
base64加密演算法C++實現
base64編碼原理:維基百科 - Base64
其實編碼規則很簡單,將字串按每三個字元組成一組,因為每個字元的 ascii 碼對應 0~127 之間(顯然,不考慮其他字符集編碼),即每個字元的二進位制以 8 bit 儲存,$ 3 \times 8 = 4 \times 6 $,這樣就可以很方便的轉為 4 個 6 bit 的字元,當一組中的字元(最後一組會出現這樣的情況)少於3個字元,則用"="字元填充。
解碼也就是一個逆過程,也不難。
既然是二進位制,顯然應該想到利用位操作。。。
注意到:
1. 6 bit 的二進位制組成的數的十進位制一定小於 64,$ (111111)_{2} = (63)_{10} $。這就是那張 base64 表的原因。
2.將前一個字元的多餘的二進位制,填充到後一位字元的二進位制的前面以填充滿 6 位,每 3 個字元為 1 週期 。
如果對位操作很熟練,那麼這個演算法會很簡單(核心部分):
unsigned bit[6] = {0u};
size_t ens = 0, i = 2u;
for (unsigned j = 0u; inputs[j]; j++)
{
int asc_ = int(inputs[j]);
unsigned inx = asc_ >> i;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i); // min: 0, max:{1, 2, 4, 8, 16, 32}
encode[ens++] = base64_table[inx];
if (i != 6) {
for (unsigned k = 0u, n = asc_; k < i; n >>= 1, k++)
bit[k] = n & 1;
i += 2;
}
else {
i = asc_;
inx = i >= 64 ? (i >= 128 ? i - 128 : i - 64) : i;
encode[ens++] = base64_table[inx];
if (inputs[j + 1] != '\0') i = 2;
}
}
下面從分析時間複雜度方向來解釋演算法:
unsigned bit[6] = {0u};
size_t ens = 0, i = 2u;
首先我們需要維護一個大小為6的無符號整形陣列 bit 來儲存6個二進位制數位;
ens 是用來維護 encode 字元陣列的棧下標;
變數 i 扮演了幾個小而十分重要的角色:判斷週期變化,維護掃描到的每一個字元當前應該做多少次的位移數,當 $ i = 6 $ ,意味著可以通過當前分組中的第3個字元的後 6 bit 編碼得到第 4 個字元,這裡為了減少區域性變數冗餘以及便利,我使用了 i 來多做了一點本不屬於它的任務。
然後進入迴圈主體
for (unsigned j = 0u; inputs[j]; j++)
迴圈次數為我們需要編碼的字串的長度。
int asc_ = int(inputs[j]);
unsigned inx = asc_ >> i;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i); // min: 0, max:{1, 2, 4, 8, 16, 32}
encode[ens++] = base64_table[inx];
上面程式碼片段的主要作用是:
1.將字元轉為十進位制ascii碼
2.將 asc_ 右移 i 得到 6 bit,因為這裡不用手動計算二進位制,它本身就得到了一個 0~63 的十進位制數,將其作為 base64 表的下標索引得到第一個字元(i 的所有取值情況為 { 2, 4, 6 } ,這也是 bit 陣列為 6 的原因)。
3.如果程式進行到當前分組的第一個字元,那麼迴圈
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i);
將不會進行,否則,計算該分組前一個字元儲存在 bit 中的對應的 i 位上的值(計算字元移除的 bit 程式碼在後面,因為每組的第一個字元不需要計算加上 bit 的結果)。時間複雜度 $ O(1) $
例如(該例來自wikipedia - Base64):
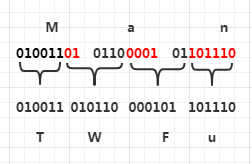
第一個字元右移出的2個bit(01)儲存到bit陣列,剩餘的編碼為 T 字元,掃描到字元 a 時,先將其值大小右移 4 位,變為 6(0110),將 bit 中的 2 個 bit 加到 0110 前面,也就是 010110,這裡 bit 中的 1 的位為 4($ 1 \times 2^4 = 16 $ ),0的位為 5($ 0 \times 2^5 = 0 $ ), 可以根據 8 + k - i 來計算應該位移多少(註釋中列舉了可能情況)。
4.利用計算出的結果作為 base64 表的索引,取出對應的字元,並存儲到 encode 棧中。
下一個片段:
if (i != 6) {
for (unsigned k = 0u, n = asc_; k < i; n >>= 1, k++)
bit[k] = n & 1;
i += 2;
}
當程式還在週期中進行時,程式就會進入到該片段,目的就是將當前字元後 i 個 bit 儲存到 bit 陣列中,以維護並填充下一個字元的前 i 個 bit。
否則執行片段:
else {
i = asc_;
inx = i >= 64 ? (i >= 128 ? i - 128 : i - 64) : i;
encode[ens++] = base64_table[inx];
if (inputs[j + 1] != '\0') i = 2;
}
