
11.如何迅速分析出系統CPU的瓶頸在哪裡
前幾節裡,通過幾個案例,分析了各種常見的 CPU 效能問題。通過這些,相信對 CPU 的效能分析已經不再陌生和恐懼,起碼有了基本的思路,也瞭解了不少 CPU 效能的分析工 具。
不過,我猜你可能也碰到了一個我曾有過的困惑: CPU 的效能指標那麼多,CPU 效能分析工具 也是一抓一大把,如果離開專欄,換成實際的工作場景,我又該觀察什麼指標、選擇哪個效能工 具呢?
不要擔心,今天我就以多年的效能優化經驗,給你總結出一個“又快又準”的瓶頸定位套路,告 訴你在不同場景下,指標工具怎麼選,效能瓶頸怎麼找。
CPU 效能指標
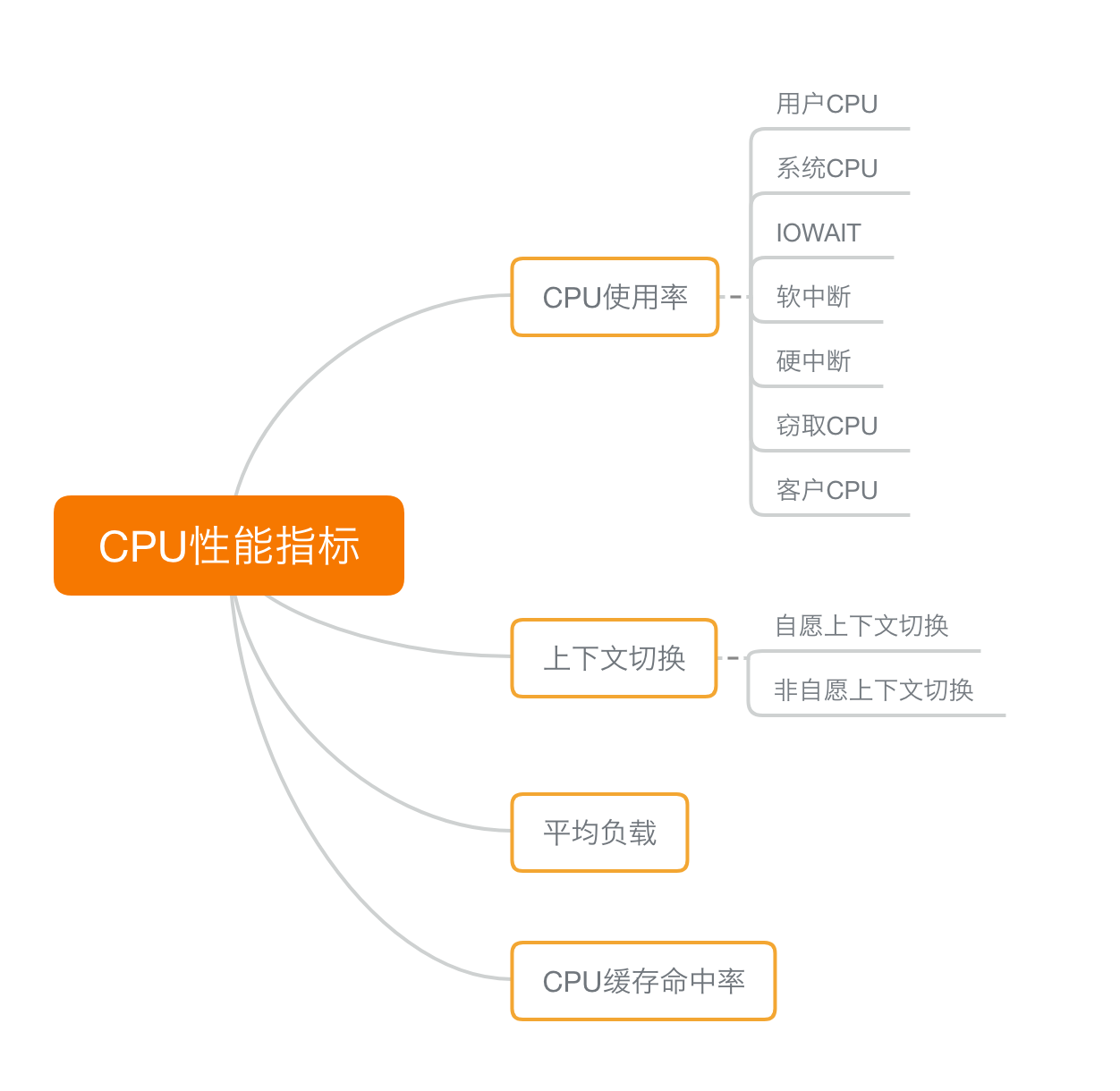
我們先來回顧下,描述 CPU 的效能指標都有哪些。你可以自己先找張紙,憑著記憶寫一寫;或 者開啟前面的文章,自己總結一下。
首先,最容易想到的應該是 CPU 使用率,這也是實際環境中最常見的一個性能指標。
CPU 使用率描述了非空閒時間佔總 CPU 時間的百分比,根據 CPU 上執行任務的不同,又被分 為使用者 CPU、系統 CPU、等待 I/O CPU、軟中斷和硬中斷等。
- 使用者 CPU 使用率,包括使用者態 CPU 使用率(user)和低優先順序使用者態 CPU 使用率 (nice),表示 CPU 在使用者態執行的時間百分比。使用者 CPU 使用率高,通常說明有應用程 序比較繁忙。
- 系統 CPU 使用率,表示 CPU 在核心態執行的時間百分比(不包括中斷)。系統 CPU 使用 率高,說明核心比較繁忙。
- 等待 I/O 的 CPU 使用率,通常也稱為 iowait,表示等待 I/O 的時間百分比。iowait 高,通 常說明系統與硬體裝置的 I/O 互動時間比較長。
- 軟中斷和硬中斷的 CPU 使用率,分別表示核心呼叫軟中斷處理程式、硬中斷處理程式的時間 百分比。它們的使用率高,通常說明系統發生了大量的中斷。
