
MySQL 常見面試題彙總
一、儲存引擎
MySQL常見的兩種儲存引擎:MyISAM與InnoDB
二、字符集及校對規則
字符集指的是一種從二進位制編碼到某類字元符號的對映。校對規則則是指某種字符集下的排序規則。Mysql中每一種字符集都會對應一系列的校對規則。
Mysql採用的是類似繼承的方式指定字符集的預設值,每個資料庫以及每張資料表都有自己的預設值,他們逐層繼承。比如:某個庫中所有表的預設字符集將是該資料庫所指定的字符集(這些表在沒有指定字符集的情況下,才會採用預設字符集)
三、索引
Mysql索引使用的資料結構主要有BTree索引 和 雜湊索引 。對於雜湊索引來說,底層的資料結構就是雜湊表,因此在絕大多數需求為單條記錄查詢的時候,可以選擇雜湊索引,查詢效能最快;其餘大部分場景,建議選擇BTree索引。
Mysql的BTree索引使用的是B數中的B+Tree,但對於主要的兩種儲存引擎的實現方式是不同的。
MyISAM: B+Tree葉節點的data域存放的是資料記錄的地址。在索引檢索的時候,首先按照B+Tree搜尋演算法搜尋索引,如果指定的Key存在,則取出其data域的值,然後以data域的值為地址讀取相應的資料記錄。這被稱為“非聚簇索引”。
InnoDB: 其資料檔案本身就是索引檔案。相比MyISAM,索引檔案和資料檔案是分離的,其表資料檔案本身就是按B+Tree組織的一個索引結構,樹的葉節點data域儲存了完整的資料記錄。這個索引的key是資料表的主鍵,因此InnoDB表資料檔案本身就是主索引。這被稱為“聚簇索引(或聚集索引)”。而其餘的索引都作為輔助索引,輔助索引的data域儲存相應記錄主鍵的值而不是地址,這也是和MyISAM不同的地方。在根據主索引搜尋時,直接找到key所在的節點即可取出資料;在根據輔助索引查詢時,則需要先取出主鍵的值,在走一遍主索引。
四、快取
my.cnf加入以下配置,重啟Mysql開啟查詢快取
query_cache_type=1
query_cache_size=600000Mysql執行以下命令也可以開啟查詢快取
set global query_cache_type=1;
set global query_cache_size=600000;如上,開啟查詢快取後在同樣的查詢條件以及資料情況下,會直接在快取中返回結果。這裡的查詢條件包括查詢本身、當前要查詢的資料庫、客戶端協議版本號等一些可能影響結果的資訊。因此任何兩個查詢在任何字元上的不同都會導致快取不命中。此外,如果查詢中包含任何使用者自定義函式、儲存函式、使用者變數、臨時表、Mysql庫中的系統表,其查詢結果也不會被快取。
快取建立之後,Mysql的查詢快取系統會跟蹤查詢中涉及的每張表,如果這些表(資料或結構)發生變化,那麼和這張表相關的所有快取資料都將失效。
快取雖然能夠提升資料庫的查詢效能,但是快取同時也帶來了額外的開銷,每次查詢後都要做一次快取操作,失效後還要銷燬。 因此,開啟快取查詢要謹慎,尤其對於寫密集的應用來說更是如此。如果開啟,要注意合理控制快取空間大小,一般來說其大小設定為幾十MB比較合適。此外,還可以通過sql_cache和sql_no_cache來控制某個查詢語句是否需要快取:
select sql_no_cache count(*) from usr;五、事務
關係性資料庫需要遵循ACID規則,具體內容如下:
-
原子性: 事務是最小的執行單位,不允許分割。事務的原子性確保動作要麼全部完成,要麼完全不起作用;
-
一致性: 執行事務前後,資料保持一致;
-
隔離性: 併發訪問資料庫時,一個使用者的事物不被其他事物所幹擾,各併發事務之間資料庫是獨立的;
-
永續性: 一個事務被提交之後。它對資料庫中資料的改變是持久的,即使資料庫 發生故障也不應該對其有任何影響。
為了達到上述事務特性,資料庫定義了幾種不同的事務隔離級別:
-
READ_UNCOMMITTED(未授權讀取): 最低的隔離級別,允許讀取尚未提交的資料變更,可能會導致髒讀、幻讀或不可重複讀
-
READ_COMMITTED(授權讀取): 允許讀取併發事務已經提交的資料,可以阻止髒讀,但是幻讀或不可重複讀仍有可能發生
-
REPEATABLE_READ(可重複讀): 對同一欄位的多次讀取結果都是一致的,除非資料是被本身事務自己所修改,可以阻止髒讀和不可重複讀,但幻讀仍有可能發生。
-
SERIALIZABLE(序列): 最高的隔離級別,完全服從ACID的隔離級別。所有的事務依次逐個執行,這樣事務之間就完全不可能產生干擾,也就是說,該級別可以防止髒讀、不可重複讀以及幻讀。但是這將嚴重影響程式的效能。通常情況下也不會用到該級別。
這裡需要注意的是:Mysql 預設採用的 REPEATABLE_READ隔離級別 Oracle 預設採用的 READ_COMMITTED隔離級別.
