
企業級nosql資料庫應用與實戰-redis
目錄
正文
一、NoSQL簡介
1.1 常見的優化思路和方向
1.1.1 MySQL主從讀寫分離
由於資料庫的寫入壓力增加,Memcached只能緩解資料庫的讀取壓力。讀寫集中在一個數據庫上讓資料庫不堪重負,大部分網站開始使用主從複製技術達到讀寫分離,以提高讀寫效能和讀庫的可擴充套件性。Mysql的master-slave模式成為這個時候的網站標配了。
1.1.2 分庫分表
隨著web2.0的繼續高速發展,在Memcached的快取記憶體,MySQL的主從複製,讀寫分離的基礎之上,這時MySQL主庫的寫壓力開始出現瓶頸,而資料量的持續猛增,由於MyISAM使用表鎖,在高併發下會出現嚴重的鎖問題,大量的高併發MySQL應用開始使用InnoDB引擎代替MyISAM。同時,開始流行使用分表分庫來緩解寫壓力和資料增長的擴充套件問題。這個時候,分表分庫成了一個熱門技術,是業界討論的熱門技術問題。也就在這個時候,MySQL推出了還不太穩定的表分割槽,這也給技術實力一般的公司帶來了希望。雖然MySQL推出了MySQL Cluster叢集,但是由於在網際網路幾乎沒有成功案例,效能也不能滿足網際網路的要求,只是在高可靠性上提供了非常大的保證。
1.2 NoSQL誕生的原因
關係型資料庫面臨的問題:
- 擴充套件困難:由於存在類似Join這樣多表查詢機制,使得資料庫在擴充套件方面很艱難;
- 讀寫慢:這種情況主要發生在資料量達到一定規模時由於關係型資料庫的系統邏輯非常複雜,使得其非常容易發生死鎖等的併發問題,所以導致其讀寫速度下滑非常嚴重;
- 成本高:企業級資料庫的License價格很驚人,並且隨著系統的規模,而不斷上升;
- 有限的支撐容量:現有關係型解決方案還無法支撐Google這樣海量的資料儲存;
資料庫訪問的新需求:
- 低延遲的讀寫速度:應用快速地反應能極大地提升使用者的滿意度;
- 支撐海量的資料和流量:對於搜尋這樣大型應用而言,需要利用PB級別的資料和能應對百萬級的流量;
- 大規模叢集的管理:系統管理員希望分散式應用能更簡單的部署和管理;
- 龐大運營成本的考量:IT經理們希望在硬體成本、軟體成本和人力成本能夠有大幅度地降低;
- NoSQL資料庫僅僅是關係資料庫在某些方面(效能、擴充套件)的一個彌補
- 單從功能上講,NoSQL的幾乎所有的功能,在關係資料庫上都能夠滿足。
- 一般會把NoSQL和關係資料庫進行結合使用,各取所長,各得其所。
- 在某些應用場合,比如一些配置的關係鍵值對映儲存、使用者名稱和密碼的儲存、Session會話儲存等等
- 在某些場景下,用NoSQL完全可以替代關係資料庫(如:MySQL)儲存。不但具有更高的效能,而且開發也更加方
1.3 分散式系統的挑戰
CAP原理是指這三個要素最多隻能同時實現兩點,不可能三者兼顧。因此在進行分散式架構設計時,必須做出取捨。而對於分散式資料系統,分割槽容忍性是基本要求,否則就失去了價值。因此設計分散式資料系統,就是在一致性和可用性之間取一個平衡。對於大多數WEB應用,其實並不需要強一致性,因此犧牲一致性而換取高可用性,是多數分散式資料庫產品的方向。
在理論電腦科學中,CAP定理(CAP theorem),又被稱作布魯爾定理(Brewer’s theorem),它指出對於一個分散式計算系統來說,不可能同時滿足以下三點:
- 一致性(Consistency)—所有節點在同一時間具有相同的資料
- 可用性(Availability)—保證每個請求不管成功或者失敗都有響應
- 分隔容忍(Partition tolerance)—系統中任意資訊的丟失或失敗不會影響系統的繼續運作
1.3.1關係資料庫和NoSQL側重點
| 關係資料庫 | NoSQL |
|---|---|
分散式關係型資料庫中強調的ACID分別是:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、永續性(Durability) |
對於許多網際網路應用來說,對於一致性要求可以降低,而可用性(Availability)的要求則更為明顯,在CAP理論基礎上,從而產生了弱一致性的理論BASE。 |
| ACID的目的就是通過事務支援,保證資料的完整性和正確性 | BASE分別是英文:Basically,Available(基本可用), Softstate(軟狀態)非實時同步,Eventual Consistency(最終一致)的縮寫,這個模型是反ACID模型 |
1.4 NoSQL的優缺點
優點:
- 簡單的擴充套件
典型例子是Cassandra,由於其架構是類似於經典的P2P,所以能通過輕鬆地新增新的節點來擴充套件這個叢集;
- 快速的讀寫
主要例子有Redis,由於其邏輯簡單,而且純記憶體操作,使得其效能非常出色,單節點每秒可以處理超過10萬次讀寫操作;
- 低廉的成本
這是大多數分散式資料庫共有的特點,因為主要都是開源軟體,沒有昂貴的License成本;
缺點:
- 不提供對SQL的支援
如果不支援SQL這樣的工業標準,將會對使用者產生一定的學習和應用遷移成本;
- 支援的特性不夠豐富
現有產品所提供的功能都比較有限,大多數NoSQL資料庫都不支援事務,也不像Oracle那樣能提供各種附加功能,比如BI和報表等;
- 現有產品的不夠成熟
大多數產品都還處於初創期,和關係型資料庫幾十年的完善不可同日而語;
1.5 NoSQL總結
- NoSQL資料庫的出現,彌補了關係資料(比如MySQL)在某些方面的不足,在某些方面能極大的節省開發成本和維護成本。
- MySQL和NoSQL都有各自的特點和使用的應用場景,兩者的緊密結合將會 給web2.0的資料庫發展帶來新的思路。讓關係資料庫關注在關係上,NoSQL關注在功能、效能上。
- 隨著移動網際網路的發展,以及業務場景的多樣化,社交元素的普遍化,Nosql從效能和功能上很好的補充了web2.0時代的原關係型資料的缺點,目前已經是各大公司必備的技術之一。
二、NoSQL的分類
2.1 基本分類
Column-oriented(列式)
- 主要圍繞著“列(Column)”,而非 “行(Row)”進行資料儲存
- 屬於同一列的資料會盡可能地儲存在硬碟同一個頁(Page)中
- 大多數列式資料庫都支援Column Family這個特性
- (很多類似資料倉庫(Data Warehouse)的應用,雖然每次查詢都會處理很多資料,但是每次所涉及的列並沒有很多)
- 特點:比較適合彙總(Aggregation)和資料倉庫這類應用。
Key-value(重要)
- 類似常見的HashTable,一個Key對應一個Value,但是其能提供非常快的查詢速度、大的資料存放量和高併發操作,
- 非常適合通過主鍵對資料進行查詢和修改等操作, 雖然不支援複雜的操作,但可通過上層的開發來彌補這個缺陷。
Document(文件) (比如:mongodb)
- 類似常見的HashTable,一個Key對應一個Value,
- 其能提供非常快的查詢速度、大的資料存放量和高併發操作,
- 非常適合通過主鍵對資料進行查詢和修改等操作,
