
Flume各種採集日誌方式與輸出目錄
1、從網路埠採集資料輸出到控制檯
一個簡單的socket 到 console配置
# 定義這個agent中各元件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source元件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = bigdata01 a1.sources.r1.port = 44444 # 描述和配置sink元件:k1 a1.sinks.k1.type = logger # 描述和配置channel元件,此處使用是記憶體快取的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之間的連線關係 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
啟動flume:bin/flume-ng agent -c conf -f myconf/socket-console.conf -n a1 -Dflume.root.logger=INFO,console

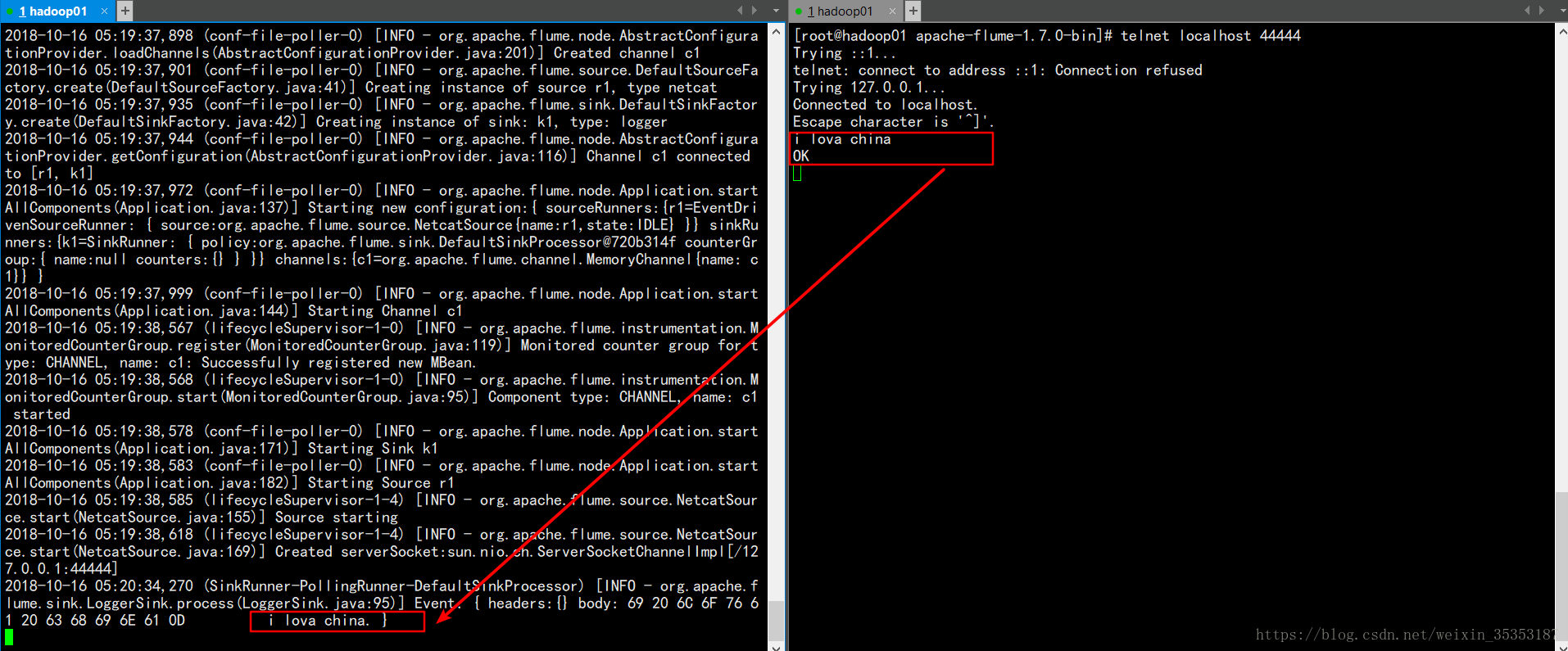
監聽44444埠:
telnet anget-hostname port (telnet localhost 44444)

監聽結果:
2、從網路端採集資料輸出到檔案
# 定義這個agent中各元件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source元件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop01 a1.sources.r1.port = 44444 # 描述和配置sink元件:k1 a1.sinks.k1.type = file_roll a1.sinks.k1.sink.directory = /usr/local/apache-flume-1.7.0-bin/flumelog # 描述和配置channel元件,此處使用是記憶體快取的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之間的連線關係 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
注:a1.sinks.k1.sink.directory = /usr/local/apache-flume-1.7.0-bin/flumelog中檔案目錄必須是存在的,不存在會報錯
啟動Flume:
bin/flume-ng agent -c conf -f myconf/netcat-disk.conf -n a1 -Dflume.root.logger=INFO,console
給監聽的埠傳送資料:
telnet hadoop01 44444
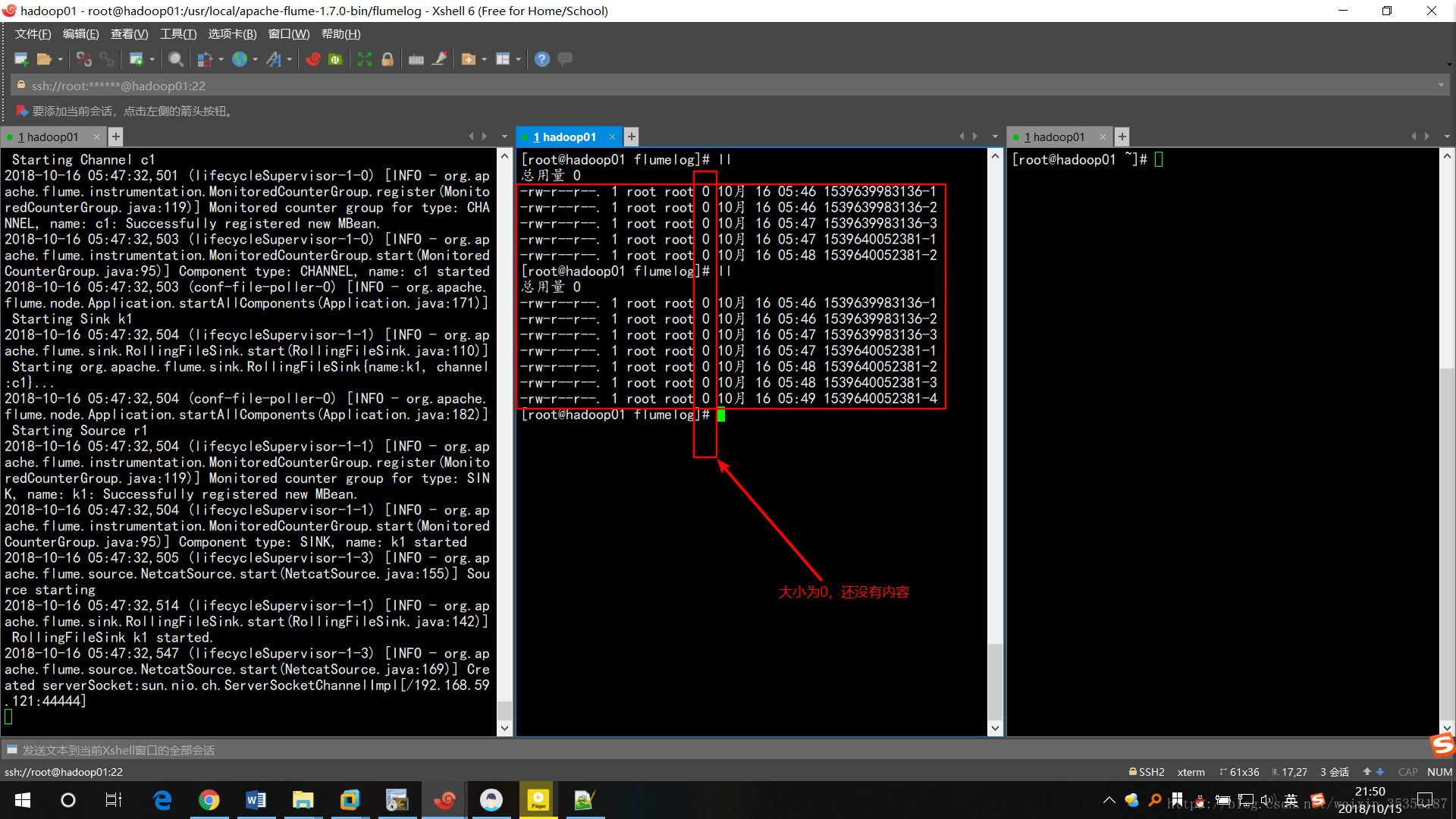
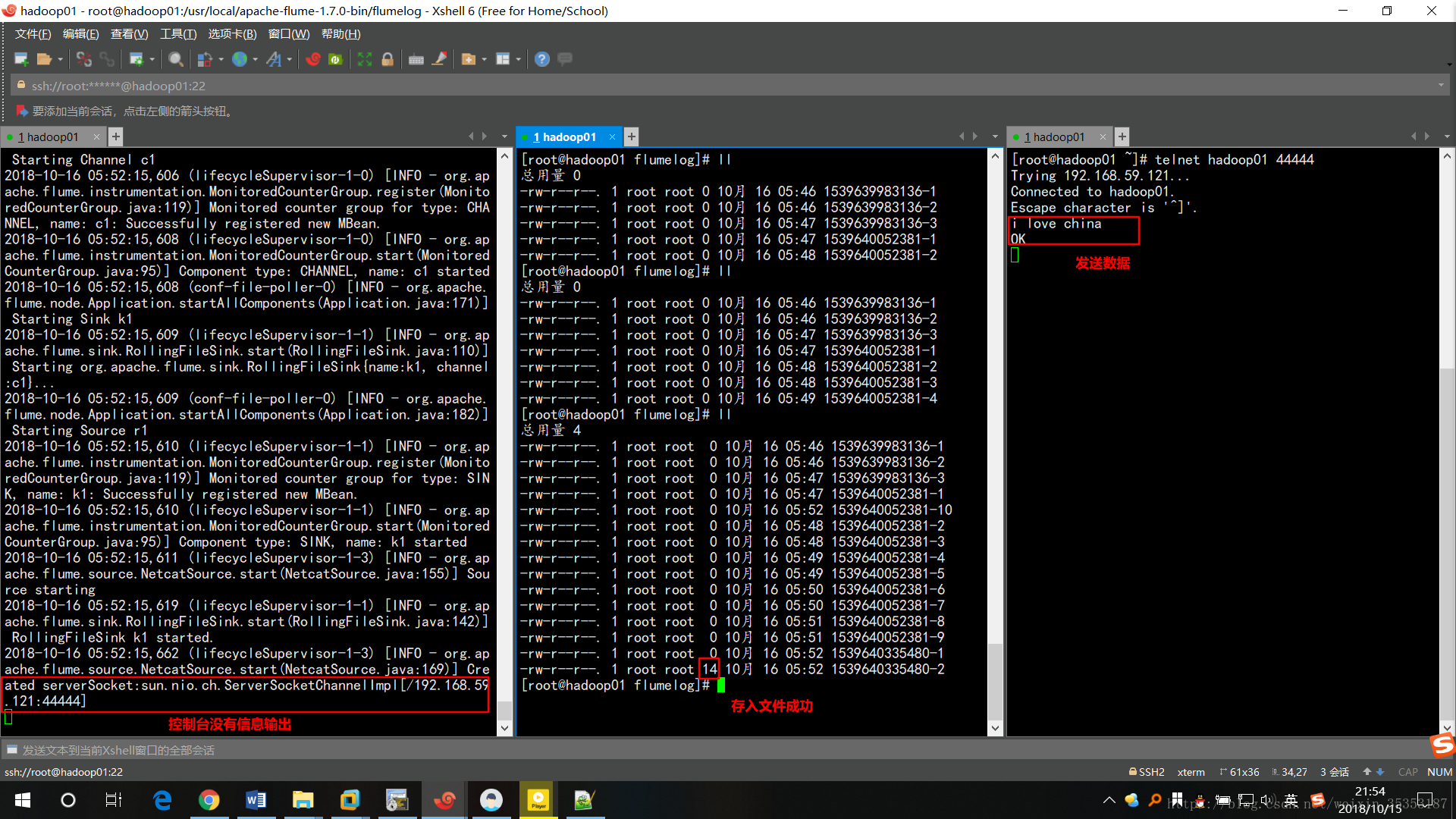

會發現此時控制檯並沒有輸出資訊,而且存入了檔案中
3、從本地目錄寫入到HDFS
# 定義這個agent中各元件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source元件:r1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /usr/local/apache-flume-1.7.0-bin/flumedata # 描述和配置sink元件:k1 #寫hdfshdfs必須是配置好環境變數的 a1.sinks.k1.type = hdfs #寫入到hdfs的目錄 a1.sinks.k1.hdfs.path = /flumedata/events #寫檔案的字首 a1.sinks.k1.hdfs.filePrefix = events- #滾動時間 a1.sinks.k1.hdfs.rollInterval = 60 #滾動大小 a1.sinks.k1.hdfs.rollSize = 1048576 #滾動數量 a1.sinks.k1.hdfs.rollCount = 100 # 描述和配置channel元件,此處使用是記憶體快取的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之間的連線關係 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
注:a1.sinks.k1.hdfs.path = /flumedata/events寫入到HDFS的目錄不需要自己建立
啟動Flume:
bin/flume-ng agent -c conf -f myconf/directory-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
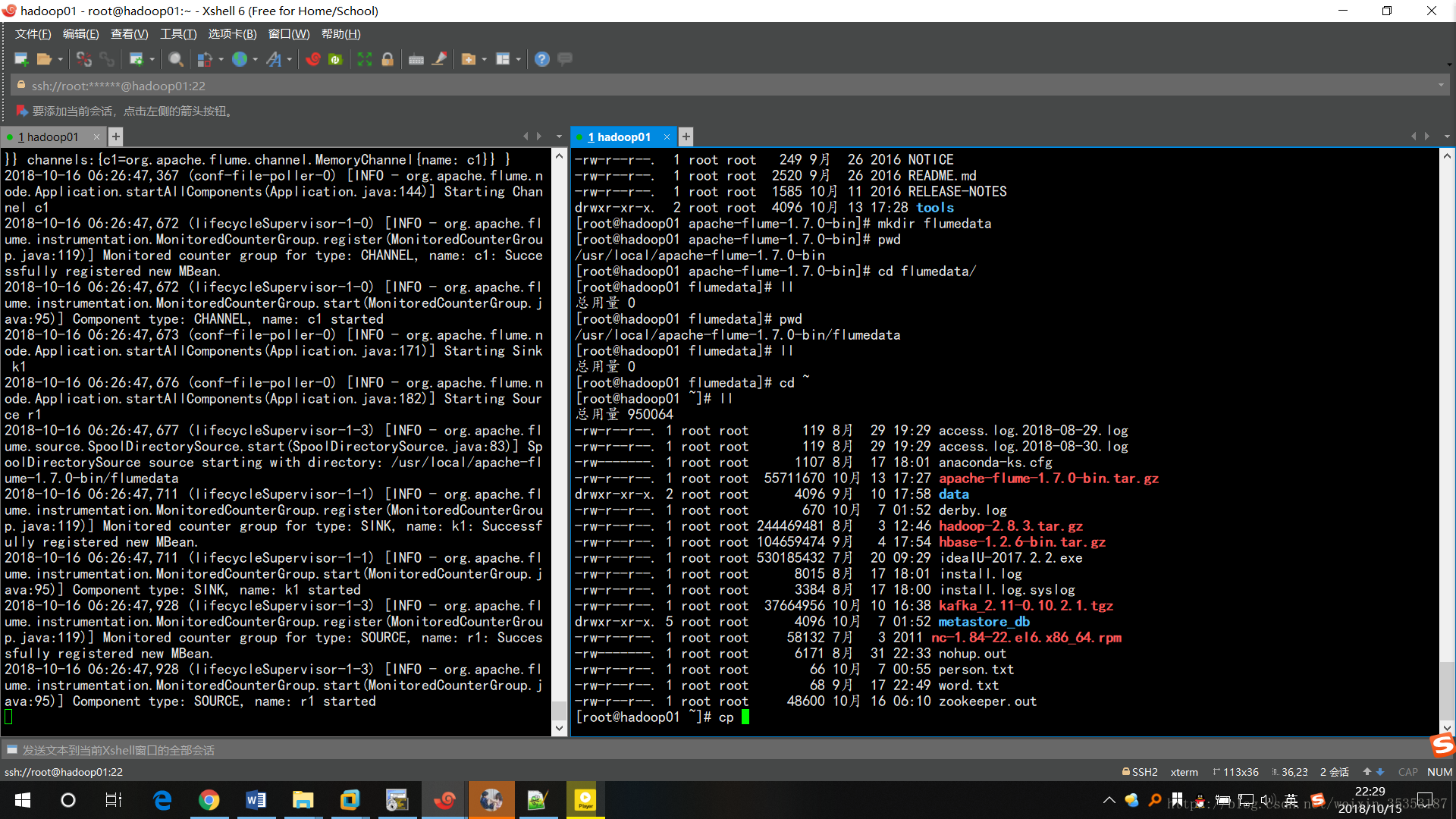
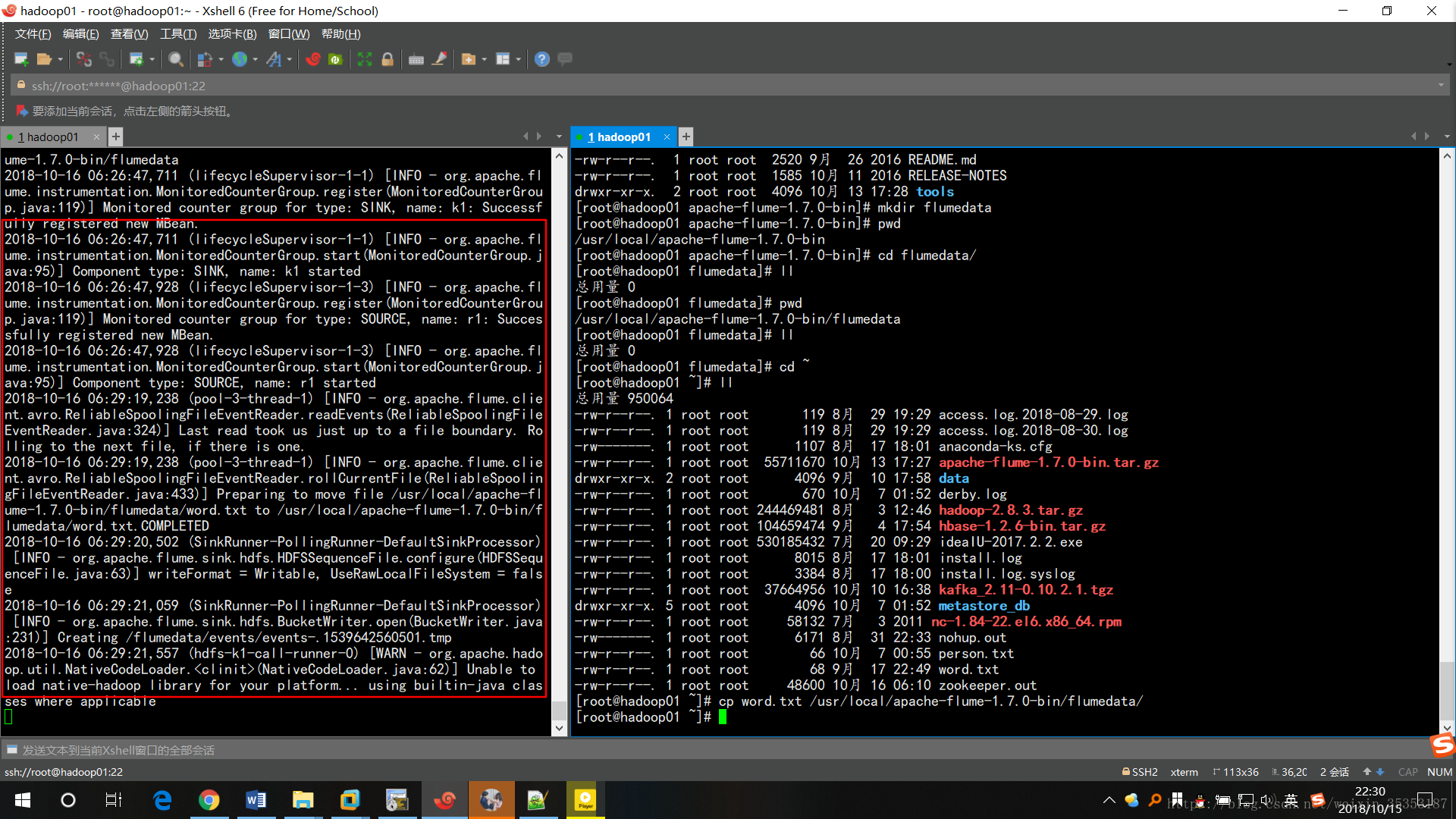
左邊在傳
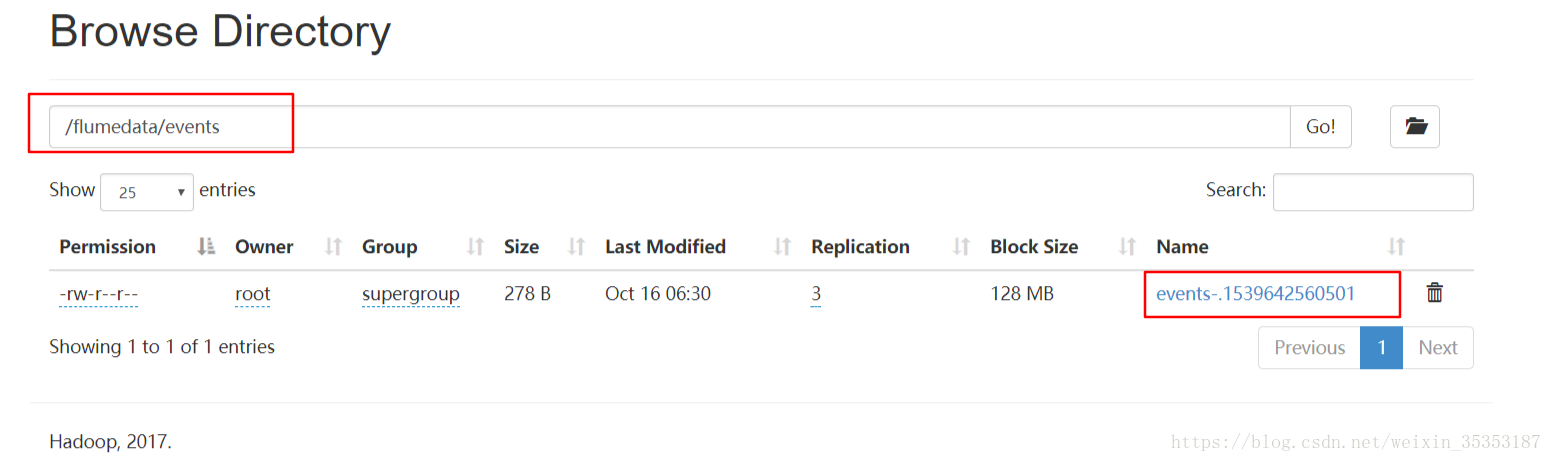
上傳成功

採集成功以後,檔名字尾變了.COMPLETED
注:如果再往目錄裡面放一個同名檔案,會報錯,不會上傳到HDFS
4、Flume監控一個檔案實時寫到Kafka
# 定義這個agent中各元件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source元件:r1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/datas/tmp.log
# 描述和配置sink元件:k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = flumetopic
