
一文講清java中的集合使用方法
阿新 • • 發佈:2018-12-15
一. java中為什麼會產生容器(集合)這個概念:
1.集合是什麼以及要學習集合的什麼?
集合的本質是java API(java固有的)中提供的一系列類的例項,用於在程式中存放物件.而且這些類中有很多實用的方法可以讓使用者方便的處理這些集合.集合分成很多種型別,不同型別的集合具有不同的特點,不同的使用場景和不同的記憶體儲存方式.所以學習集合完之後要知道處理問題時該定義哪種集合,怎麼呼叫該集合的方法甚至於該怎麼自己去實現這個集合以及它的方法.
2.有陣列了,為什麼還要有集合?
陣列可以存物件也具有一些處理物件的方法為什麼還需要集合?從兩者的特點來看看:
聊聊陣列的特點:
- 內部的所有元素型別都是一致的;
- 陣列定義之後的長度是固定的(所以陣列長度的變化一般是定義一個新的陣列把old->new,然後追加);
- 陣列內部的元素型別可以是基本資料型別也可以是類.
- 在使用過程之中如果需要包含的資料型別不一致,或者元素數量不固定.會導致有的元素無法加入陣列或初始分配陣列長度不合適(過短不夠用,過長浪費記憶體,而且需求時常變化難以尋到長度標準);
聊聊集合的特點:
- 而集合只能儲存類(集合內部是物件的引用,但可是基本型別的包裝類),而且一個集合可儲存不同類的型別;
- 集合可以任意的新增刪除元素,並且實時自動分配或者釋放記憶體(即使內部用陣列實現的也會自動,不用麻煩使用者自己實現);
- 集合的型別很多,不同型別的集合適用於解決不同的問題,可以使得大刀剁肉小刀削水果,而且其豐富的方法為使用者直接呼叫去"為所欲為".
由上面可知在處理大量物件時候使用集合的意義,也就是java中出現集合概念的意義:
物件用於封裝特有資料,物件多了需要儲存,如果物件的個數不確定就是用集合容器進行儲存. 數量任意 + 使用靈活 + 方法便捷.二.集合的組織框架以及各類集合的特點:
1.集合的組織框架圖:
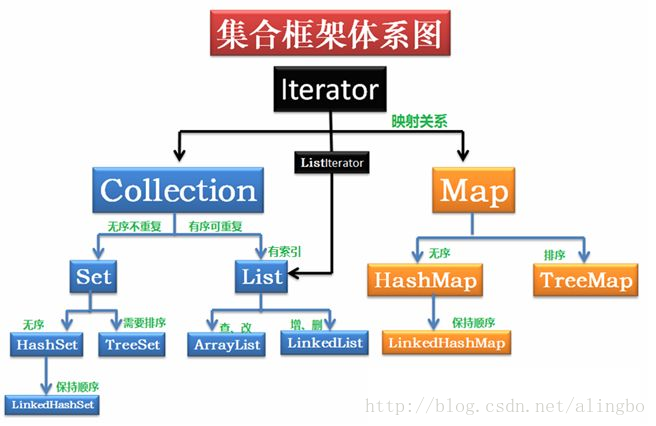
- 藍色的集合Collection中是一個一個的元素,橙色集合Map中的是一對一對的元素(鍵值對).黑色的是迭代器用於遍歷集合.
- Set中的元素無序不可重複,List的元素有序可以重複(重複的標準是兩個物件的equals方法返回為true, ==:是引用相等,不改寫equals時候,==和該方法都是表明同一個物件才返回true,有序是按照存入的順序).
- 介面:Collection,Set,List,Map.Iterator(適用於Collection),ListIterator(只適用於List),其餘為類.
注意:所有實現了Collection介面的容器類都有一個iterator方法用以返回一個實現了Iterator介面的物件.
該物件根據Collection具體的集合型別定製了合適的遍歷物件,然後返回.
2. 集合的分類及其修飾符:
集合中有介面和類兩種概念,且是一個多重繼承的體系結構,父類(介面)的方法被子類(介面)繼承,可以直接使用.
- Collection介面-定義了一組存取物件的方法,其子介面Set和List分別定義了儲存方式,Set中的元素無序不重複,List的元素有序可重複.
- Map介面定義了儲存"鍵(key)-值(value)對映對"的方法.Map的鍵是Set.
