
通過Kafka在ignite叢集之間進行實時資料複製
版本1.6的ApacheIgnite提供了一種基於KafkaConnect進行資料處理的新方法。Kafka Connect是ApacheKafka 0.9中引入的一個新特性,它支援ApacheKafka和其他資料系統之間的可伸縮和可靠的流資料。它使得在記憶體中向您的可伸縮和安全的流資料管道中新增新系統變得非常容易。在本文中,我們將研究如何設定和配置IgniteSource聯結器,以便在Ignite叢集之間執行資料複製。
apache ignite,開箱即用,提供點燃-卡夫卡模組採用三種不同的解決方案(API)來實現健壯的資料處理管道,將資料從/到Kafka主題流到ApacheIgnite。

簡而言之,Apache

這篇文章的部分內容摘自這本書。阿帕奇·艾格尼特的書。如果它讓你感興趣,看看書的其餘部分,以獲得更有幫助的資訊。
這,這個,那,那個IgniteSourceConnector對於支援以下用例可能很有用:
- 若要在發生快取事件時自動通知任何客戶端,例如,每當有新條目進入快取時。
- 若要使用從Ignite快取流到1-N目的地的非同步事件流,請執行以下操作。目標可以是任何資料庫,也可以是另一個Ignite叢集。這些使您能夠通過Kafka在兩個Ignite叢集之間進行資料複製。
阿帕奇IgniteSourceConnector與IgniteSinkConnector一起使用的工具,可在ignite-kafka-x.x.x.jar分配。IgniteSourceConnector需要以下配置引數:

的高階體系結構。IgniteSinkConnector如圖1所示。
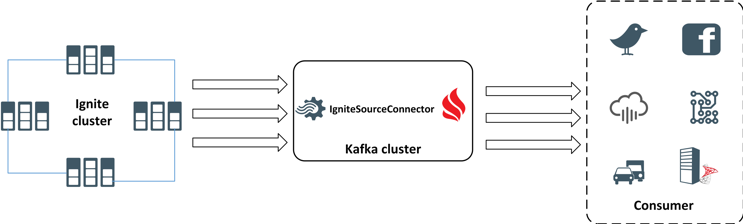
在本文中,我們將使用兩個IgniteSourceConnector
-
在一臺機器上執行兩個獨立的Ignite叢集。
-
在傳送到Ignite目標叢集之前,開發一個流提取器來解析傳入的資料。
-
在不同的獨立卡夫卡工人中配置並啟動IgniteSource和Sink聯結器。
-
向Ignite源叢集中新增或修改某些資料。
在完成所有配置之後,您應該有一個典型的管道,即將資料從一個Ignite叢集流到另一個Ignite叢集,如圖2所示。
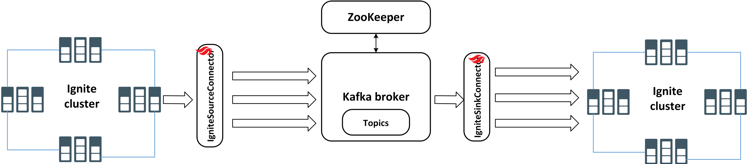
讓我們從Ignite叢集配置開始。
第一步。我們將在一臺機器上啟動兩個孤立的叢集。要做到這一點,我們必須使用另一組TcpDiscoverySpi和TcpConfigurationSpi將兩個叢集分離到一個主機上。因此,對於第一個叢集中的節點,我們將使用以下方法TcpDiscoverySpi和TcpConfigurationSpi組合:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util.xsd">
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="peerClassLoadingEnabled" value="true"/>
<property name="cacheConfiguration">
<list>
<!-- Partitioned cache example configuration (Atomic mode). -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="myCacheSource"/>
<property name="atomicityMode" value="ATOMIC"/>
<property name="backups" value="1"/>
</bean>
</list>
</property>
<!-- Enable cache events. -->
<property name="includeEventTypes">
<list>
<!-- Cache events. -->
<util:constant static-field="org.apache.ignite.events.EventType.EVT_CACHE_OBJECT_PUT"/>
</list>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<!-- Initial local port to listen to. -->
<property name="localPort" value="48500"/>
<!-- Changing local port range. This is an optional action. -->
<property name="localPortRange" value="20"/>
<!-- Setting up IP finder for this cluster -->
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<value>127.0.0.1:48500..48520</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
<!--
Explicitly configure TCP communication SPI changing local
port number for the nodes from the first cluster.