事務隔離機制的實現基於鎖機制和併發排程。其中併發排程使用的是MVVC(多版本併發控制),通過儲存修改的舊版本資訊來支援併發一致性讀和回滾等特性。
六、鎖
MyISAM和InnoDB儲存引擎使用的鎖:
-
MyISAM採用表級鎖(table-level locking)。
-
InnoDB支援行級鎖(row-level locking)和表級鎖,預設為行級鎖
表級鎖和行級鎖對比:
-
表級鎖: Mysql中鎖定 粒度最大 的一種鎖,對當前操作的整張表加鎖,實現簡單,資源消耗也比較少,加鎖快,不會出現死鎖。其鎖定粒度最大,觸發鎖衝突的概率最高,併發度最低,MyISAM和 InnoDB引擎都支援表級鎖。
-
行級鎖: Mysql中鎖定 粒度最小 的一種鎖,只針對當前操作的行進行加鎖。 行級鎖能大大減少資料庫操作的衝突。其加鎖粒度最小,併發度高,但加鎖的開銷也最大,加鎖慢,會出現死鎖。
InnoDB儲存引擎的鎖的演算法有三種:
-
Record lock:單個行記錄上的鎖
-
Gap lock:間隙鎖,鎖定一個範圍,不包括記錄本身
-
Next-key lock:record+gap 鎖定一個範圍,包含記錄本身
七、大表優化
當MySQL單表記錄數過大時,資料庫的CRUD效能會明顯下降,一些常見的優化措施如下:
-
限定資料的範圍: 務必禁止不帶任何限制資料範圍條件的查詢語句。比如:我們當用戶在查詢訂單歷史的時候,我們可以控制在一個月的範圍內。;
-
讀/寫分離: 經典的資料庫拆分方案,主庫負責寫,從庫負責讀;
-
快取: 使用MySQL的快取,另外對重量級、更新少的資料可以考慮使用應用級別的快取;
-
垂直分割槽:
根據資料庫裡面資料表的相關性進行拆分。 例如,使用者表中既有使用者的登入資訊又有使用者的基本資訊,可以將使用者表拆分成兩個單獨的表,甚至放到單獨的庫做分庫。
簡單來說垂直拆分是指資料表列的拆分,把一張列比較多的表拆分為多張表。 如下圖所示,這樣來說大家應該就更容易理解了。
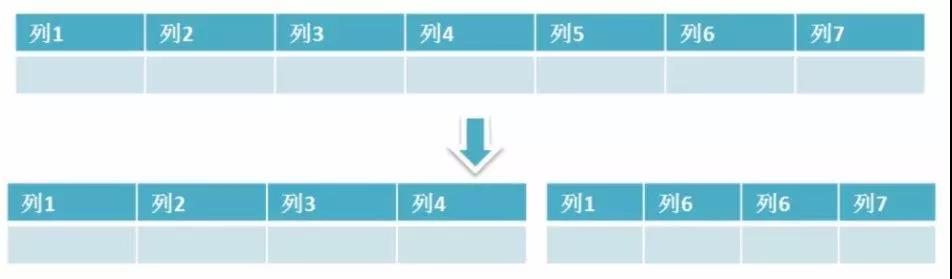
垂直拆分的優點: 可以使得行資料變小,在查詢時減少讀取的Block數,減少I/O次數。此外,垂直分割槽可以簡化表的結構,易於維護。
垂直拆分的缺點: 主鍵會出現冗餘,需要管理冗餘列,並會引起Join操作,可以通過在應用層進行Join來解決。此外,垂直分割槽會讓事務變得更加複雜;
5. 水平分割槽:
保持資料表結構不變,通過某種策略儲存資料分片。這樣每一片資料分散到不同的表或者庫中,達到了分散式的目的。 水平拆分可以支撐非常大的資料量。
水平拆分是指資料錶行的拆分,表的行數超過200萬行時,就會變慢,這時可以把一張的表的資料拆成多張表來存放。舉個例子:我們可以將使用者資訊表拆分成多個使用者資訊表,這樣就可以避免單一表資料量過大對效能造成影響。
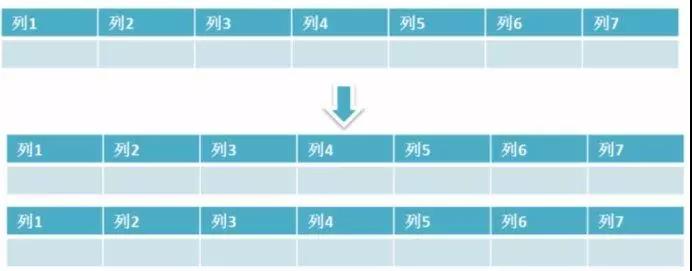
水品拆分可以支援非常大的資料量。需要注意的一點是:分表僅僅是解決了單一表資料過大的問題,但由於表的資料還是在同一臺機器上,其實對於提升MySQL 併發能力沒有什麼意義,所以 水品拆分最好分庫 。
水平拆分能夠 支援非常大的資料量儲存,應用端改造也少,但 分片事務難以解決 ,跨界點Join 效能較差,邏輯複雜。《Java工程師修煉之道》的作者推薦 儘量不要對資料進行分片,因為拆分會帶來邏輯、部署、運維的各種複雜度 ,一般的資料表在優化得當的情況下支撐千萬以下的資料量是沒有太大問題的。如果實在要分片,儘量選擇客戶端分片架構,這樣可以減少一次和中介軟體的網路 I/O。
下面補充一下資料庫分片的兩種常見方案:
-
客戶端代理: 分片邏輯在應用端,封裝在jar包中,通過修改或者封裝JDBC層來實現。 噹噹網的 Sharding-JDBC 、阿里的TDDL是兩種比較常用的實現。
-
中介軟體代理: 在應用和資料中間加了一個代理層。分片邏輯統一維護在中介軟體服務中。 我們現在談的 Mycat、360的Atlas、網易的DDB等等都是這種架構的實現。
轉自公眾號:老芋艿