- 資料型別多且存在大量的空項。比如SNS類的使用者profile,手機,郵箱,地址,性別……有很多項,而且大部分是空項。
2.2 常見分類
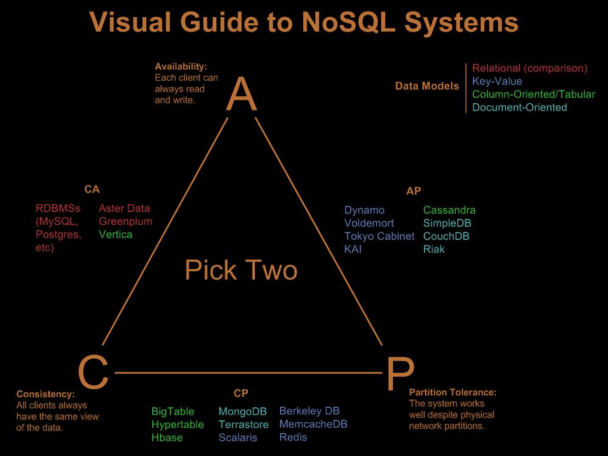
常見Nosql分類
關注一致性和可用性的(CA) 這些資料庫對於分割槽容忍性方面比較不感冒,主要採用複製(Replication)這種方式來保證資料的安全性,常見的CA系統有:
- 傳統關係型資料庫,比如Postgres和MySQL等(Relational)
- Oracle (Relational)
- Aster Data (Relational)
- Greenplum (Relational)
- NoSQL:
- redis
- mongodb
- cassandra
關注一致性和分割槽容忍性的(CP) 這種系統將資料分佈在多個網路分割槽的節點上,並保證這些資料的一致性,但是對於可用性的支援方面有問題,比如當叢集出現問題的話,節點有可能因無法確保資料是一致性的而拒絕提供服務,主要的CP系統有:
- BigTable (Column-oriented)
- Hypertable (Column-oriented)
- HBase (Column-oriented)
- MongoDB (Document)
- Terrastore (Document)
- Redis (Key-value)
- Scalaris (Key-value)
- MemcacheDB (Key-value)
- Berkeley DB (Key-value)
關於可用性和分割槽容忍性的(AP) 這類系統主要以實現“最終一致性(Eventual Consistency)”來確保可用性和分割槽容忍性,AP的系統有:
- Dynamo (Key-value)
- Voldemort (Key-value)
- Tokyo Cabinet (Key-value)
- KAI (Key-value)
- Cassandra (Column-oriented)
- CouchDB (Document-oriented)
- SimpleDB (Document-oriented)
- Riak (Document-oriented)
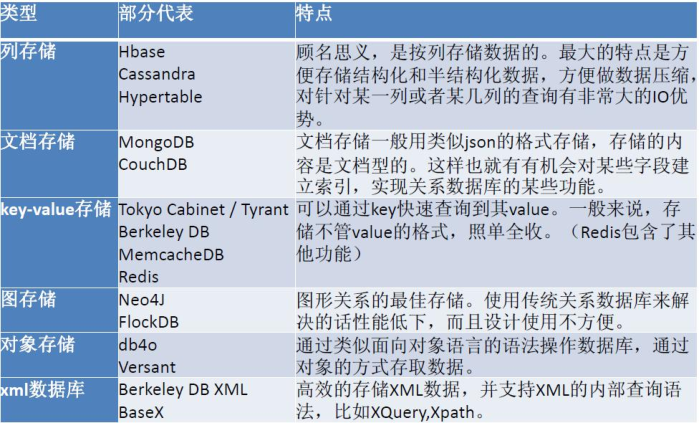
2.3 常見Nosql分類和部分代表
常見Nosql分類和部分代表
三、企業常見Nosql應用
3.1 純NoSQL架構(Nosql為主)
- 在一些資料結構、查詢關係非常簡單的系統中,我們可以只使用NoSQL即可以解決儲存問題。
- 在一些資料庫結構經常變化,資料結構不定的系統中,就非常適合使用NoSQL來儲存。
- 比如監控系統中的監控資訊的儲存,可能每種型別的監控資訊都不太一樣。
- 有些NoSQL資料庫已經具有部分關係資料庫的關係查詢特性,他們的功能介於key-value和關係資料庫之間,卻具有key-value資料庫的效能,基本能滿足絕大部分web 2.0網站的查詢需求。
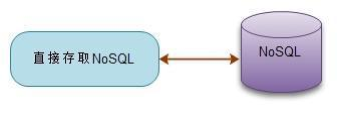
純Nosql架構
3.2 以NoSQL為資料來源的架構(Nosql為主)
- 資料直接寫入NoSQL,再通過NoSQL同步協議複製到其他儲存。
- 根據應用的邏輯來決定去相應的儲存獲取資料。
- 應用程式只負責把資料直接寫入到NoSQL資料庫,然後通過NoSQL的複製協議,把NoSQL資料的每次寫入,更新,刪除操作都複製到MySQL資料庫中。
- 同時,也可以通過複製協議把資料同步複製到全文檢索實現強大的檢索功能。
- 這種架構需要考慮資料複製的延遲問題,這跟使用MySQL的mastersalve模式的延遲問題是一樣的,解決方法也一樣。
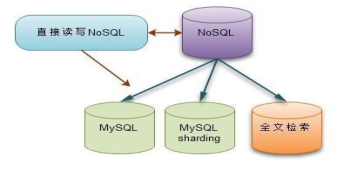
Nosql為主
3.3 NoSQL作為映象(nosql為輔)
- 不改變原有的以MySQL作為儲存的架構,使用NoSQL作為輔助映象儲存,用NoSQL的優勢輔助提升效能。
- 在原有基於MySQL資料庫的架構上增加了一層輔助的NoSQL儲存。
- 在寫入MySQL資料庫後,同時寫入到NoSQL資料庫,讓MySQL和NoSQL擁有相同的映象資料。
- 在某些可以根據主鍵查詢的地方,使用高效的NoSQL資料庫查詢。
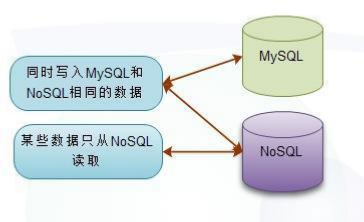
Nosql為輔
3.4 NoSQL為映象(同步模式,nosql為輔)
- 通過MySQL把資料同步到NoSQL中, ,是一種對寫入透明但是具有更高技術難度一種模式
- 適用於現有的比較複雜的老系統,通過修改程式碼不易實現,可能引起新的問題。同時也適用於需要把資料同步到多種型別的儲存中。
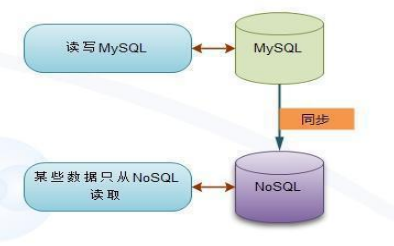
同步模式,Nosql為輔
3.5 MySQL和NoSQL組合(nosql為輔)
- MySQL中只儲存需要查詢的小欄位,NoSQL儲存所有資料。
- 把需要查詢的欄位,一般都是數字,時間等型別的小欄位儲存於MySQL中,根據查詢建立相應的索引,
- 其他不需要的欄位,包括大文字欄位都儲存在NoSQL中。
- 在查詢的時候,我們先從MySQL中查詢出資料的主鍵,然後從NoSQL中直接取出對應的資料即可。
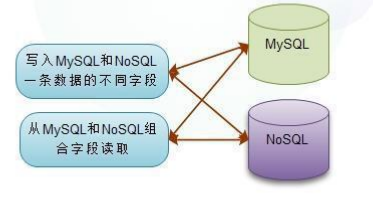
Nosql為輔
3.6 其他應用
由於NoSQL資料庫天生具有高效能、易擴充套件的特點,所以我們常常結合關係資料庫,儲存一些高效能的、海量的資料。 從另外一個角度看,根據NoSQL的高效能特點,它同樣適合用於快取資料。用NoSQL快取資料可以分為記憶體模式和磁碟持久化模式。記憶體模式
- Memcached提供了相當高的讀寫效能,在網際網路發展過程中,一直是快取伺服器的首選。
- NoSQL資料庫Redis又為我們提供了功能更加強大的記憶體儲存功能。跟Memcached比,Redis的一個key的可以儲存多種資料結構Strings、Hashes、Lists、Sets、Sorted sets。
- Redis不但功能強大,而且它的效能完全超越大名鼎鼎的Memcached。
- Redis支援List、hashes等多種資料結構的功能,提供了更加易於使用的api和操作效能,比如對快取的list資料的修改。
持久化模式
- 雖然基於記憶體的快取伺服器具有高效能,低延遲的特點,但是記憶體成本高、記憶體資料易失卻不容忽視。
- 大部分網際網路應用的特點都是資料訪問有熱點,也就是說,只有一部分資料是被頻繁訪問的。
- 其實NoSQL資料庫內部也是通過記憶體快取來提高效能的,通過一些比較好的演算法
- 把熱點資料進行記憶體cache
- 非熱點資料儲存到磁碟
- 以節省記憶體佔用
- 使用NoSQL來做快取,由於其不受記憶體大小的限制,我們可以把一些不常訪問、不怎麼更新的資料也快取起來。
四、redis
4.1 什麼是redis?
