
XGBoost 模型 引數解釋
阿新 • • 發佈:2018-12-15
上篇博文介紹了xgboost這個演算法的推導,下面我們在調包使用這個演算法的時候,有一些引數是需要我們理解的。
這裡先講怎麼呼叫xgboost這個包進行運算 首先先引入這個包和資料(包可以用pip install xgboost進行下載)
import pandas as pd from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score data = pd.read_csv('pima-indians-diabetes.csv',header=None) X = data.iloc[:,0:8] y = data.iloc[:,8] test_size = 0.33 X_train , X_test , y_train , y_test = train_test_split(X,y,test_size = test_size,random_state = 7)
下面可以呼叫模型,fit函式一些引數的意思
- early_stopping_rounds:在連續加入五棵樹之後,每一次模型的損失函式都沒有下降,這時候停止加樹,有監控作用
- eval_metric:我們所選擇的損失函式
- eval_set:進行測試的資料集
model = XGBClassifier() eval_set = [(X_test, y_test)] model.fit(X_train,y_train,early_stopping_rounds=5,eval_metric="logloss",eval_set=eval_set) y_pred = model.predict(X_test) score = accuracy_score(y_test, y_pred) print(score)
結果見下圖:
[0] validation_0-logloss:0.660186 Will train until validation_0-logloss hasn't improved in 5 rounds. [1] validation_0-logloss:0.634854 [2] validation_0-logloss:0.612239 [3] validation_0-logloss:0.593118 [4] validation_0-logloss:0.578303 [5] validation_0-logloss:0.564942 [6] validation_0-logloss:0.555113 [7] validation_0-logloss:0.54499 [8] validation_0-logloss:0.539151 [9] validation_0-logloss:0.531819 [10] validation_0-logloss:0.526065 [11] validation_0-logloss:0.51977 [12] validation_0-logloss:0.514979 [13] validation_0-logloss:0.50927 [14] validation_0-logloss:0.506086 [15] validation_0-logloss:0.503565 [16] validation_0-logloss:0.503591 [17] validation_0-logloss:0.500805 [18] validation_0-logloss:0.497605 [19] validation_0-logloss:0.495328 [20] validation_0-logloss:0.494777 [21] validation_0-logloss:0.494274 [22] validation_0-logloss:0.493333 [23] validation_0-logloss:0.492211 [24] validation_0-logloss:0.491936 [25] validation_0-logloss:0.490578 [26] validation_0-logloss:0.490895 [27] validation_0-logloss:0.490646 [28] validation_0-logloss:0.491911 [29] validation_0-logloss:0.491407 [30] validation_0-logloss:0.488828 [31] validation_0-logloss:0.487867 [32] validation_0-logloss:0.487297 [33] validation_0-logloss:0.487562 [34] validation_0-logloss:0.487788 [35] validation_0-logloss:0.487962 [36] validation_0-logloss:0.488218 [37] validation_0-logloss:0.489582 Stopping. Best iteration: [32] validation_0-logloss:0.487297 0.7755905511811023
另外我們還可以通過呼叫xgboost裡面的plot_importance看看每個特徵的重要性:
from xgboost import plot_importance
from matplotlib import pyplot
plot_importance(model)
pyplot.show()
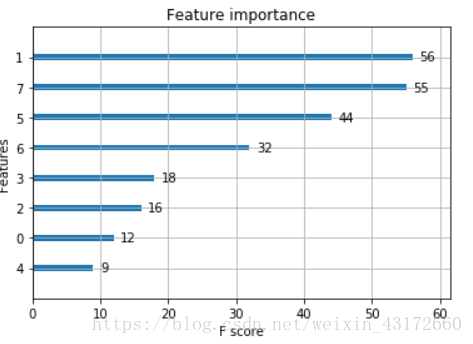
XGBoost 的引數
- eta:和 GBM 中的 learning rate 引數類似。 通過減少每一步的權重,可以提高模型的穩定性。 典型值為 0.01-0.2。
- min_child_weight:最小葉子節點權重和,如果在一次分裂中,葉子節點上所有樣本的權重和小於min_child_weight則停止分裂,能夠有效的防止過擬合,防止學到特殊樣本。
- max_depth:樹的最大深度,典型值:3-10
- max_leaf_nodes:樹上葉子節點數。
- gamma :懲罰項那個和葉子節點結合的項
- subsample:每棵樹隨機取樣的樣本的比例,減小這個引數的值,演算法會更加保守,避免過擬合。但是,如果這個值設定得過小,它可能會導致欠擬合。 典型值:0.5-1
- colsample_bytree:用來控制每棵隨機取樣的列數的佔比 (每一列是一個特徵)。 典型值:0.5-1
- lambda:權重的 L2 正則化項。
- alpha:權重的 L1 正則化項
- objective:定義損失函式,常用的值 reg:linear –線性迴歸。 reg:logistic–邏輯迴歸。 binary:logistic –二分類的邏輯迴歸問題,輸出為概率。 multi:softmax –讓XGBoost採用softmax目標函式處理多分類問題,同時需要設定引數num_class(類別個數)