
HanLP使用者自定義詞典原始碼分析
HanLP使用者自定義詞典原始碼分析
1. 官方文件及參考連結
-
關於詞典問題Issue,首先參考:FAQ
-
自定義詞典其實是基於規則的分詞,它的用法參考這個issue
-
如果有些數量詞、字母詞需要分詞,可參考:P2P和C2C這種詞沒有分出來,希望加到主詞庫
-
關於詞性標註:可參考詞性標註
2. 原始碼解析
分析 com.hankcs.demo包下的DemoCustomDictionary.java 基於自定義詞典使用標準分詞HanLP.segment(text)的大致流程(HanLP版本1.5.3)。首先把自定義詞新增到詞庫中:
CustomDictionary.add("攻城獅"); CustomDictionary.insert("白富美", "nz 1024");//指定了自定義詞的詞性和詞頻 CustomDictionary.add("單身狗", "nz 1024 n 1")//一個詞可以有多個詞性
新增詞庫的過程包括:
-
若啟用了歸一化
HanLP.Config.Normalization = true;,則會將自定義詞進行歸一化操作。歸一化操作是基於詞典檔案 CharTable.txt 進行的。 -
判斷自定義詞是否存在於自定義核心詞典中
public static boolean add(String word) { if (HanLP.Config.Normalization) word = CharTable.convert(word); if (contains(word)) return false;//判斷DoubleArrayTrie和BinTrie是否已經存在word return insert(word, null); }
- 當自定義詞不在詞典中時,構造一個CoreDictionary.Attribute物件,若新增的自定義詞未指定詞性和詞頻,則詞性預設為 nz,頻次為1。然後試圖使用DAT樹將該 Attribute物件新增到核心詞典中,由於我們自定義的詞未存在於核心詞典中,因為會新增失敗,從而將自定義詞放入到BinTrie中。因此,不在核心自定義詞典中的詞(動態增刪的那些詞語)是使用BinTrie樹儲存的。
public static boolean insert(String word, String natureWithFrequency) { if (word == null) return false; if (HanLP.Config.Normalization) word = CharTable.convert(word); CoreDictionary.Attribute att = natureWithFrequency == null ? new CoreDictionary.Attribute(Nature.nz, 1) : CoreDictionary.Attribute.create(natureWithFrequency); if (att == null) return false; if (dat.set(word, att)) return true; //"攻城獅"是動態加入的詞語. 在核心詞典中未匹配到,在自定義詞典中也未匹配到, 動態增刪的詞語使用BinTrie儲存 if (trie == null) trie = new BinTrie<CoreDictionary.Attribute>(); trie.put(word, att); return true; }
將自定義新增到BinTrie樹後,接下來是使用分詞演算法分詞了。假設使用的標準分詞(viterbi演算法來分詞):
List<Vertex> vertexList = viterbi(wordNetAll);分詞具體過程可參考:
分詞完成之後,返回的是一個 Vertex 列表。如下圖所示:
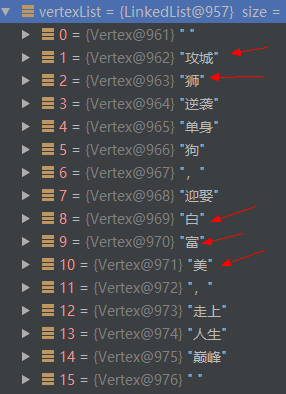
然後根據 是否開啟使用者自定義詞典 配置來決定將分詞結果與使用者新增的自定義詞進行合併。預設情況下,config.useCustomDictionary是true,即開啟使用者自定義詞典。
if (config.useCustomDictionary)
{
if (config.indexMode > 0)
combineByCustomDictionary(vertexList, wordNetAll);
else combineByCustomDictionary(vertexList);
}combineByCustomDictionary(vertexList)由兩個過程組成:
-
合併DAT 樹中的使用者自定義詞。這些詞是從 詞典配置檔案 CustomDictionary.txt 中載入得到的。
-
合併BinTrie 樹中的使用者自定義詞。這些詞是 程式碼中動態新增的:
CustomDictionary.add("攻城獅")
//DAT合併
DoubleArrayTrie<CoreDictionary.Attribute> dat = CustomDictionary.dat;
....
// BinTrie合併
if (CustomDictionary.trie != null)//使用者通過CustomDictionary.add("攻城獅"); 動態增加了詞典
{
....合併之後的結果如下:
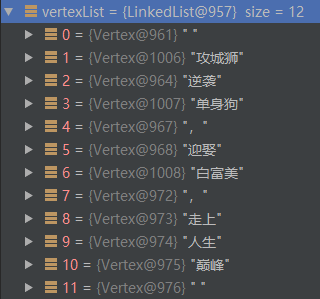
3. 關於使用者自定義詞典
總結一下,開啟自定義分詞的流程基本如下:
- HanLP啟動時載入詞典檔案中的CustomDictionary.txt 到DoubleArrayTrie中;使用者通過
CustomDictionary.add("攻城獅");將自定義詞新增到BinTrie中。 - 使用某一種分詞演算法分詞
- 將分詞結果與DoubleArrayTrie或BinTrie中的自定義詞進行合併,最終返回輸出結果
HanLP作者在HanLP issue783:上面說:詞典不等於分詞、分詞不等於自然語言處理;推薦使用語料而不是詞典去修正統計模型。由於分詞演算法不能將一些“特定領域”的句子分詞正確,於是為了糾正分詞結果,把想要的分詞結果新增到自定義詞庫中,但最好使用語料來糾正分詞的結果。另外,作者還說了在以後版本中不保證繼續支援動態新增自定義詞典。以上是閱讀原始碼過程中的一些粗淺理解,僅供參考。