redis是一個key-value儲存系統。和Memcached類似,它支援儲存的value型別相對更多,包括string(字串)、list(連結串列)、set(集合)、zset(sortedset --有序集合)和hash(雜湊型別)。這些資料型別都支援push/pop、add/remove及取交集並集和差集及更豐富的操作,而且這些操作都是原子性的。在此基礎上,redis支援各種不同方式的排序。與memcached一樣,為了保證效率,資料都是快取在記憶體中。區別的是redis會週期性的把更新的資料寫入磁碟或者把修改操作寫入追加的記錄檔案,並且在此基礎上實現了master-slave(主從)同步。 Redis 是一個高效能的key-value資料庫。 redis的出現,很大程度補償了memcached這類key/value儲存的不足,在部 分場合可以對關係資料庫起到很好的補充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客戶端,使用很方便。 Redis支援主從同步。資料可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層樹複製。存檔可以有意無意的對資料進行寫操作。由於完全實現了釋出/訂閱機制,使得從資料庫在任何地方同步樹時,可訂閱一個頻道並接收主伺服器完整的訊息釋出記錄。同步對讀取操作的可擴充套件性和資料冗餘很有幫助。 redis的官網地址,非常好記,是redis.io。 目前,Vmware在資助著redis專案的開發和維護。
4.2 redis的特性
- 完全居於記憶體,資料實時的讀寫記憶體,定時閃回到檔案中。採用單執行緒,避免了不必要的上下文切換和競爭條件;
- 支援高併發量,官方宣傳支援10萬級別的併發讀寫;
- 支援持久儲存,機器重啟後的,重新載入模式,不會掉資料;
- 海量資料儲存,分散式系統支援,資料一致性保證,方便的叢集節點新增/刪除;
- Redis不僅僅支援簡單的k/v型別的資料,同時還提供list,set,zset,hash等資料結構的儲存;
- 災難恢復–memcache掛掉後,資料不可恢復; redis資料丟失後可以通過aof恢復;
- 虛擬記憶體–Redis當實體記憶體用完時,可以將一些很久沒用到的value 交換到磁碟;
- Redis支援資料的備份,即master-slave模式的資料備份。
4.3 redis的架構
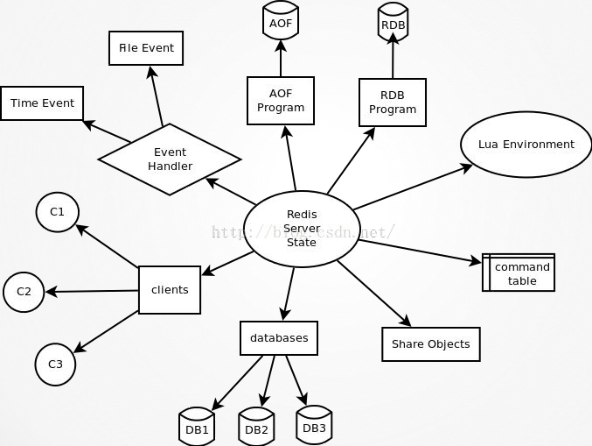
redis的架構
各功能模組說明如下:File Event: 處理檔案事件,接受它們發來的命令請求(讀事件),並將命令的執行結果返回給客戶端(寫事件))Time Event: 時間事件(更新統計資訊,清理過期資料,附屬節點同步,定期持久化等)AOF: 命令日誌的資料持久化RDB:實際的資料持久化Lua Environment : Lua 指令碼的執行環境. 為了讓 Lua 環境符合 Redis 指令碼功能的需求,Redis 對 Lua 環境進行了一系列的修改,包括新增函式庫、更換隨機函式、保護全域性變數,等等Command table(命令表):在執行命令時,根據字元來查詢相應命令的實現函式。Share Objects(物件共享):
主要儲存常見的值:
a.各種命令常見的返回值,例如返回值OK、ERROR、WRONGTYPE等字元;
b. 小於 redis.h/REDIS_SHARED_INTEGERS (預設1000)的所有整數。通過預分配的一些常見的值物件,並在多個數據結構之間共享物件,程式避免了重複分配的麻煩。也就是說,這些常見的值在記憶體中只有一份。Databases:Redis資料庫是真正儲存資料的地方。當然,資料庫本身也是儲存在記憶體中的。
4.4 redis 啟動流程
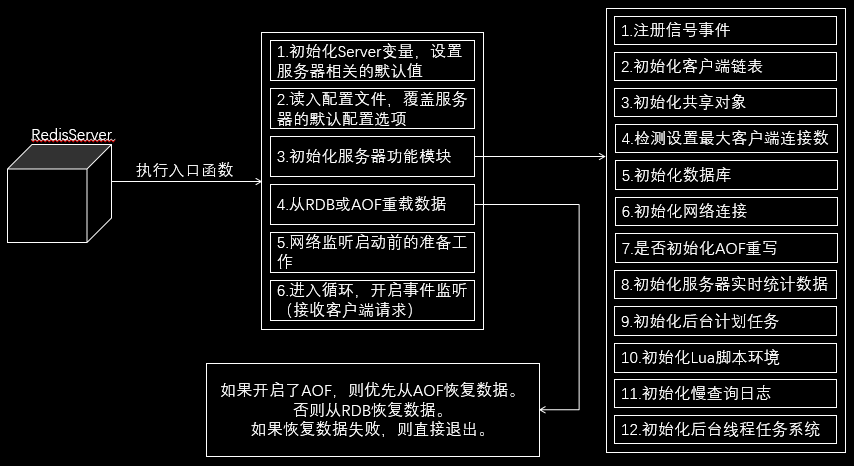
redis啟動流程
4.5 redis 安裝方式
redis安裝常用兩種方式,yum安裝和原始碼包安裝 yum 安裝:通常是線上安裝,好處是安裝方式簡單,不易出錯;常用的安裝yum源為epel。 原始碼包安裝:是先將 redis 的原始碼下載下來,在自己的系統裡編譯生成可執行檔案,然後執行,好處是因為是在自己的系統上編譯的,更符合自己系統的效能,也就是說在自己的系統上執行 redis 服務效能效率更好。 區別:路徑和啟動方式不同,支援的模組也不同。
4.5.1 redis 程式路徑
配置檔案:
/etc/redis.conf主程式:/usr/bin/redis-server客戶端:/usr/bin/redis-cliUnitFile:/usr/lib/systemd/system/redis.service資料目錄:/var/lib/redis監聽:6379/tcp
4.6 redis 配置檔案
4.6.1 網路配置項(NETWORK)
### NETWORK ###
bind IP #監聽地址
port PORT #監聽埠
protected-mode yes #是否開啟保護模式,預設開啟。要是配置裡沒有指定bind和密碼。開啟該引數後,redis只會本地進行訪問,拒絕外部訪問。
tcp-backlog 511 #定義了每一個埠最大的監聽佇列的長度
unixsocket /tmp/redis.sock #也可以開啟套接字監聽
timeout 0 #連線的空閒超時時長;

網路配置項
4.6.2 通用配置項(GENERAL)
### GENERAL ###
daemonize no #是否以守護程序啟動
supervised no #可以通過upstart和systemd管理Redis守護程序,這個引數是和具體的作業系統相關的
pidfile "/var/run/redis/redis.pid" #pid檔案
loglevel notice #日誌等級
logfile "/var/log/redis/redis.log" #日誌存放檔案
databases 16 #設定資料庫數量,預設為16個,每個資料庫的名字均為整數,從0開始編號,預設操作的資料庫為0;
切換資料庫的方法:SELECT <dbid>
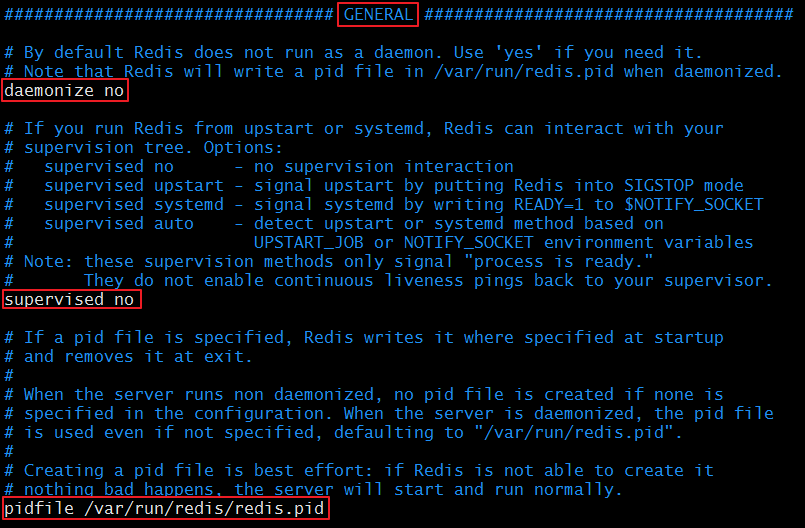
通用配置項
4.6.3 快照配置(SNAPSHOTTING)
### SNAPSHOTTING ###
save 900 1 #900秒有一個key變化,就做一個儲存
save 300 10 #300秒有10個key變化,就做一個儲存,這裡需要和開發溝通
save 60 10000 #60秒有10000個key變化就做一個儲存
stop-writes-on-bgsave-error yes #在出現錯誤的時候,是不是要停止儲存
rdbcompression yes #使用壓縮rdb檔案,rdb檔案壓縮使用LZF壓縮演算法,yes:壓縮,但是需要一些cpu的消耗;no:不壓縮,需要更多的磁碟空間
rdbchecksum yes #是否校驗rdb檔案。從rdb格式的第五個版本開始,在rdb檔案的末尾會帶上CRC64的校驗和。這跟有利於檔案的容錯性,但是在儲存rdb檔案的時候,會有大概10%的效能損耗,所以如果你追求高效能,可以關閉該配置。