- Array是陣列實現(查快),Linked是用連結串列實現(增刪快),Hash是雜湊表實現.tree是二叉樹實現(排序),Linked和Hash經常一起出現.set(equals,加上hash就再得重寫hashCode()).
- List多了一類索引操作.Linked多了一組首尾的操作.
- tree與comparable介面(實現介面重寫類的compareTo()),tree與comparator介面(實現介面重寫compare()方法.引數形式傳入treeset構建時候的實參),set與equals()方法.hash與hashCode(),Comparable介面(對應著物件)與Collection.
三.集合的方法:
1.Collection介面中定義的方法:(介面Set和List以及其子類都可以使用)
增 --增一個 --增一個集合 刪 --刪一個元素 --刪一個集合 --刪除全部元素 包含--包含一個元素 --包含一個集合 判斷--空 -- 獲取--長度 注意:集合方法的同級性與包含性:引數為Object和Collection- int size();//長度
- boolean isEmpty(); //空?
- void clear();//清空元素
- boolean contains(Object element);//包含引數元素?
- boolean add(Object element); //增加元素.
- boolean remove(Object element);//移除元素.
- Iterator iterator();//返回遍歷器(因不同的集合遍歷方法不同,才會被新增為方法).
- boolean containsAll(Collection c);//包含引數集合?
- boolean addAll(Collection c); //增加c集合中元素.
- boolean removeAll(Collection c);//移除引數集合中元素.
- boolean retainAll(Collection c);//取交集;
- Object[] toArray(); //轉化為陣列.
2.Iterator介面中定義的方法:(迭代器)
- boolean hasNext();//遊標右側是否還有下一個元素
- Object next();//返回遊標右邊的元素,並右移遊標一個位置.
- void remove();//刪除遊標左邊的元素,在執行完next後該操作只能執行一次.//該方法是在迭代中刪除元素的唯一的安全的方法.
3.Set介面中定義的方法: (set對equals(),再hash還得hashCode(),TreeSet只看compareTo())
- 和Collection一樣,沒有自己新增的方法只是新增入該集合的物件一般重寫equals()方法,因為相同的元素不會重複存入。且本身沒有按照存入的順序儲存。
- HashSet內部資料結構是雜湊表,是不同步的.(執行緒不安全的),hash表內部還是陣列,但hash演算法對資料進行了優化,利用引數值帶入hash演算法值獲取儲存位置.(hashset是先判斷雜湊值(hashCode),然後判斷內容值(equals()),如果雜湊值不同是不需要判斷equals()).所以要存入hashSet集合的類需要重寫equals()和hashCode(),且兩型別同方法返回的值要一致.
- LinkedHashSet集合:按儲存順序的.
- TreeSet:可以排序的,預設時候按自然排序.這個集合只判斷物件的compareTo()的值,相等就不加元素認為重複,不相等根據這個排序.
- TreeSet集合的第二種排序方式二:讓集合自身具備比較功能.
4.List介面定義的方法:
List中的元素都對應一個整數型的序號記載其在容器中的位置,可以根據序號存取容器中的元素。 List中元素的順序預設為存入的順序。- Object get(int index); //獲取索引index處的值。
- Object set(int index ,Object element); //設定index的值,返回的是老的值。
- void add(int index ,Object element); //新增一個別的往後擠。
- Object remove(int indx); //刪除指定索引的值。
- int indexOf(Obiect o); //獲取值為o的第一個索引。
- int lastIndexOf(Object o);//獲取值為o的最後一個索引。
4'ListIterator介面中的方法:(該方法只適用於List集合)
除了具有Iterator的方法(向後)之外還增加了向前的操作,更重要的是增加了以下操作:
- add();
- set();
5.類java.util.Collections提供了一些靜態方法實現了基於List容器的一些常用演算法:
- void sort(List);//對List集合內的元素排序。
- void sort(list,comparator);//給Collection集合加上比較器.
- void shuffle(List);//對List容器內的物件進行隨機排列。
- void revervse(List);//對List集合內的元素進行逆序排列。
- void fill(List ,Object);//用一個特定的物件重寫整個List集合。
- void copy(List dest ,List src);//拷貝List集合。
- int binarysearch(List , Object);//對於順序List容器,用折半查詢方法查特定物件.
java.lang.Comparable介面 其中只有一個方法:
- public int compareTo(Object obj); //返回0時表示this == obj //返回正數表示this > obj //返回負數表示this < obj.
