
CVPR 2018 | 曠視科技Face++率先提出DocUNet 可復原扭曲的文件影象
全球計算機視覺頂會 CVPR 2018 (Conference on Computer Vision and Pattern Recognition,即IEEE國際計算機視覺與模式識別會議)將於6月18日至22日在美國鹽湖城舉行。作為大會鑽石贊助商,曠視科技Face++研究院也將在孫劍博士的帶領下重磅出席此次盛會。而在盛會召開之前,曠視將針對 CVPR 2018 收錄論文集中進行系列解讀。

論文連結:
目錄
- 導語
- 設計思想
- 資料集
- 2D 扭曲影象合成
- DocUNet
- 網路架構
- 損失函式
- 實驗
- 基準
- 結果
- 結論
- 參考文獻
導語
由於移動攝像頭數量劇增,隨手拍照已成為一種對物理文件進行數字化記錄的普遍方式,並可據此展開後續操作,比如文字識別。但是,由於物理文件時常存在扭曲或變形,以及光線條件差等情況,文字識別難以達到理想效果。針對這一問題,曠視科技Face++首次提出一種基於學習的堆疊式 U-Net,稱之為 DocUNet,可以平整和復原扭曲變形的文件影象。DocUNet 填補了深度學習領域的一項技術空白。由於平整變形文件影象的有效和效率,DocUNet 可大幅降低文字識別的難度,優化 OCR 技術發展,進而推動真實、網路等不同場景下的文字識別和檢索能力,從底層技術的維度為辦公自動化、智慧零售、無人超市甚至是自動駕駛的革新添磚加瓦、鋪平道路。
設計思想
文件數字化是儲存現有列印文件的一種重要方式,可以隨時隨地訪問。傳統方法藉助平板式掃描器數字化文件,但是不易攜帶,成本高昂。最近,隨著移動攝像頭日益增多,拍攝物理文件成為最便捷的一種文件掃描方式。一旦拍攝,影象可由文字檢測和識別技術進一步處理,實現內容分析和資訊提取。
拍攝文件影象常見的一個實際問題是文件頁的掃描條件不理想:它們可能彎曲、摺疊、弄皺,或者放在非常複雜的背景上。試想一張從錢包取出的褶皺收據。所有這些因素都可能為文件影象的自動分析流程帶來嚴重問題,如圖 1 所示。因此存在數字化平整拍攝影象中扭曲文件的需求。