-->
<property name="communicationSpi">
<bean class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi">
<property name="localPort" value="48100"/>
</bean>
</property>
</bean>
</beans>
我們指定了本地港口48500要偵聽並使用靜態IP查詢器來發現節點,請執行以下操作。此外,我們還顯式地將tcp通訊埠配置為48100。從上述配置開始的每個Ignite節點將只加入到此叢集,並且在同一主機上的另一個叢集中不可見。注意,我們還啟用了快取物件放置用於獲取的事件PUT快取中每個條目的事件通知。作為資料來源,我們將使用myCacheSource複製快取。用名稱儲存檔案isolated-cluster-1-kafka-source.xml在.。$IGNITE_HOME/examples/config資料夾。
對於來自第二個叢集的節點,我們必須使用另一組埠。配置如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="peerClassLoadingEnabled" value="true"/>
<property name="cacheConfiguration">
<list>
<!-- Partitioned cache example configuration (Atomic mode). -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="myCacheTarget"/>
<property name="atomicityMode" value="ATOMIC"/>
<property name="backups" value="1"/>
</bean>
</list>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<!-- Initial local port to listen to. -->
<property name="localPort" value="49500"/>
<!-- Changing local port range. This is an optional action. -->
<property name="localPortRange" value="20"/>
<!-- Setting up IP finder for this cluster -->
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<value>127.0.0.1:49500..49520</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
<!--
Explicitly configure TCP communication SPI changing local port number
for the nodes from the second cluster.
-->
<property name="communicationSpi">
<bean class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi">
<property name="localPort" value="49100"/>
</bean>
</property>
</bean>
</beans>
對於第二個叢集中的節點,我們將發現埠定義為49500和通訊埠49100。這兩種配置之間的差別是微不足道的,只有Spis和IP查詢程式的埠號不同。將此配置儲存為具有名稱的檔案isolated-cluster-1.xml並將檔案放入資料夾中。$IGNITE_HOME/examples/config.
讓我們測試一下配置。使用不同的配置檔案在單獨的控制檯中啟動兩個Ignite節點。下面是一個如何執行Ignite節點的示例。
ignite.sh $IGNITE_HOME/examples/config/isolated-cluster-1-kafka-source.xml
ignite.sh $IGNITE_HOME/examples/config/isolated-cluster-2.xml
下一個螢幕截圖顯示了上述命令的結果。正如預期的那樣,兩個獨立的Ignite節點在不同的叢集中啟動和執行。
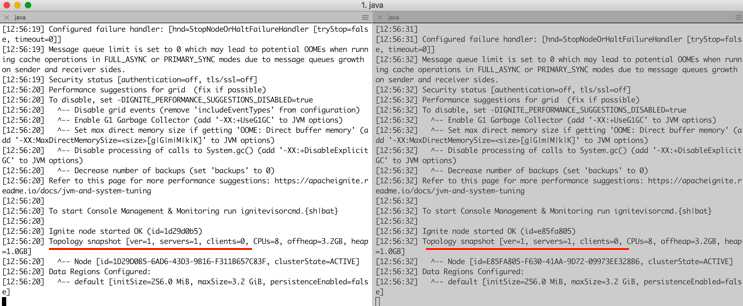
注意,所有清單和配置檔案都可以在GitHub儲存庫.
第二步。接下來,您需要定義流提取器來將資料轉換為鍵值元組。建立一個Maven專案,並將以下依賴項新增到pom.xml.
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-kafka</artifactId>
<version>2.6.0</version>
</dependency>
我們用ignite-kafka模組作為我們的依賴項。新增以下具有名稱的Java類CsvStreamExtractor進入com.blu.imdg包,它將實現StreamSingleTupleExtractor介面如下:
public class CsvStreamExtractor implements StreamSingleTupleExtractor<SinkRecord, String, String> {
public Map.Entry<String, String> extract(SinkRecord sinkRecord) {
System.out.println("SinkRecord:"+ sinkRecord.value().toString());
String[] parts = sinkRecord.value().toString().split(",");
String key = ((String[])parts[2].split("="))[1];
String val= ((String[])parts[7].split("="))[1];
return new AbstractMap.SimpleEntry<String, String>(key, val);
}
}
方法extract 是班裡的工作人員嗎?CsvStreamExtractor。這裡的程式碼很簡單:它從事件的每個元組中檢索鍵和值,其中每個元組都公開為SinkRecord在小溪裡。這,這個,那,那個extract 方法返回鍵值對,它將被髮送到Ignite叢集(目標),以便在快取中進一步儲存。
使用Maven命令編譯和構建專案:mvn clean install。成功編譯專案後,一個名為kafka-1.0.jar應該在專案目標目錄中建立。將庫複製到資料夾$KAFKA_HOME/libs.
