
secondary namenode和namenode的區別
Secondary NameNode:它究竟有什麼作用? 在Hadoop中,有一些命名不好的模組,Secondary NameNode是其中之一。從它的名字上看,它給人的感覺就像是NameNode的備份。但它實際上卻不是。很多Hadoop的初學者都很疑惑,Secondary NameNode究竟是做什麼的,而且它為什麼會出現在HDFS中。因此,在這篇文章中,我想要解釋下Secondary NameNode在HDFS中所扮演的角色。
從它的名字來看,你可能認為它跟NameNode有點關係。沒錯,你猜對了。因此在我們深入瞭解Secondary NameNode之前,我們先來看看NameNode是做什麼的。
NameNode
NameNode主要是用來儲存HDFS的元資料資訊,比如名稱空間資訊,塊資訊等。當它執行的時候,這些資訊是存在記憶體中的。但是這些資訊也可以持久化到磁碟上。
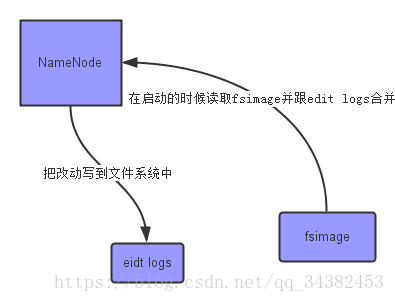
上面的這張圖片展示了NameNode怎麼把元資料儲存到磁碟上的。這裡有兩個不同的檔案:
fsimage - 它是在NameNode啟動時對整個檔案系統的快照 edit logs - 它是在NameNode啟動後,對檔案系統的改動序列 只有在NameNode重啟時,edit logs才會合併到fsimage檔案中,從而得到一個檔案系統的最新快照。但是在產品叢集中NameNode是很少重啟的,這也意味著當NameNode運行了很長時間後,edit logs檔案會變得很大。在這種情況下就會出現下面一些問題:
edit logs檔案會變的很大,怎麼去管理這個檔案是一個挑戰。 NameNode的重啟會花費很長時間,因為有很多改動[筆者注:在edit logs中]要合併到fsimage檔案上。 如果NameNode掛掉了,那我們就丟失了很多改動因為此時的fsimage檔案非常舊。[筆者注: 筆者認為在這個情況下丟失的改動不會很多, 因為丟失的改動應該是還在記憶體中但是沒有寫到edit logs的這部分。] 因此為了克服這個問題,我們需要一個易於管理的機制來幫助我們減小edit logs檔案的大小和得到一個最新的fsimage檔案,這樣也會減小在NameNode上的壓力。這跟Windows的恢復點是非常像的,Windows的恢復點機制允許我們對OS進行快照,這樣當系統發生問題時,我們能夠回滾到最新的一次恢復點上。
現在我們明白了NameNode的功能和所面臨的挑戰 - 保持檔案系統最新的元資料。那麼,這些跟Secondary NameNode又有什麼關係呢?
Secondary NameNode SecondaryNameNode就是來幫助解決上述問題的,它的職責是合併NameNode的edit logs到fsimage檔案中。
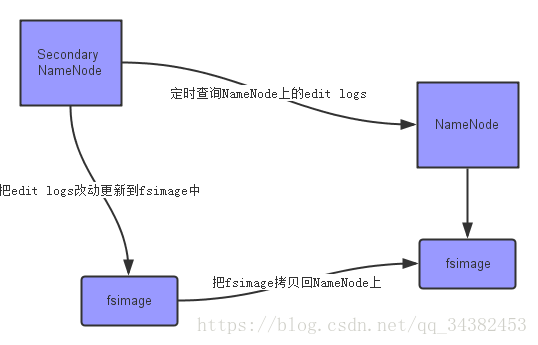
上面的圖片展示了Secondary NameNode是怎麼工作的。
首先,它定時到NameNode去獲取edit logs,並更新到fsimage上。[筆者注:Secondary NameNode自己的fsimage] 一旦它有了新的fsimage檔案,它將其拷貝回NameNode中。 NameNode在下次重啟時會使用這個新的fsimage檔案,從而減少重啟的時間。 Secondary NameNode的整個目的是在HDFS中提供一個檢查點。它只是NameNode的一個助手節點。這也是它在社群內被認為是檢查點節點的原因。