
CS231n 2.1節資料驅動方法學習筆記
圖片分類器
圖片在計算機眼中就是一個巨大的矩陣,每一個畫素點通過幾個數字表示,比如RGB 語義鴻溝:語義概念和計算機中的巨大矩陣有著非常大的區別 視角、光照、物體不同形狀、遮擋、圖片背景混亂、種內差異的變化為計算機能夠把同類的物體識別出來帶來了巨大挑戰。
最早的資料驅動圖片分類演算法 nearest neighbor 分類器 記錄所有的學習資源,然後搜尋與現有學習到的資源最相近的圖片,並輸出它的標籤
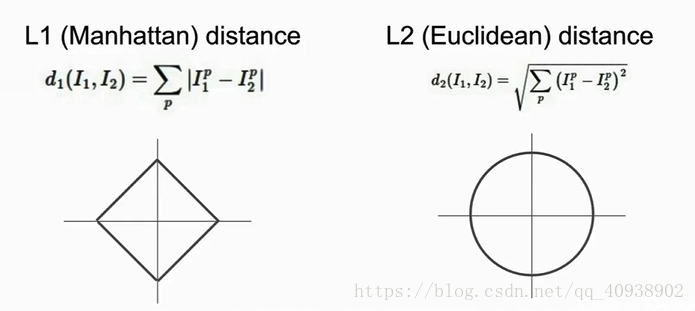
L1 distance (Manhattan distance): 比較圖片中的單個畫素 Numpy是一個非常有用的工具 問題: (1)Train O(1) while Test O(N) (2)色中色 (3)伸出的手指
K-Nearest Neighbors 找到K(K>1)個最近的點,進行投票(可以有權重,但最簡單的方式是多數投票),得出答案 事實證明,此種方法可以使邊緣更加光滑,從而減少錯誤率
兩種不同的觀點 在平面上的高維點概念 看具體影象的畫素點
L2 Distance (歐氏距離) L1 Distance 和 L2 Distance 的比較
超引數
!誤區: (1) 選擇使訓練集錯誤率最小的超引數 過擬合問題 (2) 把訓練集分為兩部分,train 和 test,利用train來訓練,然後選擇一組在test上表現最好的超引數 這組測試集的表現無法代表在從未見過的其他資料集上的表現
正確的做法是,將資料集分為三部分,train、validation、test 在訓練集上使用不同的超引數來訓練,使用驗證集進行評估,選擇在驗證集上表現最好的,利用測試集才能最終得出該分類器在完全未知的資料集上的表現 注意分離驗證集和測試集,只在最後一刻才會接觸到測試集
另一種做法是交叉驗證: 將訓練資料分為很多份,對不同份迴圈驗證 但由於需要耗費大量的計算力,所以該法不常用
資料相互獨立,並服從同一分佈 一定保證訓練集、驗證集、測試集的資料打亂後再行分配,保證測試集資料的代表性
以上介紹的KNN分類器並不常用,原因是: (1)測試時間長 (2)L1距離和L2距離用在圖片的比較上並不合適 (3)維度災難,若希望分類器有好的效果,則需要資料密集的分佈在空間中,這意味著我們需要指數倍的增加訓練資料
以上介紹了影象分類的基本思路