步驟3。現在我們的流提取器已經準備好使用了,讓我們配置Ignite源和接收器聯結器,並讓它們從複製資料開始。讓我們建立一個名為ignite-connector- source.properties進入$KAFKA_HOME/myconfig目錄。新增以下屬性並儲存檔案。
# connector
name=my-ignite-source-connector
connector.class=org.apache.ignite.stream.kafka.connect.IgniteSourceConnector
tasks.max=2
topicNames=test2
# cache
cacheName=myCacheSource
cacheAllowOverwrite=true
cacheEvts=put
igniteCfg=PATH_TO_THE_FILE/isolated-cluster-1-kafka-source.xml
在前面的聯結器配置中,我們定義了org.apache.ignite.stream.kafka.connect.IgniteSourceConnector作為聯結器類。我們還將test 2指定為主題名稱,其中將儲存流事件。接下來,對於快取配置,我們將PUT事件定義為網格遠端事件。在我們的例子中,我們使用myCacheSource作為源快取。在這裡,另一個關鍵屬性是igniteCfg,其中我們顯式地指定了一個孤立的叢集配置。第一組將是我們的事件來源。
接下來,讓我們配置Ignite接收器聯結器。用名稱建立另一個檔案ignite- connector-sink.properties進入$KAFKA_HOME/myconfig目錄。從下面的清單中新增以下屬性。
# connector
name=my-ignite-sink-connector
connector.class=org.apache.ignite.stream.kafka.connect.IgniteSinkConnector
tasks.max=2
topics=test2
# cache
cacheName=myCacheTarget
cacheAllowOverwrite=true
igniteCfg=PATH_TO_THE_FILE/isolated-cluster-2.xml
singleTupleExtractorCls=com.blu.imdg.CsvStreamExtractor
配置與我們在上一節中使用的配置相同。主要區別在於singleTupleExtractorCls屬性,其中指定了我們在步驟2中開發的流提取器。
步驟4。啟動動物園管理員和Kafka Broker(伺服器),如Kafka文獻.
步驟5。您可以猜到,我們必須用test 2來建立一個新的Kafka主題。讓我們使用以下命令建立主題。
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor \ 1 --partitions 1 --topic test2
步驟6。讓我們在一個單獨的控制檯中啟動源和接收器聯結器。首先,使用以下命令啟動源聯結器。
bin/connect-standalone.sh myconfig/connect-standalone.properties myconfig/ignite-connecto\ r-source.properties
這將使用預設聯結器獨立屬性啟動源聯結器。請注意,此聯結器還將啟動Ignite伺服器節點,我們將該節點加入到點燃團簇1.
