
HDFS二.HDFS實現分散式檔案儲存---體系結構
單擊模式(Standalone):
單機模式是Hadoop的預設模式。當首次解壓Hadoop的原始碼包時,Hadoop無法瞭解硬體安裝環境,便保守地選擇了最小配置。在這種預設模式下所有3個XML檔案均為空。當配置檔案為空時,Hadoop會完全執行在本地。因為不需要與其他節點互動,單機模式就不使用HDFS,也不載入任何Hadoop的守護程序。該模式主要用於開發除錯MapReduce程式的應用邏輯。
偽分散式(Pseudo-Distributed Mode):
偽分佈模式在“單節點叢集”上執行Hadoop,其中所有的守護程序都執行在同一臺機器上。該模式在單機模式之上增加了程式碼除錯功能,允許你檢查記憶體使用情況,
完全分散式(Fully Distributed Mode):
Hadoop守護程序執行在一個叢集上.
master上看到namenode,jobtracer,secondarynamenode可以安裝在master節點,也可以單獨安裝。slave節點能看到datanode和nodeManage
HDFS起源:
HDFS源於Google的GFS論文 發表於2003年10月 HDFS是GFS的克隆版!
http://www.cnblogs.com/999-/p/7120490.html
GFS是一個可擴充套件的分散式檔案系統,用於大型的、分散式的、對大量資料進行訪問的應用。它運行於廉價的普通硬體上,並提供容錯功能。它可以給大量的使用者提供總體效能較高的服務。
GFS 也就是 google File System,Google公司為了儲存海量搜尋資料而設計的專用檔案系統。
HDFS簡介:
HDFS(Hadoop Distributed File System,Hadoop 分散式檔案系統)是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS 能提供高吞吐量的資料訪問,適合那些有著超大資料集(largedata set)的應用程式。
1. HDFS體系結構
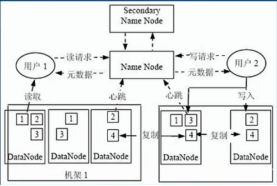
1.1 NameNode
節點程序存在於叢集的Master主機上
作用:
1.1.1管理檔案的名稱空間
1.1.2協調客戶端對檔案的訪問
1.1.3記錄每個檔案資料在各個DataNode上的位置和副本資訊
主要檔案:
VERSION:版本資訊,檔案系統識別符號
seen_txid:事物管理檔案
Fsimage_*|
Fsimage_*.md5|-----------源資料檔案
Edits_*|

1.1 DataNode
節點程序存在於叢集的Slave子機器上
作用:
1.2.1真實資料的儲存管理
1.2.2一次寫入,並行讀取(不修改)
1.2.3檔案由資料塊組成,典型的塊大小是64MB
1.2.4資料塊儘量散佈在各個節點
主要檔案:
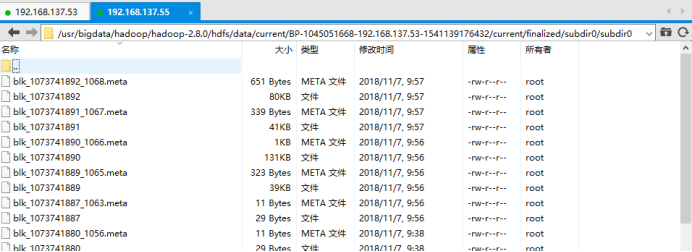
blk<id>:HDFS的資料塊,儲存具體的二進位制資料
blk<id>.meta:資料塊的屬性資訊:版本資訊,型別資訊等
寫入檔案流程:
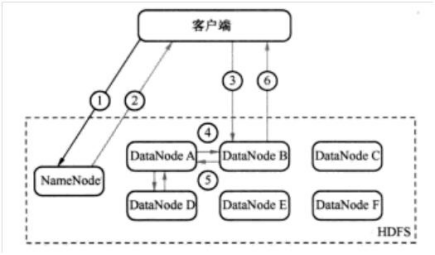
讀取檔案流程:

1.1 SecondaryNameNode
節點程序存在於叢集的master上,也可以是單獨一臺機器
作用:
1.3.1 NameNode的一個快照
1.3.2週期性備份NameNode
1.3.3記錄NameNode中的MateData以及其他資料
1.3.4可以用來恢復NameNode,但是不能替換NameNode