dbfilename "along.rdb" #rdb檔案的名稱
dir "/var/lib/redis" #資料目錄,資料庫的寫入會在這個目錄。rdb、aof檔案也會寫在這個目錄
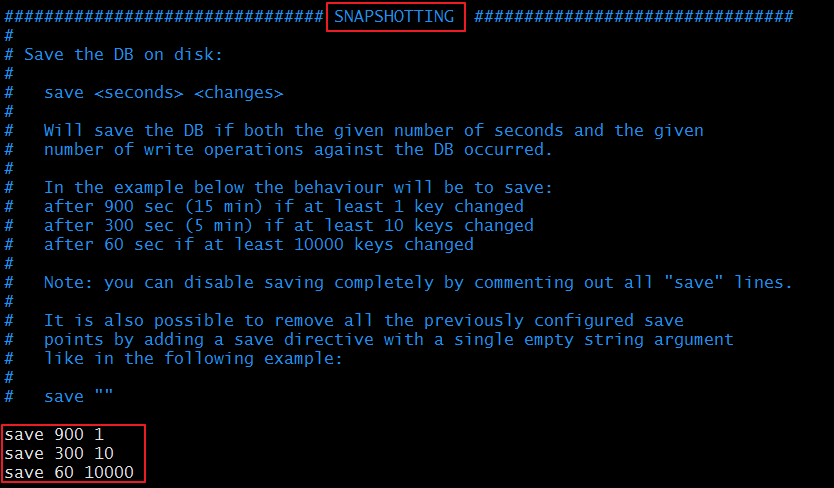
快照配置
4.6.4 限制相關配置(LIMITS)
### LIMITS ###
maxclients 10000 #設定能連上redis的最大客戶端連線數量
maxmemory <bytes> #redis配置的最大記憶體容量。當記憶體滿了,需要配合maxmemory-policy策略進行處理。
maxmemory-policy noeviction #淘汰策略:volatile-lru, allkeys-lru, volatile-random, allkeys-random, volatile-ttl, noeviction
記憶體容量超過maxmemory後的處理策略:
① # volatile-lru:利用LRU演算法移除設定過過期時間的key。
② # volatile-random:隨機移除設定過過期時間的key。
③ # volatile-ttl:移除即將過期的key,根據最近過期時間來刪除(輔以TTL)
④ # allkeys-lru:利用LRU演算法移除任何key。
⑤ # allkeys-random:隨機移除任何key。
⑥ # noeviction:不移除任何key,只是返回一個寫錯誤。
# 上面的這些驅逐策略,如果redis沒有合適的key驅逐,對於寫命令,還是會返回錯誤。redis將不再接收寫請求,只接收get請求。寫命令包括:set setnx
maxmemory-samples 5 #淘汰演算法執行時的取樣樣本數;

限制相關配置
4.6.5 持久化配置(APPEND ONLY MODE)
### APPEND ONLY MODE ###
# 預設redis使用的是rdb方式持久化,這種方式在許多應用中已經足夠用了。但是redis如果中途宕機,會導致可能有幾分鐘的資料丟失,根據save來策略進行持久化,Append Only File是另一種持久化方式,可以提供更好的持久化特性。Redis會把每次寫入的資料在接收後都寫入 appendonly.aof 檔案,每次啟動時Redis都會先把這個檔案的資料讀入記憶體裡,先忽略RDB檔案。
appendonly no #不啟動aof模式
appendfilename "appendonly.aof" #據讀入記憶體裡,先忽略RDB檔案,aof檔名(default: "appendonly.aof")
appendfsync
Redis supports three different modes:
no:redis不執行主動同步操作,而是OS進行;
everysec:每秒一次;
always:每語句一次;
如果Redis只是將客戶端修改資料庫的指令重現儲存在AOF檔案中,那麼AOF檔案的大小會不斷的增加,因為AOF檔案只是簡單的重現儲存了客戶端的指令,而並沒有進行合併。對於該問題最簡單的處理方式,即當AOF檔案滿足一定條件時就對AOF進行rewrite,rewrite是根據當前記憶體資料庫中的資料進行遍歷寫到一個臨時的AOF檔案,待寫完後替換掉原來的AOF檔案即可。 redis重寫會將多個key、value對集合來用一條命令表達。在rewrite期間的寫操作會儲存在記憶體的rewrite buffer中,rewrite成功後這些操作也會複製到臨時檔案中,在最後臨時檔案會代替AOF檔案。
no-appendfsync-on-rewrite no
#在aof重寫或者寫入rdb檔案的時候,會執行大量IO,此時對於everysec和always的aof模式來說,執行fsync會造成阻塞過長時間,no-appendfsync-on-rewrite欄位設定為預設設定為no。如果對延遲要求很高的應用,這個欄位可以設定為yes,否則還是設定為no,這樣對持久化特性來說這是更安全的選擇。設定為yes表示rewrite期間對新寫操作不fsync,暫時存在記憶體中,等rewrite完成後再寫入,預設為no,建議yes。Linux的預設fsync策略是30秒。可能丟失30秒資料。
auto-aof-rewrite-percentage 100 aof自動重寫配置。當目前aof檔案大小超過上一次重寫的aof檔案大小的百分之多少進行重寫,即當aof檔案增長到一定大小的時候Redis能夠呼叫bgrewrite aof對日誌檔案進行重寫。當前AOF檔案大小是上次日誌重寫得到AOF檔案大小的二倍(設定為100)時,自動啟動新的日誌重寫過程。
auto-aof-rewrite-min-size 64mb #設定允許重寫的最小aof檔案大小,避免了達到約定百分比但尺寸仍然很小的情況還要重寫。上述兩個條件同時滿足時,方會觸發重寫AOF;與上次aof檔案大小相比,其增長量超過100%,且大小不少於64MB;
aof-load-truncated yes #指redis在恢復時,會忽略最後一條可能存在問題的指令。aof檔案可能在尾部是不完整的,出現這種現象,可以選擇讓redis退出,或者匯入儘可能多的資料。如果選擇的是yes,當截斷的aof檔案被匯入的時候,會自動釋出一個log給客戶端然後load。
如果是no,使用者必須手動redis-check-aof修復AOF檔案才可以。
注意:持久機制本身不能取代備份;應該制訂備份策略,對redis庫定期備份;Redis伺服器啟動時用持久化的資料檔案恢復資料,會優先使用AOF;
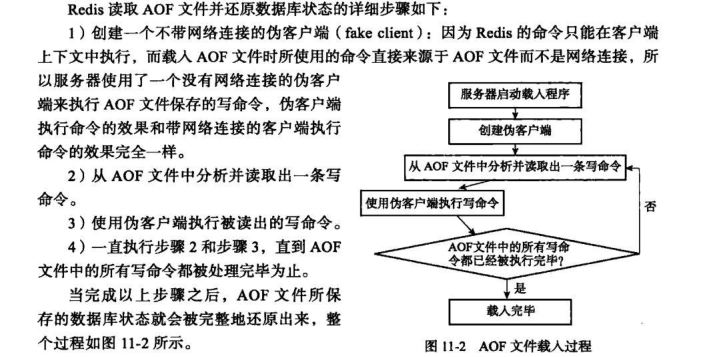
redis 持久化儲存讀取
我們繼續來看 redis 的持久化:RDB:snapshotting, 二進位制格式;按事先定製的策略,週期性地將資料從記憶體同步至磁碟;資料檔案預設為dump.rdb; 客戶端顯式使用SAVE或BGSAVE命令來手動啟動快照儲存機制; SAVE:同步,即在主執行緒中儲存快照,此時會阻塞所有客戶端請求; BGSAVE:非同步;backgroudAOF:Append Only File, fsync 記錄每次寫操作至指定的檔案尾部實現的持久化;當redis重啟時,可通過重新執行檔案中的命令在記憶體中重建出資料庫; BGREWRITEAOF:AOF檔案重寫; 不會讀取正在使用AOF檔案,而是通過將記憶體中的資料以命令的方式儲存至臨時檔案中,完成之後替換原來的AOF檔案;
4.6.6 慢查詢日誌相關配置(SLOW LOG)
### SLOW LOG ###
slowlog-log-slower-than 10000 #當命令的執行超過了指定時間,單位是微秒;1s=10^6微秒
slowlog-max-len 128 #慢查詢日誌長度。當一個新的命令被寫進日誌的時候,最老的那個記錄會被刪掉。
ADVANCED配置:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