圖 1:文件影象的平整化及其用途。(a) 展示了本文工作的一些成果。上面是輸入影象,下面是輸出影象。(b) 本文網路顯著提升了當前最優文字檢測系統的效能:相較於上面的扭曲影象,下面的復原文件影象可以檢測出更多單詞(綠色)。
文件影象的平整化不是一個新問題,已有多種解決方案。一些視覺系統依賴於精心設計和校準的硬體,比如立體攝像頭,或者結構光投影儀以測量文件的 3D 扭曲;它們表現很好,但額外的硬體限制了其應用;其他工作吸取這一教訓,通過多視角影象重建扭曲文件影象的 3D 形狀。一些人則致力於通過各種低層的手工特徵(比如明暗度,文字行等)分析單一影象而復原文件影象。
本文給出一種基於學習的全新方法,來複原任意彎曲和摺疊的文件拍攝影象。不同於先前方法,本文提出首個端到端學習方法,可以直接預測文件扭曲。先前方法只使用學習提取特徵,而最後的影象復原仍基於傳統的優化技術;本文方法則藉助卷積神經網路(CNNs)端到端復原影象。相較於優化方法,前饋網路的測試表現非常搶眼。此外,如果具備合適的訓練資料,這一資料驅動的方法還可以更好地泛化至其他文件型別(文字、數字、手寫體等)。
該方法把這一問題轉化為尋找合適的 2D 對映,以復原失真影象文件。它預測一個對映域,把扭曲的源影象 S(u, v) 中的畫素移動到結果影象 D 中的 (x, y) 。
由此本文發現該任務與語義分割有一些共性;對於後者而言,網路為每個畫素分配一類標籤。相似地,本文網路則為每個畫素分配一個 2D 向量。這啟發作者在網路結構中使用語義分割領域家喻戶曉的 U-Net 解決本文的迴歸問題,並定義一個全新的損失函式以驅動網路為 S 中的每個畫素迴歸 D 中的座標 (x, y)。
獲取帶有標籤的海量資料是深度監督學習面臨的首個挑戰。為訓練網路,作者需要扭曲程度不同的大量文件影象及相應的變形影象作為輸入以實現完美復原。可惜目前這樣的資料集不存在。獲取真實的變形標籤影象非常難,所以本文最後選擇合成數據。通過隨機扭曲平整的文件影象,本文合成了 100K 張影象,以便把擾動影象作為輸入,而本文用來扭曲影象的網路則是旨在復原的逆變形。
同樣也沒有評估文件平整化的可用公共基準。先前方法要麼在少量影象上進行評估,要麼資料集只包含若干個扭曲型別。作者創作了一個包含 130 張影象的基準填補了這一空白,在文件型別、扭曲程度及型別以及拍攝條件方面差異巨大。
資料集
本文方法基於 CNN,需要大量訓練資料。在該任務中,文件變形可以表徵為 3D 網格、曲面法線、2D 流動等,在現實世界中以任意形式精確地拍攝它非常困難,需要諸如深度攝像頭(range camera)或者標定立體視覺系統等額外硬體,同時預估變形的精確度通常依賴於硬體成本。此外,通過手動扭曲/變形文件檔案以涵蓋全部實際情形是很不現實的。
本文考慮使用合成數據進行訓練,這在最近的深度學習中很常見,並允許完全掌控資料集的變化。
一個直觀的想法是在 3D 渲染文件中直接渲染扭曲的文件,但由於下述原因這是不切實際的。首先,通過物理模擬生成物理上正確的 3D 網格非常難且慢。第二,通過路徑追蹤渲染同樣非常費時。渲染 100K 影象耗時將超過兩月。
2D 扭曲影象合成
本文直接合成 2D 訓練影象。儘管已忽略基礎的物理建模,但操縱 2D 網格相當簡單,且生成影象也很快。由於本文目的是把扭曲紙張對映到復原紙張,因此資料合成是反向過程,即,把復原影象進行多種型別的扭曲。
當建立扭曲圖時,本文遵循以下實證原則:i)一張真實的紙張是區域性剛性的,不會延展或壓縮。一點上的扭曲將帶來空間上的改變。ii)存在兩類扭曲:摺疊和彎曲,分別產生紙張的摺痕和捲曲。實際情形通常是這兩類扭曲的結合。
本文首先蒐集大量平整的數字文件,包括論文、書籍和雜誌頁面等;接著扭曲這些影象,如圖 2 所示。

圖 2:2D 合成扭曲文件影象。
擾動網格生成:給定影象 I,本文在其上放置一個 m x n 網格 M 以為扭曲提供控制點。在 M 上選擇一個隨機頂點 p 作為初始變形點。變形的方向和強度標記為 v,且也隨機生成。最後,基於 i),v 通過權重 w 傳播至其他頂點。扭曲網格上的頂點被計算為 p_i + wv, ∀i。
擾動影象生成:擾動網格提供一個稀疏的變形域。本文以線性方式對其進行插值,以從畫素層面構建密集的扭曲圖,接著把扭曲圖應用到原始影象以生成擾動影象。作者通過這種方式在單塊 CPU 上合成了 100K 張影象。每張影象最多包含 19 種合成變形(30% 是彎曲,70% 是摺疊)。彎曲需要保證高斯曲率在任意位置都應為 0,摺疊則隨意。樣本如圖 5 所示。