拼圖的最後一部分是沉槽聯結器。我們現在已經準備好啟動接收器聯結器了。但是,在以獨立模式啟動另一個Kafka聯結器之前,我們必須更改聯結器的REST埠和儲存檔名。建立一個名為Connection的檔案-standalone-sink.properties進入$KAFKA_HOME/myconfig資料夾。向其新增以下屬性。
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.storage.StringConverter
internal.value.converter=org.apache.kafka.connect.storage.StringConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect-1.offsets
rest.port=8888
offset.flush.interval.ms=10000
大多數配置與以前相同,只有rest.port和offset.storage.file.filename是不同的。我們已經顯式地定義了一個新的埠。8888對於此聯結器,還指定了另一個檔案儲存。使用此配置從$KAFKA_HOME目錄。
bin/connect-standalone.sh myconfig/connect-standalone-sink.properties myconfig/ignite-con\ nector-sink.properties
上面的命令將在另一個控制檯上啟動接收器聯結器。下一個圖顯示了在獨立控制檯上啟動和執行的兩個聯結器的螢幕截圖。
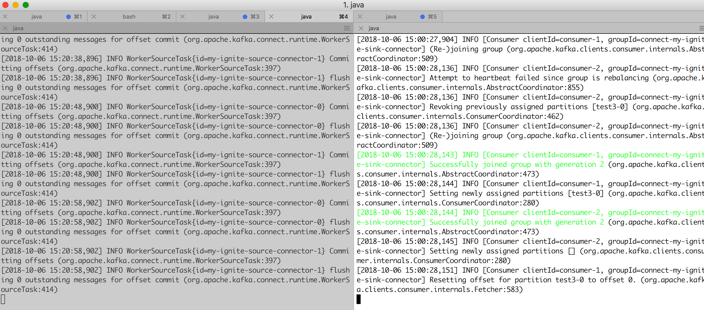
步驟7。現在我們已經設定了聯結器,現在是測試流管道的時候了。此時,如果我們在myCacheSource在叢集1上建立的快取,應該將條目複製到myCacheTarget叢集2上的快取。我們有幾種方法可以使用IgniteRESTAPI或Java客戶機將一些條目載入到快取myCacheSource中。讓我們使用Ignite Java客戶機IsolatedCluster從…第二章寫這篇文章的書。
$ java -jar ./target/IsolatedCLient-runnable.jar
這個Java客戶機載入22進入快取的條目myCacheSource。讓我們觀察一下在Ignite星系團上發生了什麼。使用兩個Ignite管理程式工具連線到叢集,每個叢集一個。執行cache -scan命令來掃描快取,您應該得到一個非常類似於圖5所示的截圖。
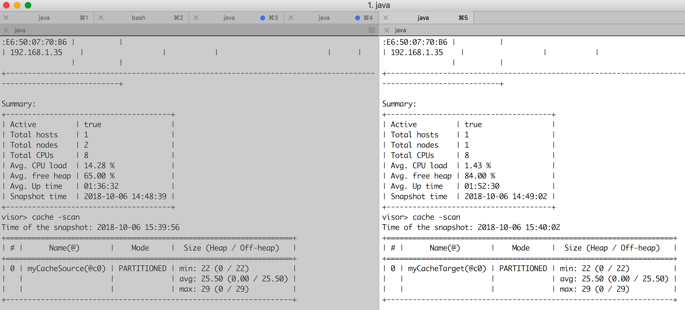
如圖5所示,不同叢集中的每個快取包含相同的條目集。如果仔細檢視控制檯上的Ignite接收器聯結器日誌,您應該會發現類似於以下日誌的日誌:
CacheEvent [cacheName=myCacheSource, part=64, key=Key:150, xid=null, lockId=GridCacheVersion [topVer=150300733, order=1538826349084, nodeOrder=4], newVal=Hello World!!: 150, oldVal=null, hasOldVal=false, hasNewVal=true, near=false, subjId=572ac224-f48b-4a0c-a844-496f4d609b6a, cloClsName=null, taskName=null, nodeId8=fb6ae4b6, evtNodeId8=572ac224, msg=Cache event., type=CACHE_OBJECT_PUT, tstamp=1538829094472]
Key:150
Val:Hello World!!:
啟動源聯結器流快取。PUT事件進入主題test2作為一個元組,它包含元資料以及鍵和值:舊值和新值。點火器接收器聯結器使用CsvStreamExtractor提取器從元組中檢索值並將鍵值對儲存到快取中,myCacheTarget.
在上面的例子中,我們只配置了Ignite叢集之間的單向實時資料複製。但是,ApacheIgniteKafka聯結器將大量電源打包到一個小模組中。通過利用它的通用性和易用性,您可以開發強大的雙向資料複製管道,或者在網格中發生任何快取事件時通知任何客戶端應用程式。此外,您還可以使用任何Kafka JDBC接收器聯結器和Ignite源聯結器將資料推入任何RDBMS。但是,Ignite源聯結器也有一些限制,在生產環境中使用它之前應該考慮到這些限制:
- 點火源聯結器不能並行工作。它不能分割工作,一個任務例項處理流。
- 它不處理多個快取。為了處理多個快取,必須定義在Kafka中配置和執行的多個聯結器。
- 點火器源聯結器需要在嵌入式模式下啟動伺服器節點才能獲得通知的事件。
- 它不支援動態重新配置。