設定ziplist的鍵數量最大值,每個值的最大空間;
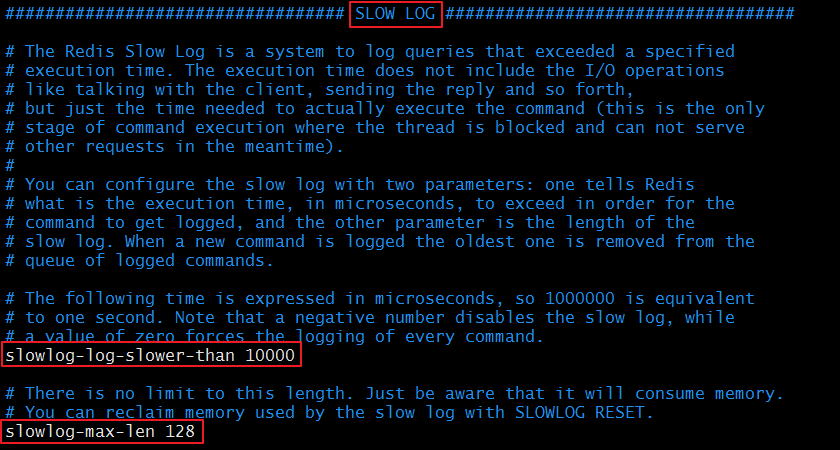
慢查詢日誌相關配置
4.7 redis命令介紹
└── bin ├── redis-benchmark #redis效能測試工具,可以測試在本系統本配置下的讀寫效能 ├── redis-check-aof #對更新日誌appendonly.aof檢查,是否可用 ├── redis-check-dump #用於檢查本地資料庫的rdb檔案 ├── redis-cli #redis命令列操作工具,也可以用telnet根據其純文字協議來操作 ├── redis-sentinel Redis-sentinel 是Redis例項的監控管理、通知和例項失效備援服務,是Redis叢集的管理工具 └── redis-server #redis伺服器的daemon啟動程式
4.7.1 redis-cli命令介紹
redis-cli -p 6379 #預設選擇 db庫是 0 redis 127.0.0.1:6379> keys * #檢視當前所在“db庫”所有的快取key redis 127.0.0.1:6379> select 8 #選擇 db庫 redis 127.0.0.1:6379> FLUSHALL #清除所有的快取key redis 127.0.0.1:63798> FLUSHDB #清除當前“db庫”所有的快取key redis 127.0.0.1:6379> set keyname keyvalue #設定快取值 redis 127.0.0.1:6379> get keyname #獲取快取值 redis 127.0.0.1:6379> del keyname #刪除快取值:返回刪除數量(0代表沒刪除)
{kind=link}
服務端的相關命令:
time:返回當前伺服器時間client list: 返回所有連線到伺服器的客戶端資訊和統計資料 參見http://redisdoc.com/server/client_list.htmlclient kill ip:port:關閉地址為 ip:port 的客戶端save:將資料同步儲存到磁碟bgsave:將資料非同步儲存到磁碟lastsave:返回上次成功將資料儲存到磁碟的Unix時戳shundown:將資料同步儲存到磁碟,然後關閉服務info:提供伺服器的資訊和統計config resetstat:重置info命令中的某些統計資料config get:獲取配置檔案資訊config set:動態地調整 Redis 伺服器的配置(configuration)而無須重啟,可以修改的配置引數可以使用命令 CONFIG GET * 來列出config rewrite:Redis 伺服器時所指定的 redis.conf 檔案進行改寫monitor:實時轉儲收到的請求slaveof:改變複製策略設定debug:sleep segfaultslowlog get:獲取慢查詢日誌slowlog len:獲取慢查詢日誌條數slowlog reset:清空慢查詢
4.8 redis 常用資料型別
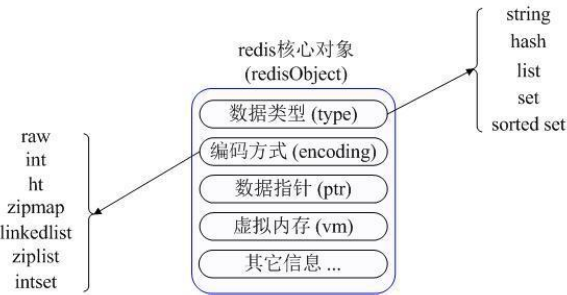
redis 常用資料型別
Redis內部使用一個redisObject物件來表示所有的key和value,redisObject最主要的資訊如上圖所示: type代表一個value物件具體是何種資料型別 encoding是不同資料型別在redis內部的儲存方式 比如:type=string代表value儲存的是一個普通字串,那麼對應的encoding可以是raw或者是int,如果是int則代表實際redis內部是按數值型類儲存和表示這個字串的,當然前提是這個字串本身可以用數值表示,比如:“123” "456"這樣的字串。 Redis的鍵值可以使用物種資料型別:字串,散列表,列表,集合,有序集合。
4.8.1 對KEY操作的命令
exists(key):確認一個key是否存在del(key):刪除一個keytype(key):返回值的型別keys(pattern):返回滿足給定pattern的所有keyrandomkey:隨機返回key空間的一個keyrename(oldname, newname):重新命名keydbsize:返回當前資料庫中key的數目expire:設定一個key的活動時間(s)ttl:獲得一個key的活動時間move(key, dbindex):移動當前資料庫中的key到dbindex資料庫flushdb:刪除當前選擇資料庫中的所有keyflushall:刪除所有資料庫中的所有key
4.8.2 對String操作的命令
應用場景:String是最常用的一種資料型別,普通的key/ value 儲存都可以歸為此類.即可以完全實現目前 Memcached 的功能,並且效率更高。還可以享受Redis的定時持久化,操作日誌及 Replication等功能。除了提供與 Memcached 一樣的get、set、incr、decr 等操作外,Redis還提供了下面一些操作:
set(key, value):給資料庫中名稱為key的string賦予值value get(key):返回資料庫中名稱為key的string的value
getset(key, value):給名稱為key的string賦予上一次的valuemget(key1, key2,…, key N):返回庫中多個string的valuesetnx(key, value):新增string,名稱為key,值為valuesetex(key, time, value):向庫中新增string,設定過期時間timemset(key N, value N):批量設定多個string的值msetnx(key N, value N):如果所有名稱為key i的string都不存在incr(key):名稱為key的string增1操作incrby(key, integer):名稱為key的string增加integerdecr(key):名稱為key的string減1操作decrby(key, integer):名稱為key的string減少integerappend(key, value):名稱為key的string的值附加valuesubstr(key, start, end):返回名稱為key的string的value的子串
4.8.3 對Hash操作的命令
應用場景:在Memcached中,我們經常將一些結構化的資訊打包成HashMap,在客戶端序列化後儲存為一個字串的值,比如使用者的暱稱、年齡、性別、積分等,這時候在需要修改其中某一項時,通常需要將所有值取出反序列化後,修改某一項的值,再序列化儲存回去。這樣不僅增大了開銷,也不適用於一些可能併發操作的場合(比如兩個併發的操作都需要修改積分)。而Redis的Hash結構可以使你像在資料庫中Update一個屬性一樣只修改某一項屬性值。