當掃描到分組中第 3 個字元時,一個週期就結束了,因為 $ 4 \times 6 = 3 \times 8 $,所以,最後一個字元不需要位移,更準確的說,最後一個字元可以編碼成兩個字元,前 2 bit 結合前一個字元的後 4 bit,得到一個字元;後 6 bit 可以直接編碼為一個字元。但如何將 8 bit 的前 2 個 bit 去掉呢?思考了一下,第7位二進位制有效的最小的十進位制值為64,第8位二進位制有效的最小的十進位制值為128,所以,就有了上面程式碼片段中第3行的程式碼,實際上,我們的輸入是 ascii 字符集,不可能有大於等於 128 的情況,所以,可以寫成:
inx = i >= 64 ? i - 64 : i;
然後將 inx 作為 base64 表的索引,取出字元並加入到 encode 棧頂。注意:inx 值是合法的,且一定不會導致越界發生。
最後如果下一個字元不是結束符,則將 i 重新置為 2,以開始新一輪的編碼。當下一個字元為結束符時,i 的值一定大於 6(對於字母和數字的字元部分)。
核心部分基本就是這些了,但還有一些細節沒處理。
對於上面的程式,當輸入的字串長度不能整除 3 時,最後一個字元的後面一部分一定會沒有被編碼出來,以及沒有填充 "=" 來完成 base64 的編碼規則。
所以,繼續完善細節,見下面片段:
if (i <= 6)
{
unsigned inx = 0;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i);
encode[ens++] = base64_table[inx];
}
while (i <= 6) encode[ens++] = '=', i += 2;
前面的程式的結束情況一定在 if 之後就完成迴圈了,最後一個字元的 8 bit 後面 i 部分存入 bit 中的後,沒有用上,於是,將其取出來後面全填充為 0 並計算出值即可,然後判斷迴圈結束前執行到週期的第幾個字元(一定是1或2),填充上"="。時間複雜度 $ O(1) $
於是,該演算法的總時間複雜度為 $ O(n) $ ,n 為字串長度。
最後
完整實現程式碼:
#include <iostream>
#include <cstdio>
#include <cstring>
const char *base64_table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
char* base64encode(char* encode, const char* inputs)
{
unsigned bit[6] = {0u};
size_t ens = 0, i = 2u;
for (unsigned j = 0u; inputs[j]; j++)
{
int asc_ = int(inputs[j]);
unsigned inx = asc_ >> i;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i); // min: 0, max:{1, 2, 4, 8, 16, 32}
encode[ens++] = base64_table[inx];
if (i != 6) {
for (unsigned k = 0u, n = asc_; k < i; n >>= 1, k++)
bit[k] = n & 1;
i += 2;
}
else {
i = asc_;
inx = i >= 64 ? i - 64 : i;
encode[ens++] = base64_table[inx];
if (inputs[j + 1] != '\0') i = 2;
}
}
if (i <= 6)
{
unsigned inx = 0;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i);
encode[ens++] = base64_table[inx];
}
while (i <= 6) encode[ens++] = '=', i += 2;
encode[ens] = 0;
return encode;
}
char* base64encode(char* encode, std::string inputs)
{
return base64encode(encode, inputs.c_str());
}
int main(int argc, char* argv[])
{
if (argc <= 1)
{
std::cout << "usage -i <input text>" << std::endl;
return 0;
}
if ( !strcmp(argv[1], "-i") )
{
std::string doc = argv[2];
int len = doc.size();
char* encode = new char[len * (4 / 3)];
std::cout << base64encode(encode, argv[2]) << std::endl;
delete[] encode;
encode = nullptr;
}
return 0;
}
測試一下(來自wiki - Base64):
base64encode -i "Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure."
Output:
TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0aGlzIHNpbmd1bGFyIHBhc3Npb24gZnJvbSBvdGhlciBhbmltYWxzLCB3aGljaCBpcyBhIGx1c3Qgb2YgdGhlIG1pbmQsIHRoYXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2YgZGVsaWdodCBpbiB0aGUgY29udGludWVkIGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVyYXRpb24gb2Yga25vd2xlZGdlLCBleGNlZWRzIHRoZSBzaG9ydCB2ZWhlbWVuY2Ugb2YgYW55IGNhcm5hbCBwbGVhc3VyZS4=