- Object put(Object key,Object value);//可新增可修改.
- Object get(Object key);//由鍵獲取值.沒有返回null.
- Object remove(Object key);//刪除指定鍵值對.
- boolean containsKey(Object key);//是否包含指定的鍵.
- boolean containsValue(Object value);//是否包含指定的值.
- int size();//集合的大小.
- boolean isEmpty();//判斷是否為空.
- void putAll(Map t);//將一個Map類中所有鍵值對新增進另一個Map中.
- void clear();//清空map集合.
- Set<K> keySet();//返回此對映中所包含的鍵的Set檢視.
- Set<Map.Entry<K,V>> entrySet(); //返回該對映所包含的對映關係的Set檢視.
- Collection<V>values();//返回該對映所包含的collection檢視.
7'.Map.Entry<K,V>(Map集合介面的內部介面)中的方法:(存的是Map中的結婚證,在遍歷時候使用)
- K getKey();
- V getValue();
- V setKey();/setValue();
while(it.hasNext()){ Interger key = it.next(); System.out.println(key); String value = map.get(key); } (2) 第二種方法 :通過Map轉化為set就可以迭代,找到了另一個方法. entrySet :該方法將鍵和值的對映物件儲存在了Set集合中,而這個對映關係的型別就是Map.Entry型別(結婚證). Set<Map.Entry<Integer,String>> entrySet = map.entrySet(); Iterator<Map.Entry<Integer,String>> it = entrySet.iterator(); while(it.hasNext()){ Map.Entry<Integer,String> me = it.next(); // Map.Entry<Integer,String>該類方法有很多 Integer key = me.getKey(); String value = me.getValue();
String value = map.get(key); } 11381:個圖( 集合框架圖),1個類( Collections類(工具類)),3個知識點(for,Generic(fan),自動裝包,解包),7個介面( Iterator介面(collection),ListIterator介面(List),Comparable介面(Tree中存的物件實現),Comparator介面(tree集合引數),Collection介面,Set介面(無序),List介面(有序),Map介面).
四.集合的附屬-泛型
1.泛型的作用:- jdk1.5出現的安全機制,將執行時期的問題ClassCastException異常轉化到編譯時期.程式設計師可以去解決了.
- 避免了強制轉化的麻煩.
- 泛型與集合
- 泛型與類
- 泛型與介面
- 泛型與方法:在返回值前
- 泛型與上下限
- 泛型與萬用字元;?(未知型別)
注意:泛型的使用注意集合內的方法也可以被約定型別了,但別越界.
五.用上集合,幾多方便?
1.集合使用中需要注意的注意點:
- 使用集合時一般引入java.util包.容器API全在該包中.
- 對於自定義的類需重寫equals方法時候,必須重寫hashCode()方法,且兩物件相等它的hash值也相等.
- 總結:列印重寫toString()方法.Set集合重寫equals()方法,hashset還需重寫hashCode();方法
- 對於Map的鍵值必須同時重寫equals和hashCode方法,並保持一致.
2.如何選擇使用的集合:
衡量標準:讀的效率和改的效率- Array:陣列=>讀快改慢,有角標.
- Linked:連結串列=>改快讀慢,add get remove + first last.
- Hash:雜湊表+兩者之間,唯一性,元素需要覆蓋hashCode和equals().
- tree: 二叉樹,排序,兩個介面Comparator和comparable.
3.集合的使用方法:
Collection c = new ArrayList();//這樣寫的好處是:引用變數c可以這次對應著ArrayList型別物件,下次可以對應HashSet物件.即放入不同型別的物件,而且後面的程式碼不需要修改.
4.遍歷集合的兩種方法:
- 使用迭代器遍歷集合:
- 使用增強型for迴圈:
for(object o : c)
{....}
該方法的優點:
用於遍歷Array或者Collection的時候相當簡便
該方法的缺點:
遍歷陣列時候,不能方便的訪問下標值。
遍歷集合時候,不能方便的刪除集合中的內容。
總結:除了簡單的遍歷並讀取其中的內容外,不建議使用增強for。
五.集合的內部實現:
待續......