hset(key, field, value):向名稱為key的hash中新增元素fieldhget(key, field):返回名稱為key的hash中field對應的valuehmget(key, (fields)):返回名稱為key的hash中field i對應的valuehmset(key, (fields)):向名稱為key的hash中新增元素fieldhincrby(key, field, integer):將名稱為key的hash中field的value增加integerhexists(key, field):名稱為key的hash中是否存在鍵為field的域hdel(key, field):刪除名稱為key的hash中鍵為field的域hlen(key):返回名稱為key的hash中元素個數hkeys(key):返回名稱為key的hash中所有鍵hvals(key):返回名稱為key的hash中所有鍵對應的valuehgetall(key):返回名稱為key的hash中所有的鍵(field)及其對應的value
4.8.4 對List操作的命令
Redis list的應用場景非常多,也是Redis最重要的資料結構之一,比如twitter的關注列表,粉絲列表等都可以用Redis的list結構來實現。我們在看完一條微博之後,常常會評論一番,或者看看其他人的吐槽。每條評論的記錄都是按照時間順序排序的。 具體操作命令如下:
rpush(key, value):在名稱為key的list尾新增一個值為value的元素lpush(key, value):在名稱為key的list頭新增一個值為value的 元素llen(key):返回名稱為key的list的長度lrange(key, start, end):返回名稱為key的list中start至end之間的元素ltrim(key, start, end):擷取名稱為key的listlindex(key, index):返回名稱為key的list中index位置的元素lset(key, index, value):給名稱為key的list中index位置的元素賦值lrem(key, count, value):刪除count個key的list中值為value的元素lpop(key):返回並刪除名稱為key的list中的首元素rpop(key):返回並刪除名稱為key的list中的尾元素blpop(key1, key2,… key N, timeout):lpop命令的block版本。brpop(key1, key2,… key N, timeout):rpop的block版本。rpoplpush(srckey, dstkey):返回並刪除名稱為srckey的list的尾元素,並將該元素新增到名稱為dstkey的list的頭部
4.8.5 對Set操作的命令
Set 就是一個集合,集合的概念就是一堆不重複值的組合。利用 Redis 提供的 Set 資料結構,可以儲存一些集合性的資料。比如在微博應用中,可以將一個使用者所有的關注人存在一個集合中,將其所有粉絲存在一個集合。因為 Redis 非常人性化的為集合提供了求交集、並集、差集等操作,那麼就可以非常方便的實現如共同關注、共同喜好、二度好友等功能。 具體操作命令如下:
sadd(key, member):向名稱為key的set中新增元素membersrem(key, member):刪除名稱為key的set中的元素memberspop(key):隨機返回並刪除名稱為key的set中一個元素smove(srckey, dstkey, member):移到集合元素scard(key):返回名稱為key的set的基數sismember(key, member):member是否是名稱為key的set的元素sinter(key1, key2,…key N):求交集sinterstore(dstkey, (keys)):求交集並將交集儲存到dstkey的集合sunion(key1, (keys)):求並集sunionstore(dstkey, (keys)):求並集並將並集儲存到dstkey的集合sdiff(key1, (keys)):求差集sdiffstore(dstkey, (keys)):求差集並將差集儲存到dstkey的集合smembers(key):返回名稱為key的set的所有元素srandmember(key):隨機返回名稱為key的set的一個元素
五、redis 主從複製
5.1 方式簡介
Redis的複製方式有兩種,一種是主(master)-從(slave)模式,一種是從(slave)-從(slave)模式,因此Redis的複製拓撲圖會豐富一些,可以像星型拓撲,也可以像個有向無環。一個Master可以有多個slave主機,支援鏈式複製;Master以非阻塞方式同步資料至slave主機; 拓撲圖如下:
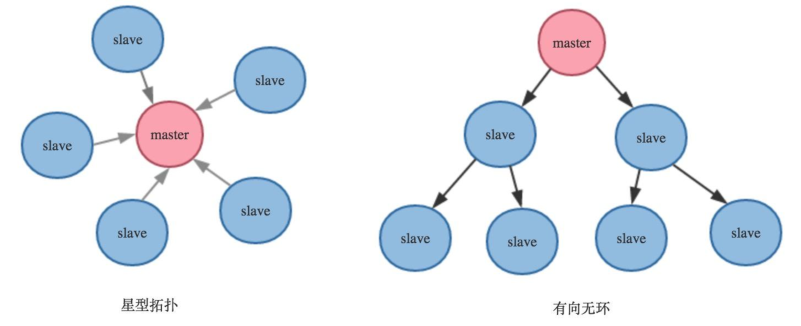
拓撲圖
5.2 複製優點
通過配置多個Redis例項,資料備份在不同的例項上,主庫專注寫請求,從庫負責讀請求,這樣的好處主要體現在下面幾個方面1. 高可用性 在一個Redis叢集中,如果master宕機,slave可以介入並取代master的位置,因此對於整個Redis服務來說不至於提供不了服務,這樣使得整個Redis服務足夠安全。2. 高效能 在一個Redis叢集中,master負責寫請求,slave負責讀請求,這麼做一方面通過將讀請求分散到其他機器從而大大減少了master伺服器的壓力,另一方面slave專注於提供讀服務從而提高了響應和讀取速度。3. 水平擴充套件性 通過增加slave機器可以橫向(水平)擴充套件Redis服務的整個查詢服務的能力。
5.3 需要解決的問題
複製提供了高可用性的解決方案,但同時引入了分散式計算的複雜度問題,認為有兩個核心問題:1. 資料一致性問題: 如何保證master伺服器寫入的資料能夠及時同步到slave機器上。2. 讀寫分離: 如何在客戶端提供讀寫分離的實現方案,通過客戶端實現將讀寫請求分別路由到master和slave例項上。 上面兩個問題,尤其是第一個問題是Redis服務實現一直在演變,致力於解決的一個問題:複製實時性和資料一致性矛盾。
Redis提供了提高資料一致性的解決方案,一致性程度的增加雖然使得我能夠更信任資料,但是更好的一致性方案通常伴隨著效能的損失,從而減少了吞吐量和服務能力。然而我們希望系統的效能達到最優,則必須要犧牲一致性的程度,因此Redis的複製實時性和資料一致性是存在矛盾的。
5.4 具體例項見實戰一
六、redis叢集cluster
如何解決redis橫向擴充套件的問題----redis叢集實現方式
6.1 實現基礎——分割槽
分割槽是分割資料到多個Redis例項的處理過程,因此每個例項只儲存key的一個子集。通過利用多臺計算機記憶體的和值,允許我們構造更大的資料庫。通過多核和多臺計算機,允許我們擴充套件計算能力;通過多臺計算機和網路介面卡,允許我們擴充套件網路頻寬。 叢集的幾種實現方式:
- 客戶端分片
- 基於代理的分片
- 路由查詢
6.1.1 客戶端分片
由客戶端決定key寫入或者讀取的節點。 包括jedis在內的一些客戶端,實現了客戶端分片機制。優點 簡單,效能高缺點 1. 業務邏輯與資料儲存邏輯耦合 2. 可運維性差 3. 多業務各自使用redis,叢集資源難以管理 4. 不支援動態增刪節點