圖 5:合成數據中的樣本影象。
DocUNet
網路架構
類似於語義分割,本文自行設計網路以強化逐畫素的監督。出於其在語義分割任務上的簡潔性和有效性,本文選擇 U-Net 作為基礎模型,它基本上是一個全卷積網路,包含一系列的下采樣層和隨後的上取樣層,特徵對映在上、下采樣層之間連線。
但是,單一 U-Net 的輸出並不令人滿意,應該進行優化,因此在第一個 U-Net 的輸出上堆疊另外一個 U-Net 作為 refiner。如圖 3 所示。
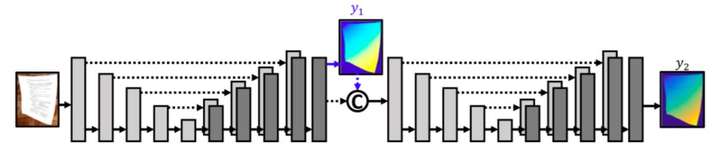
圖 3:網路架構。該網路由兩個 U-Net 堆疊而成。該網路從第一個 U-Net 的輸出中分割和輸出一個前向對映 y_1。應用在 y_2 的同一損失也應用在 y_1。接著 y_1 連線到第一個 U-Net 的輸出特徵對映,並作為第二個U-Net 的輸入。y_2 可直接用於生成復原影象。
本文有一個層負責把去卷積特徵轉化為最後的輸出 (x, y)。第一個 U-Net 在最後一個去卷積層之後分叉為兩支。把第一個 U-Net 的去卷積特徵和中間預測 y_1 連線起來作為第二個 U-Net 的輸入。第二個 U-Net 最後給出一個優化的預測 y_2 ,作者將其用作網路的最後輸出。本文在訓練時把同一損失函式應用於 y_1 和 y_2。但是在測試時,只把 y_2 用作網路的輸出。
不同於語義分割本質上是一個畫素分類問題,該網路輸出(為對映 F)的計算是一個迴歸的過程。語音分割的輸出通常有 C 個通道,其中 C 是語義類別的數量。該網路只為 (x, y) 座標輸出 2 個通道。
損失函式
損失函式包含兩個部分:1. 輸出的對映 y 和其對應的 groundtruth 對映 y^star 之間的絕對誤差(element-wise loss)。2. 輸出的不同點的對映的相對位置 y_1 - y_2 和它們對應的 groundtruth 對映相對位置 y_1^star - y_2^star 之間的相對誤差(shift invarient loss)。
其中絕對誤差本文表示為:
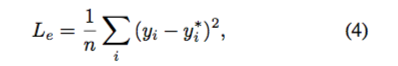
相對誤差表示為:
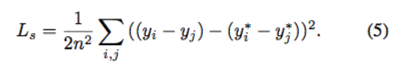
假設 d_i = y_i - y_i^star,Eq. 5 可表示為:
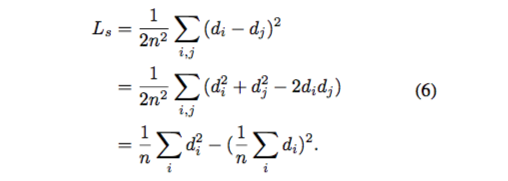
本文同時發現 L1 (Eq. 7)優於 L2(Eq. 6),因此損失函式可重寫為:

F 中與 S 的背景畫素相對應的元素是常數 -1,因此 Eq. 7 中的部分損失來自背景。實際上網路沒有必要把這些元素精確迴歸到 -1。任意負值都應該足夠。因此本文把 hinge loss 用於背景畫素:
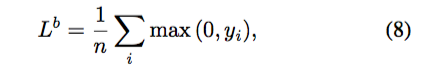
同時 Eq. 7 只用於前景畫素。
實驗
本文首先介紹評估單一影象上扭曲文件復原的基準;接著評估本文提出的基於學習的方法,並與先前非學習方法的結果作對比。
基準
影象:基準之中的影象是手機拍攝的物理紙張文件的影象。蒐集 65 個各種內容/形式的紙張文件,其中每個文件拍照兩張,共有 130 張影象。基準包含原始影象和剪裁框正的影象(document centered cropped images ),實驗使用後者,因為本文的重點是平整化紙張而不是定點陣圖像中的文件。基準的建立基於以下考量:
i)文件型別:選擇的文件型別各不相同,有收據、信件、檔案、雜誌、論文、書籍等;
ii)扭曲:原始的平整紙張文件由不同的人進行物理扭曲;
iii)環境:影象由兩個人用兩部不同的手機在室內、室外不同的光照條件下拍攝。
Groundtruth:在摺疊已選擇的紙張文件之前,通過平板式掃描器對其掃描。調整已獲取影象的大小和整體顏色以儘可能地匹配原始的平整文件。圖 6 是基準中的一些例項。

