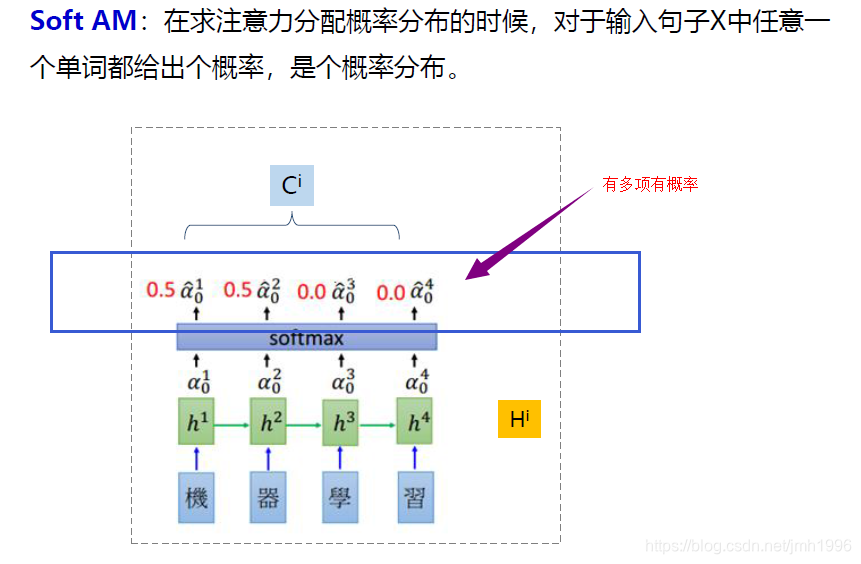
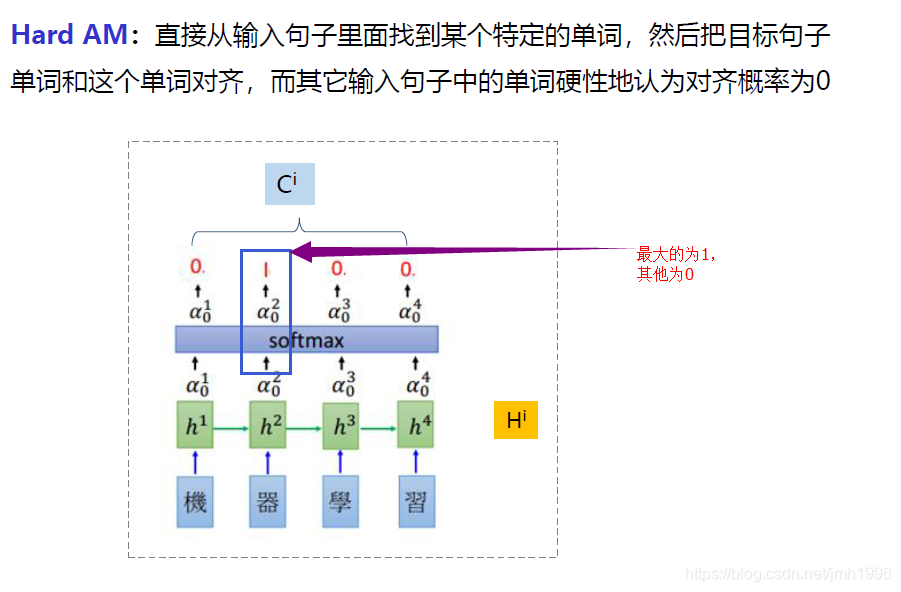
硬注意力:
在軟注意力的基礎上對概率分配新增某種限制,例如:限制概率最大的那個 為1,其他強制改為0。
然後考慮計算Attention是基於輸入的全部還是區域性又分為全域性注意力。
全域性注意力
Decoder段在計算Attention是考慮Encoder的所有詞。
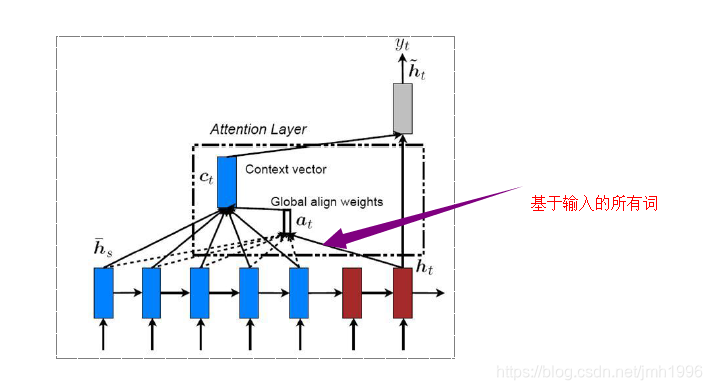
這樣得到的注意力值Att-V 是全域性輸入向量的依各列相應概率值的線性組合。
區域性注意力
與全域性注意力形成對比的是,為了加快訓練速度,可以設定一個視窗,使得對於輸入的視窗內的向量進行打分,然後求這些視窗內的向量的線性組合。
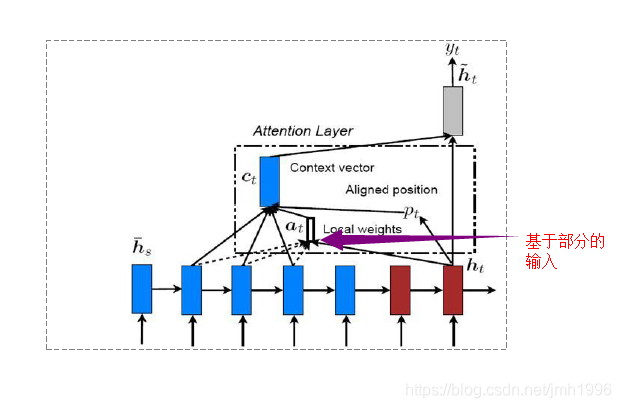
Attention的具體應用
見下一篇部落格,專門解讀2015年attention機制用於機器翻譯的句嵌入表示的論文。