客戶端分片
6.1.2 基於代理的分片
客戶端傳送請求到一個代理,代理解析客戶端的資料,將請求轉發至正確的節點,然後將結果回覆給客戶端。開源方案 1. Twemproxy 2. codis特性 1. 透明接入 2. 業務程式不用關心後端Redis例項,切換成本低。 3. Proxy 的邏輯和儲存的邏輯是隔離的。 4. 代理層多了一次轉發,效能有所損耗。
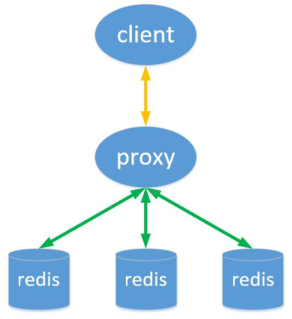
基於代理的分片
Twemproxy Proxy-based twtter開源,C語言編寫,單執行緒。 支援 Redis 或 Memcached 作為後端儲存。優點: 1. 支援失敗節點自動刪除 2. 與redis的長連線,連線複用,連線數可配置 3. 自動分片到後端多個redis例項上 4. 多種hash演算法:能夠使用不同的分片策略和雜湊函式 5. 可以設定後端例項的權重缺點: 1. 效能低:代理層損耗 && 本身效率低下 2. Redis功能支援不完善:不支援針對多個值的操作 3. 本身不提供動態擴容,透明資料遷移等功能
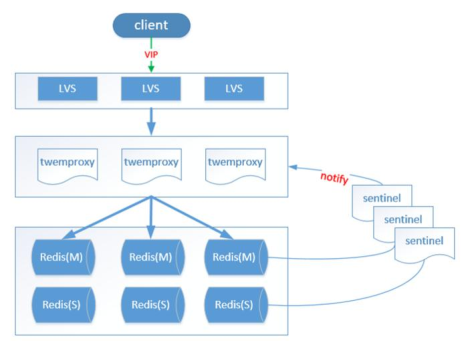
Twemproxy
Codis Codis由豌豆莢於2014年11月開源,基於Go和C開發,是近期湧現的、國人開發的優秀開源軟體之一。現已廣泛用於豌豆莢的各種Redis業務場景。從3個月的各種壓力測試來看,穩定性符合高效運維的要求。效能更是改善很多,最初比Twemproxy慢20%;現在比Twemproxy快近100%(條件:多例項,一般Value長度)。
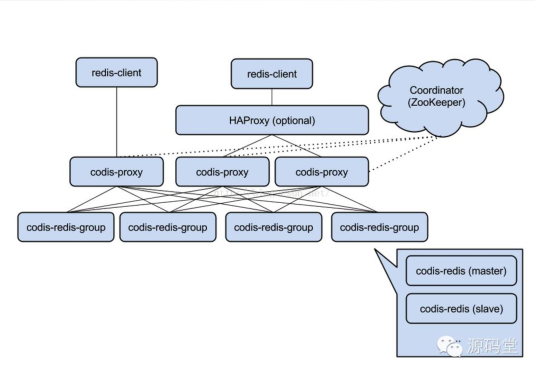
Codis
6.2 開源方案——Redis-cluster
將請求傳送到任意節點,接收到請求的節點會將查詢請求傳送到正確的節點上執行。
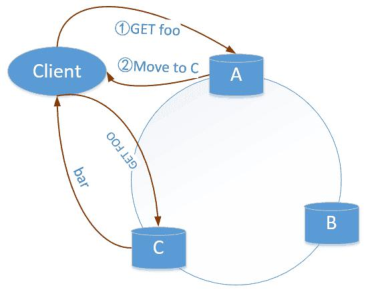
Redis-cluster原理圖
Redis-cluster由redis官網推出,可線性擴充套件到1000個節點。無中心架構;使用一致性雜湊思想;客戶端直連redis服務,免去了proxy代理的損耗。
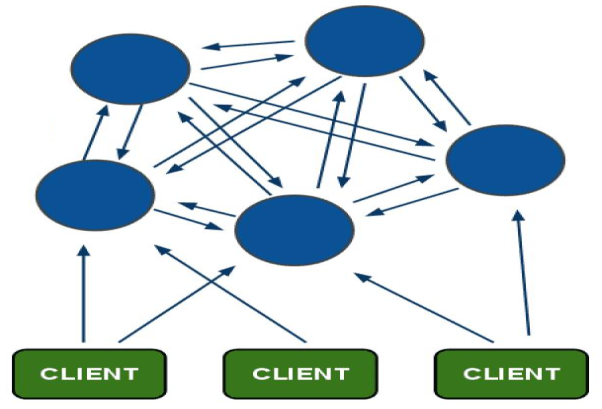
Redis-cluster架構
6.2.1 Redis叢集介紹
Redis 叢集是一個提供在多個Redis間節點間共享資料的程式集。 Redis 叢集並不支援處理多個keys的命令,因為這需要在不同的節點間移動資料,從而達不到像Redis那樣的效能,在高負載的情況下可能會導致不可預料的錯誤。 Redis 叢集通過分割槽來提供一定程度的可用性,在實際環境中當某個節點宕機或者不可達的情況下繼續處理命令.Redis 叢集的優勢: 1. 自動分割資料到不同的節點上。 2. 整個叢集的部分節點失敗或者不可達的情況下能夠繼續處理命令。Redis 叢集的資料分片 Redis 叢集沒有使用一致性hash,而是引入了雜湊槽的概念. Redis 叢集有16384個雜湊槽,每個key通過CRC16校驗後對16384取模來決定放置哪個槽。叢集的每個節點負責一部分hash槽。舉個例子,比如當前叢集有3個節點,那麼: 節點 A 包含 0 到 5500號雜湊槽。 節點 B 包含5501 到 11000 號雜湊槽。 節點 C 包含11001 到 16384號雜湊槽。 這種結構很容易新增或者刪除節點。比如如果我想新添加個節點D,我需要從節點 A,B,C中得部分槽到D上。如果我想移除節點A,需要將A中得槽移到B和C節點上,然後將沒有任何槽的A節點從叢集中移除即可。由於從一個節點將雜湊槽移動到另一個節點並不會停止服務,所以無論新增刪除或者改變某個節點的雜湊槽的數量都不會造成叢集不可用的狀態。
6.2.2 Redis 叢集的主從複製模型
為了使在部分節點失敗或者大部分節點無法通訊的情況下叢集仍然可用,所以叢集使用了主從複製模型,每個節點都會有N-1個複製品。 在我們例子中具有A,B,C三個節點的叢集,在沒有複製模型的情況下,如果節點B失敗了,那麼整個叢集就會以為缺少5501-11000這個範圍的槽而不可用。 然而如果在叢集建立的時候(或者過一段時間)我們為每個節點新增一個從節點A1,B1,C1,那麼整個叢集便有三個master節點和三個slave節點組成,這樣在節點B失敗後,叢集便會選舉B1為新的主節點繼續服務,整個叢集便不會因為槽找不到而不可用了。不過當B和B1 都失敗後,叢集是不可用的。 Redis 一致性保證 Redis 並不能保證資料的強一致性. 這意味這在實際中叢集在特定的條件下可能會丟失寫操作。 第一個原因是因為叢集是用了非同步複製. 寫操作過程: 客戶端向主節點B寫入一條命令. 主節點B向客戶端回覆命令狀態. 主節點將寫操作複製給他得從節點 B1, B2 和 B3. 主節點對命令的複製工作發生在返回命令回覆之後, 因為如果每次處理命令請求都需要等待複製操作完成的話,那麼主節點處理命令請求的速度將極大地降低 —— 我們必須在效能和一致性之間做出權衡。注意:Redis 叢集可能會在將來提供同步寫的方法。Redis 叢集另外一種可能會丟失命令的情況是叢集出現了網路分割槽, 並且一個客戶端與至少包括一個主節點在內的少數例項被孤立。
實戰一:redis主從複製的實現
1)原理架構圖
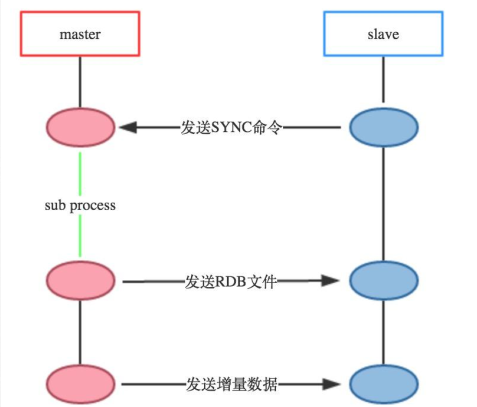
原理架構圖
上圖為Redis複製工作過程:
- slave向master傳送sync命令。
- master開啟子程序來講dataset寫入rdb檔案,同時將子程序完成之前接收到的寫命令快取起來。
- 子程序寫完,父程序得知,開始將RDB檔案傳送給slave。master傳送完RDB檔案,將快取的命令也發給slave。master增量的把寫命令發給slave。
值得注意的是,當slave跟master的連線斷開時,slave可以自動的重新連線master,在redis2.8版本之前,每當slave程序掛掉重新連線master的時候都會開始新的一輪全量複製。如果master同時接收到多個slave的同步請求,則master只需要備份一次RDB檔案。
2)實驗準備
環境準備
centos系統伺服器2臺、 一臺用於做redis主伺服器, 一臺用於做redis從伺服器, 配置好yum源、 防火牆關閉、 各節點時鐘服務同步、 各節點之間可以通過主機名互相通訊。
具體設定如下
| 機器名稱 | IP配置 | 服務角色 |
|---|---|---|
| redis-master | 192.168.37.111 | redis主伺服器 |
| redis-slave1 | 192.168.37.122 | 檔案存放 |
| redis-slave2 | 192.168.37.133 | 檔案存放 |
3)在所有機器上進行基本配置
首先,在所有機器上安裝redis:
yum install -y redis
然後我們把配置檔案備份一下,這樣便於我們日後的恢復,是一個好習慣!
