
使用Scrapy框架爬取360攝影圖片的資訊
阿新 • • 發佈:2018-12-15
要點
1.分析Ajax請求
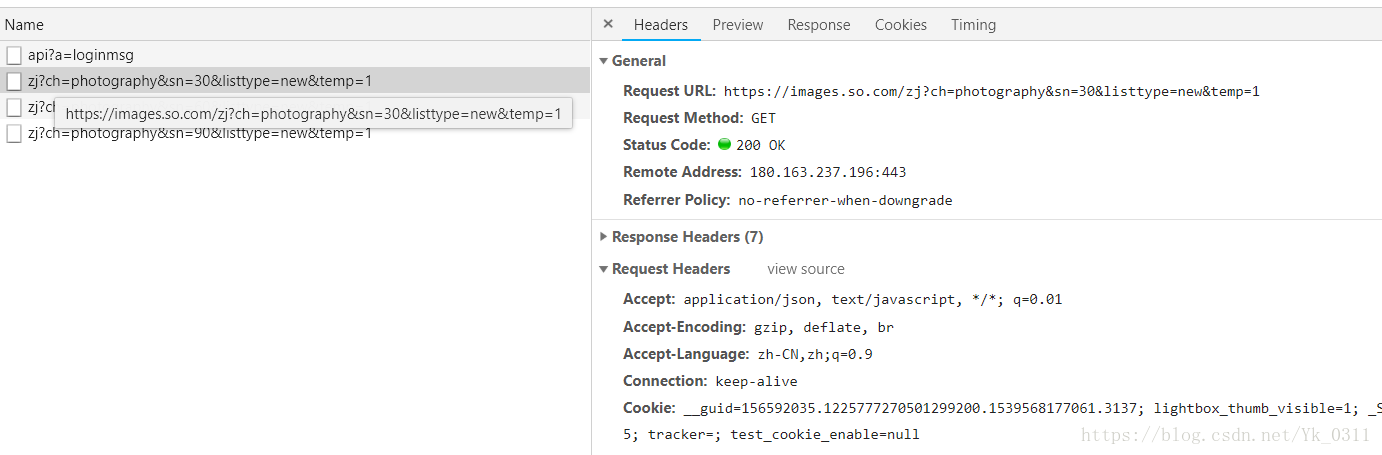
2.構造請求和提取資訊
# -*- coding: utf-8 -*- import scrapy from images360.settings import MAX_PAGE from images360.items import Images360Item import json class ImagesSpider(scrapy.Spider): name = 'images' ''' 這裡將start_urls 列表刪去了 start_urls: 它是起始URL列表,當我們沒有實現start_requests()方法時,預設會從這個列表開始抓取 ''' def start_requests(self): # 此方法用於生成初始請求,它必須返回一個可迭代物件 for page in range(MAX_PAGE): # MAX_PAGE在settings.py中定義好了 url = 'https://images.so.com/zj?ch=photography&sn={}&listtype=new&temp=1'.format(page * 30) yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): result = json.loads(response.body) item = Images360Item() for image in result.get('list'): # 遍歷一個列表 item['id'] = image.get('imageid') # ID item['url'] = image.get('qhimg_url') # url item['title'] = image.get('group_title') #標題 yield item
3.修改User-Agent
在middlewares.py 中新增一個RandomUserAgentMiddleware類
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agent = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0' 首先先定義了幾個不同的User-Agent,然後實現 process_request(request, spider) 方法,修改request的headers屬性的User-Agent,隨機選取了User-Agent
要使之生效需要在 settings.py 中取消DOWNLOADER_MIDDLEWARES註釋,並改寫成如下內容
DOWNLOADER_MIDDLEWARES = {
'images360.middlewares.RandomUserAgentMiddleware': 543,
}
4.將資料存入資料庫
# 連線資料時需要的引數
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'spiders'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'yellowkk'#密碼
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawler(cls, crawler): # 類方法,引數是crawler,通過此物件我們可以拿到Scrapy的所有核心元件
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT')
)
def open_spider(self, spider):
self.db = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port,
db=self.database, charset='utf8')
self.cursor = self.db.cursor()
def close_spider(self, spider):
self.db.close()
def process_item(self, item, spider):
data = dict(item) # item是一個類字典的型別,將其轉化為字典型別、
keys = ','.join(data.keys())
values = ','.join(['%s'] * len(data))
sql = 'insert into image360({}) values({})'.format(keys, values)#插入方法是一個動態構造SQL語句的方法
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
最後在 settings.py 中 設定ITEM_PIPELINES,如下
ITEM_PIPELINES = {
'images360.pipelines.MysqlPipeline': 300,
}