
Residual Net
阿新 • • 發佈:2018-12-15
去掉相同的主體部分,從而突出微小的變化,我們明確地將這些層重新定義為根據參考層的輸入來學習殘差函式,而不是學習無參考的函式
問題提出
learning better networks as easy as stacking more layers?
- 第一個問題:梯度消失/爆炸 解決方案:標準初始化,中間層標準化
- 網路退化問題:隨著網路深度增加,準確度變飽和,迅速退化,本文引出殘差網路解決
解決上述第二個問題的極端情況:基於一個淺層網路構建堆積深層網路,其中堆積層沒有學習能力,只是將淺層的網路特徵進行復制傳遞,即恆等對映(identity mapping)
- 對於多層結構,輸入為x,網路學習到的特徵為H(x),即為輸出,兩者的差稱為殘差
- 即此堆層結構學習到的特徵提取函式為F(x) = H(x) - x,
- 此網路學習到的特徵為h(x) = F(x) + x,便得到如下殘差網路結構
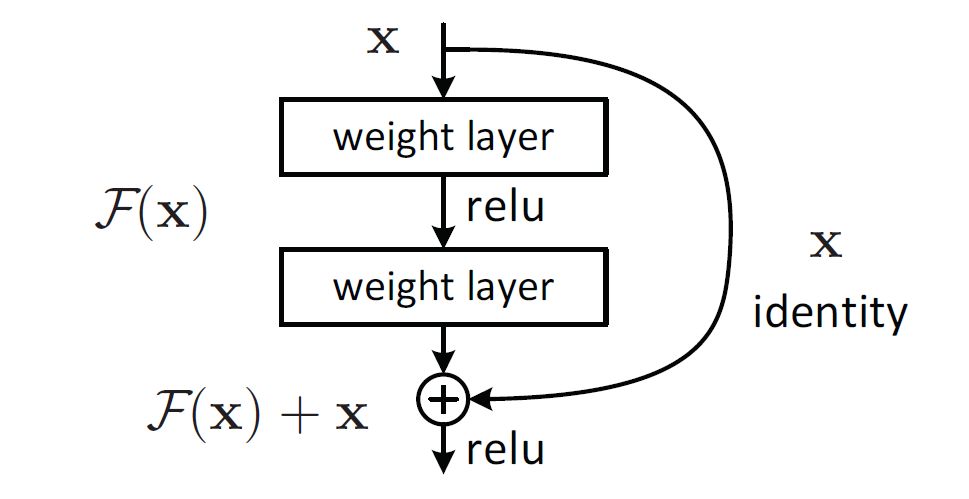
當殘差F(x)=0時,為恆等對映,網路的效能不會因層數增加而下降,但實際上殘差不會為0,一般殘差較小,學習內容少,學習難度也就變小,
- 極端:H(x)-x = 0
- 殘差情況: H(x)-x=F(x)
殘差單元公式:
根據鏈式規則:有到層的傳遞過程為:
其中大括號內的第一項1代表短路機制無損傳遞函式,不會讓梯度消失。
網路結構
- 基於VGG19,利用strid=2的卷積替換pooling,global average pool替換全連線
- 重要原則:當feature map size降低一半,數量要增加一倍,保持複雜度,虛線表示
總結
為什麼擬合殘差更加容易?
- 比如把5對映到5.1,那麼引入殘差前是F'(5)=5.1,引入殘差後是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。
- 引入殘差後的對映對輸出的變化更敏感:比如s輸出從5.1變到5.2,對映F'的輸出增加了1/51=2%,而對於殘差結構輸出從5.1到5.2,對映F是從0.1到0.2,增加了100%。