cp /etc/redis.conf{,.back}
接著,我們去修改一下配置檔案,更改如下配置:
vim /etc/redis.conf #配置配置檔案,修改2項
bind 0.0.0.0 #監聽地址(可以寫0.0.0.0,監聽所有地址;也可以各自寫各自的IP)
daemonize yes #後臺守護程序執行
三臺機器都進行修改以後,本步驟完成。
4)配置從伺服器
我們還需要在從伺服器上進行一些配置來實現主從同步,具體操作步驟如下:
vim /etc/redis.conf
### REPLICATION ### 在這一段修改
slaveof 192.168.30.107 6379 #設定主伺服器的IP和埠號
#masterauth <master-password> #如果設定了訪問認證就需要設定此項。
slave-serve-stale-data yes #當slave與master連線斷開或者slave正處於同步狀態時,如果slave收到請求允許響應,no表示返回錯誤。
slave-read-only yes #slave節點是否為只讀。
slave-priority 100 #設定此節點的優先順序,是否優先被同步。
5)查詢並測試
1、開啟所有機器上的redis服務:
systemctl start redis
2、在主上登入查詢主從訊息,確認主從是否已實現:
[[email protected] ~]# redis-cli -h 192.168.37.111
192.168.37.111:6379> info replication
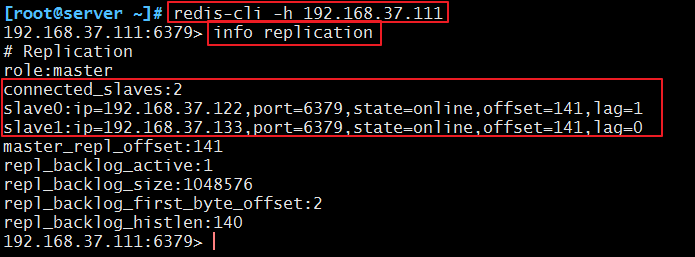
檢視主從
3、日誌中也可以檢視到:
[[email protected] ~]# tail /var/log/redis/redis.log
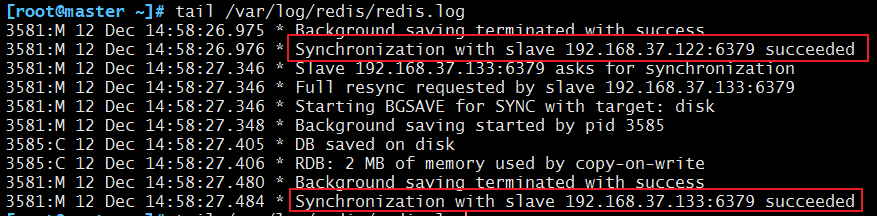
日誌檢視主從資訊
4、測試主從
在主上置一個key
[[email protected] ~]# redis-cli -h 192.168.37.111
192.168.37.111:6379> set master test
OK
192.168.37.111:6379> get master
"test"
然後去從上查詢,如果能夠查詢到,則說明成功:
[[email protected] ~]# redis-cli #因為我們設定的監聽地址是0.0.0.0,所以不需要輸入-h
127.0.0.1:6379> get master
"test"
6)高階配置(根據自己的需要進行設定)
1、一個RDB檔案從 master 端傳到 slave 端,分為兩種情況: ① 支援disk:master 端將 RDB file 寫到 disk,稍後再傳送到 slave 端; ② 無磁碟diskless:master端直接將RDB file 傳到 slave socket,不需要與 disk 進行互動。 無磁碟diskless 方式適合磁碟讀寫速度慢但網路頻寬非常高的環境。 2、設定:
repl-diskless-sync no #預設不使用diskless同步方式
repl-diskless-sync-delay 5 #無磁碟diskless方式在進行資料傳遞之前會有一個時間的延遲,以便slave端能夠進行到待傳送的目標佇列中,這個時間預設是5秒
repl-ping-slave-period 10 #slave端向server端傳送pings的時間區間設定,預設為10秒
repl-timeout 60 #設定超時時間
min-slaves-to-write 3 #主節點僅允許其能夠通訊的從節點數量大於等於此處的值時接受寫操作;
min-slaves-max-lag 10 #從節點延遲時長超出此處指定的時長時,主節點會拒絕寫入操作;
實戰二:Sentinel(哨兵)實現Redis的高可用性
1)原理及架構圖
1、原理 Sentinel(哨兵)是Redis的高可用性(HA)解決方案,由一個或多個Sentinel例項組成的Sentinel系統可以監視任意多個主伺服器,以及這些主伺服器屬下的所有從伺服器,並在被監視的主伺服器進行下線狀態時,自動將下線主伺服器屬下的某個從伺服器升級為新的主伺服器,然後由新的主伺服器代替已下線的主伺服器繼續處理命令請求。 Redis提供的sentinel(哨兵)機制,通過sentinel模式啟動redis後,自動監控master/slave的執行狀態,基本原理是:心跳機制+投票裁決 ① 監控(Monitoring): Sentinel 會不斷地檢查你的主伺服器和從伺服器是否運作正常。 ② 提醒(Notification): 當被監控的某個 Redis 伺服器出現問題時, Sentinel 可以通過 API 向管理員或者其他應用程式傳送通知。 ③ 自動故障遷移(Automatic failover): 當一個主伺服器不能正常工作時, Sentinel 會開始一次自動故障遷移操作, 它會將失效主伺服器的其中一個從伺服器升級為新的主伺服器, 並讓失效主伺服器的其他從伺服器改為複製新的主伺服器; 當客戶端試圖連線失效的主伺服器時, 叢集也會向客戶端返回新主伺服器的地址, 使得叢集可以使用新主伺服器代替失效伺服器。
2、架構流程圖 ① 正常的主從服務
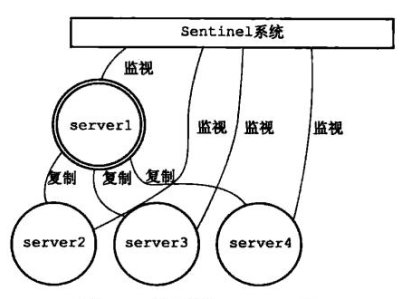
主從服務
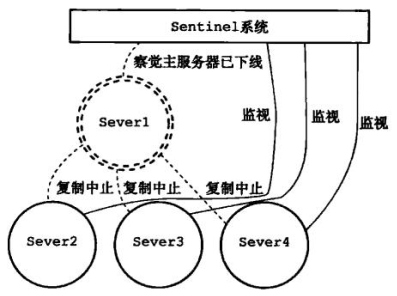
② sentinel 監控到主 redis 下線
主 redis 下線
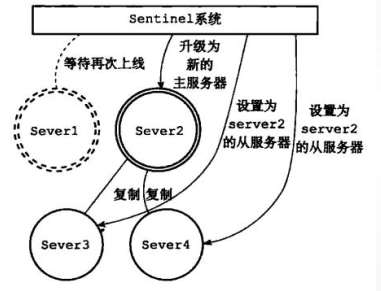
③ 由優先順序升級新主
故障轉移
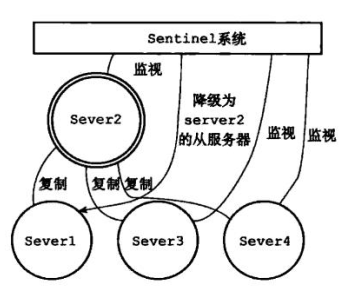
④ 舊主修復,作為從 redis,新主照常工作
舊主作為從加入叢集
2)實驗準備
環境準備
centos系統伺服器2臺、 一臺用於做redis主伺服器, 一臺用於做redis從伺服器, 配置好yum源、 防火牆關閉、 各節點時鐘服務同步、 各節點之間可以通過主機名互相通訊。
具體設定如下
| 機器名稱 | IP配置 | 服務角色 | 備註 |
|---|---|---|---|
| redis-master | 192.168.37.111 | redis主伺服器 | 開啟sentinel |
| redis-slave1 | 192.168.37.122 | 檔案存放 | 開啟sentinel |
| redis-slave2 |