a1.sinks.k1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092,hadoop04:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
# 描述和配置channel元件,此處使用是記憶體快取的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之間的連線關係
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
while true;
> do
> echo `date`>>/opt/datas/tmp.log
> sleep 0.5
> done
注:這裡連線了四個機器,第一個用於啟動Flume,第二臺用於檢視是否建立主題,第三臺用於不斷給tmp.log檔案追加內容,用於Kafka消費,第四臺用於檢視檔案大小,以證明檔案在一直寫入
啟動Flume:
bin/flume-ng agent -c conf -f myconf/exec-kafka.conf -n a1 -Dflume.root.logger=INFO,console
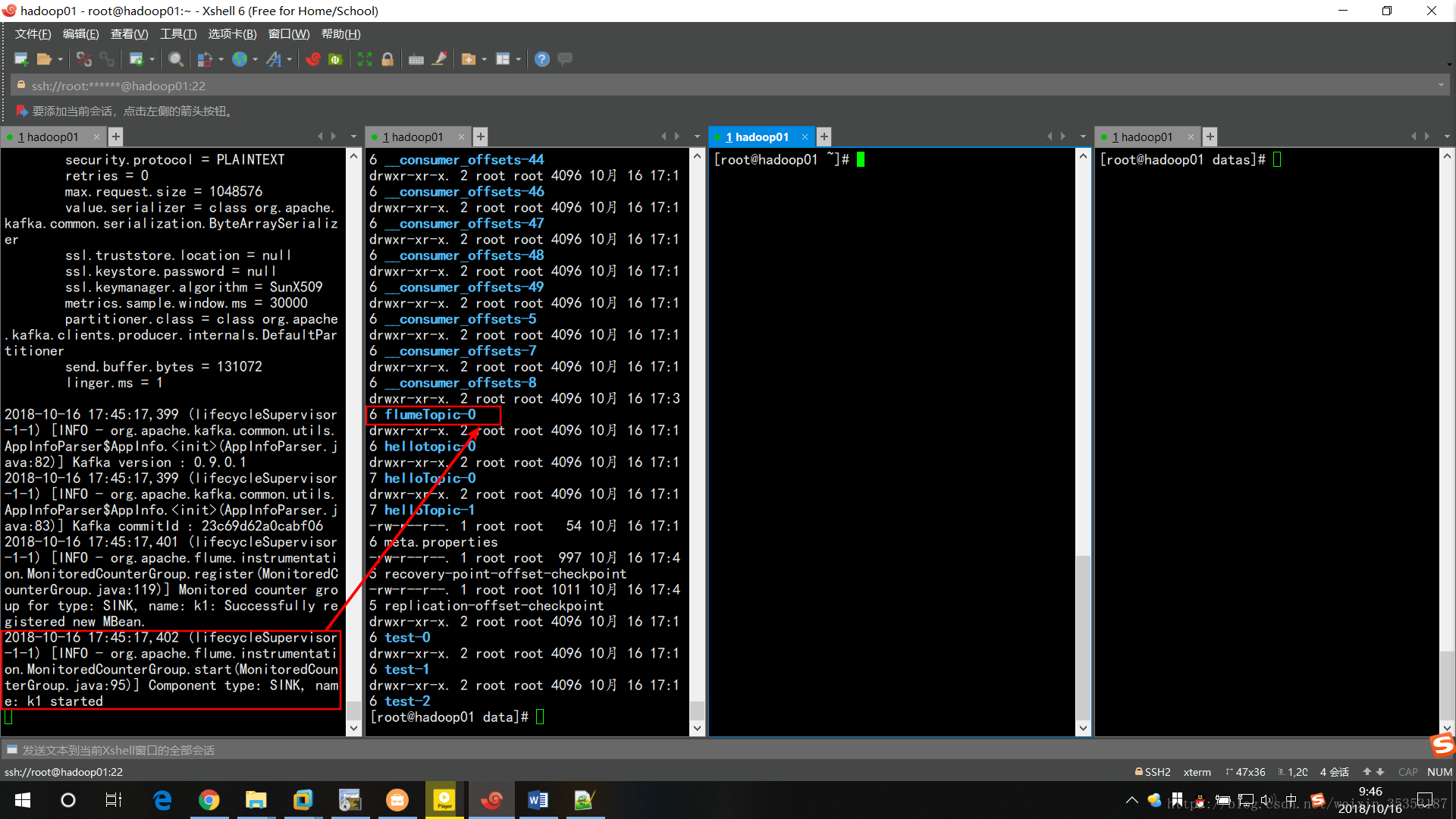
啟動成功,且已建立Topic為配置檔案中flumeTopic。
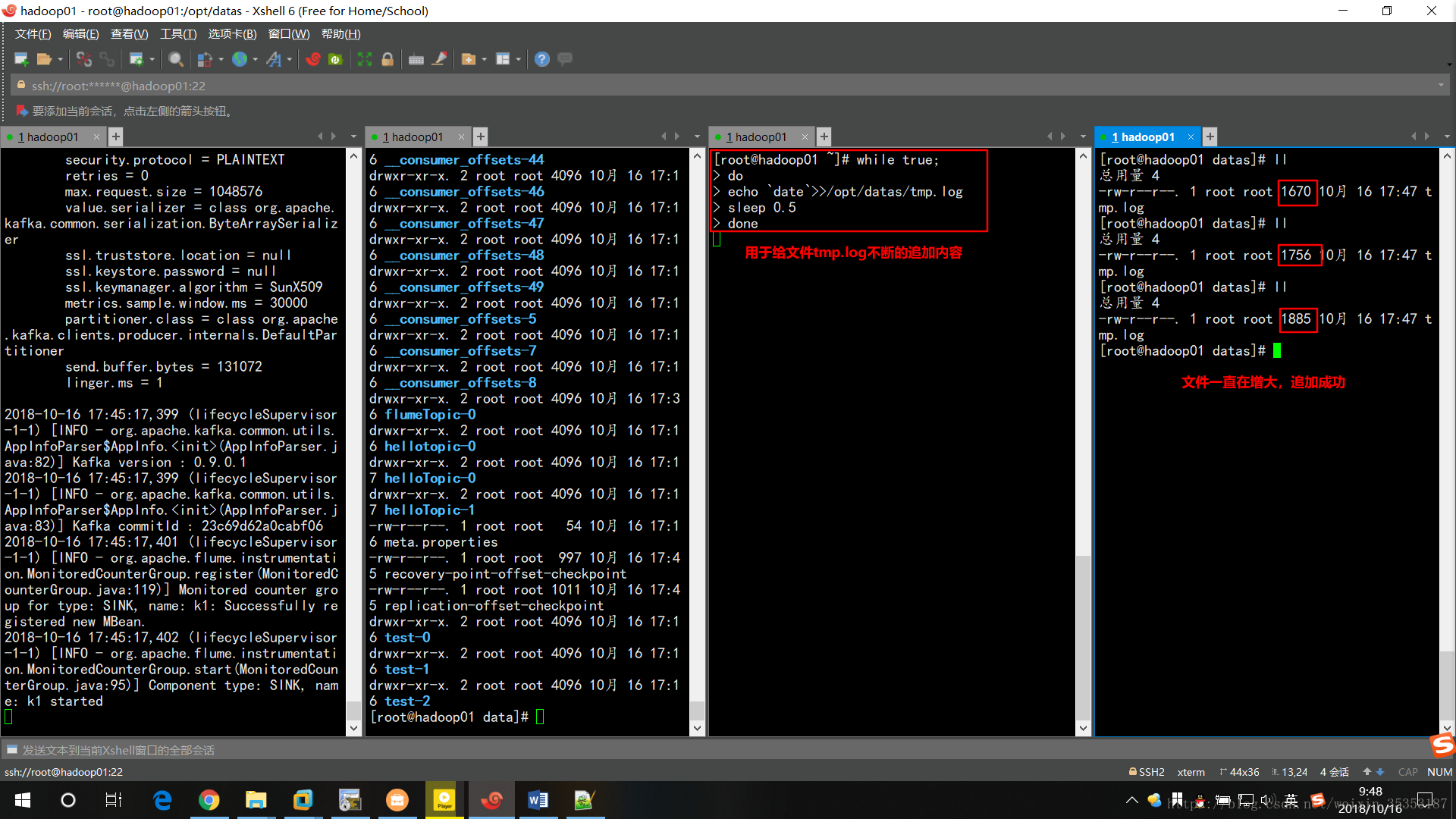
接下來,給檔案tmp.log一直追加內容。可以看到檔案大小一直在變大,說明追加成功
消費Kafka中的資料:
kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --from-beginning --topic flumeTopic
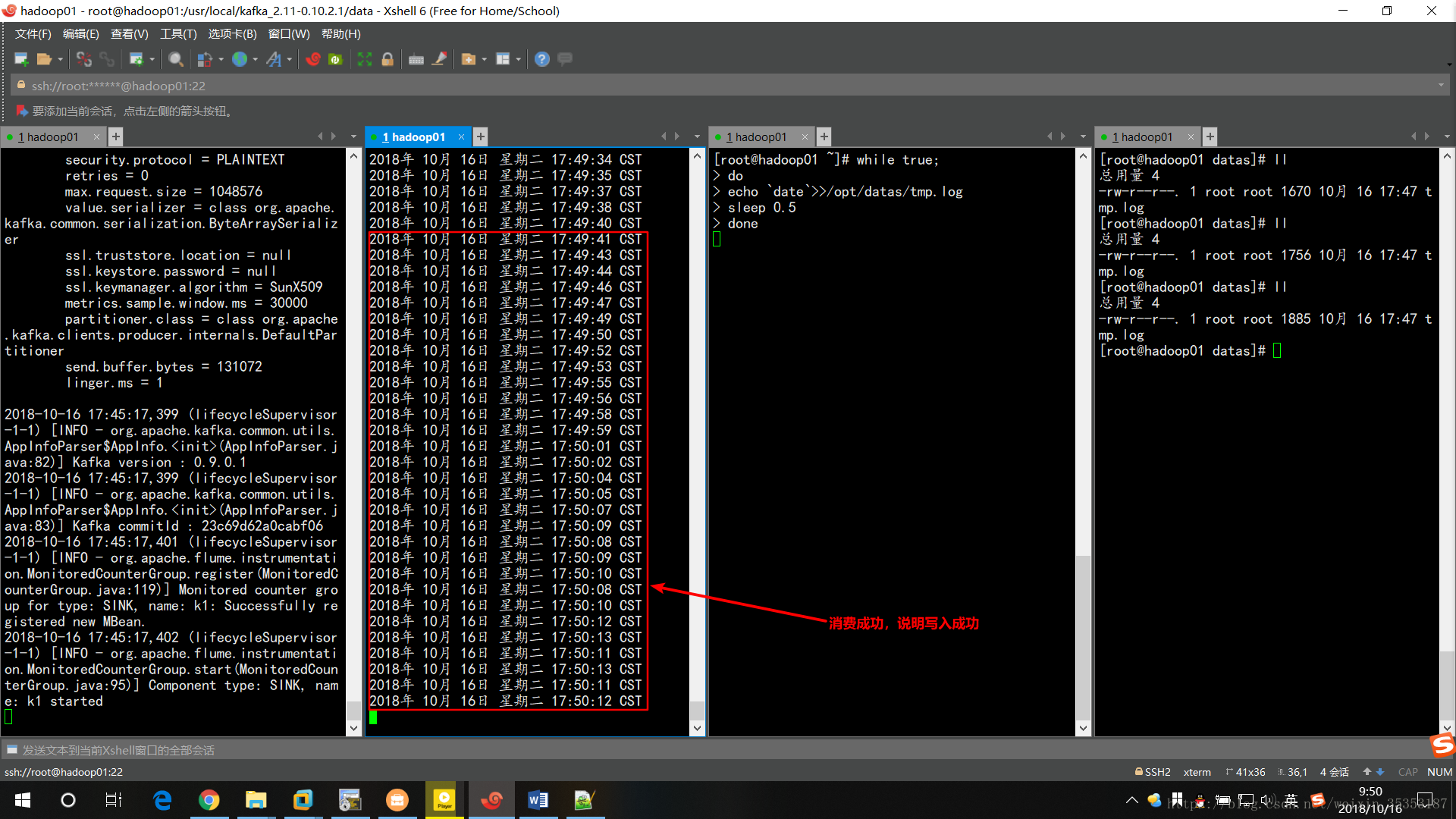
消費成功,且資料為實時時間,說明Flume成功的將檔案寫入到Kafka