圖 6:基準樣本。
結果
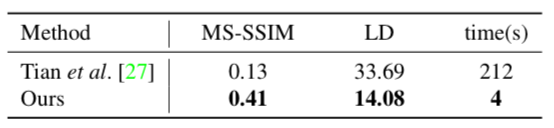
基準評估表明該方法優於先前的 Tian et al. [27]。具體而言,該方法的成績在 MS-SSIM 和 LD 分別是 0.41 和 14.08,相比之下,[27] 的成績分別為 0.13 和 33.69。這是因為 [27] 主要針對文字行文件而設計,嚴重依賴於文字行追蹤的質量,因此無法處理更為複雜的文件,比如混合文字行和數字,或者文字行追蹤失敗的區域,如圖 10 所示。

圖 10:對比Tian et al. [27]。
在計算效率方面,[27] 藉助 Matlab 實現在 1 塊 CPU 處理 1 張影象耗時 3 到 4 分鐘。相比之下,本文網路在 GTX 1080 Ti GPU 上的執行速度是 28 fps,雖然這種對比有點不公平。瓶頸在於從對映中生成復原影象。本文未優化的 Matlab 實現在 CPU 上大約耗時 3 到 4 秒。整體上該方法快 [27] 一個數量級,如下表所示:
更多對比結果請見圖 8 和 圖 9:

圖 8:對比 You et al. [36]。儘管 [36] 使用 5 到 10 張影象,本文方法依然相當有競爭力。

圖 9:對比 Das et al. [6]。[6] 的方法專門針對摺疊兩次的文件而設計。這種情況下本文方法同樣表現良好。上圖中的例項影象來自 [6]。
結論
本文展現了首個平整和復原扭曲文件影象的端到端神經網路。作者提出一個帶有中間監督的堆疊式 U-Net,並對它進行端到端訓練以直接預測可以移除影象扭曲的對映。作者還建立了合成訓練資料,以及一個包含在各種條件下拍攝的真實影象的基準。實驗結果證實了該方法的有效和效率。
在未來工作中,作者將應用 GAN 把這一網路更好地泛化至實際影象上,並希望加入亮度模型以移除復原影象上的高光或陰影。另一方面,作者還會優化從對映中生成復原影象的程式碼,並在移動端實現整個流程的實時部署。
參考文獻
[6] S. Das, G. Mishra, A. Sudharshana, and R. Shilkrot. The Common Fold: Utilizing the Four-Fold to Dewarp Printed Documents from a Single Image. In Proceedings of the 2017 ACM Symposium on Document Engineering, DocEng ’17, pages 125–128. ACM, 2017.
[7] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In Advances in Neural Information Processing Systems, 2014.
[21] G. Meng, Y. Wang, S. Qu, S. Xiang, and C. Pan. Active flattening of curved document images via two structured beams. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2014.
[25] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention. Springer, 2015.
[27] Y. Tian and S. G. Narasimhan. Rectification and 3D recon- struction of curved document images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2011.
[28] Y.-C. Tsoi and M. S. Brown. Multi-view document rectification using boundary. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2007.
[36] S.You,Y.Matsushita,S.Sinha,Y.Bou,andK.Ikeuchi.Multiview Rectification of Folded Documents. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.