- 除了上面這些,還有在虛擬化環境中會用到的竊取 CPU 使用率(steal)和客戶 CPU 使用率 (guest),分別表示被其他虛擬機器佔用的 CPU 時間百分比,和執行客戶虛擬機器的 CPU 時 間百分比。
第二個比較容易想到的,應該是平均負載(Load Average)
理想情況下,平均負載等於邏輯 CPU 個數,這表示每個 CPU 都恰好被充分利用。如果平均負 載大於邏輯 CPU 個數,就表示負載比較重了。
第三個,也是在專欄學習前你估計不太會注意到的,程序上下文切換,包括:
- 無法獲取資源而導致的自願上下文切換;
- 被系統強制排程導致的非自願上下文切換。
上下文切換,本身是保證 Linux 正常執行的一項核心功能。但過多的上下文切換,會將原本運 行程序的 CPU 時間,消耗在暫存器、核心棧以及虛擬記憶體等資料的儲存和恢復上,縮短程序真 正執行的時間,成為效能瓶頸。
除了上面幾種,還有一個指標,CPU 快取的命中率。由於 CPU 發展的速度遠快於記憶體的發展, CPU 的處理速度就比記憶體的訪問速度快得多。這樣,CPU 在訪問記憶體的時候,免不了要等待內 存的響應。為了協調這兩者巨大的效能差距,CPU 快取(通常是多級快取)就出現了。
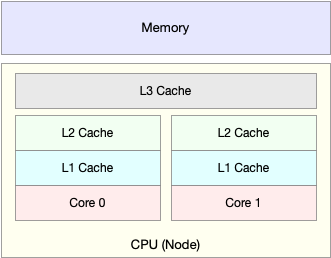
就像上面這張圖顯示的,CPU 快取的速度介於 CPU 和記憶體之間,快取的是熱點的記憶體資料。根 據不斷增長的熱點資料,這些快取按照大小不同分為 L1、L2、L3 等三級快取,其中 L1 和 L2 常用在單核中, L3 則用在多核中。
從 L1 到 L3,三級快取的大小依次增大,相應的,效能依次降低(當然比記憶體還是好得多)。 而它們的命中率,衡量的是 CPU 快取的複用情況,命中率越高,則表示效能越好。
這些指標都很有用,需要我們熟練掌握,所以我總結成了一張圖,幫你分類和記憶。你可以儲存 列印下來,隨時檢視複習,也可以當成 CPU 效能分析的“指標篩選”清單。
效能工具
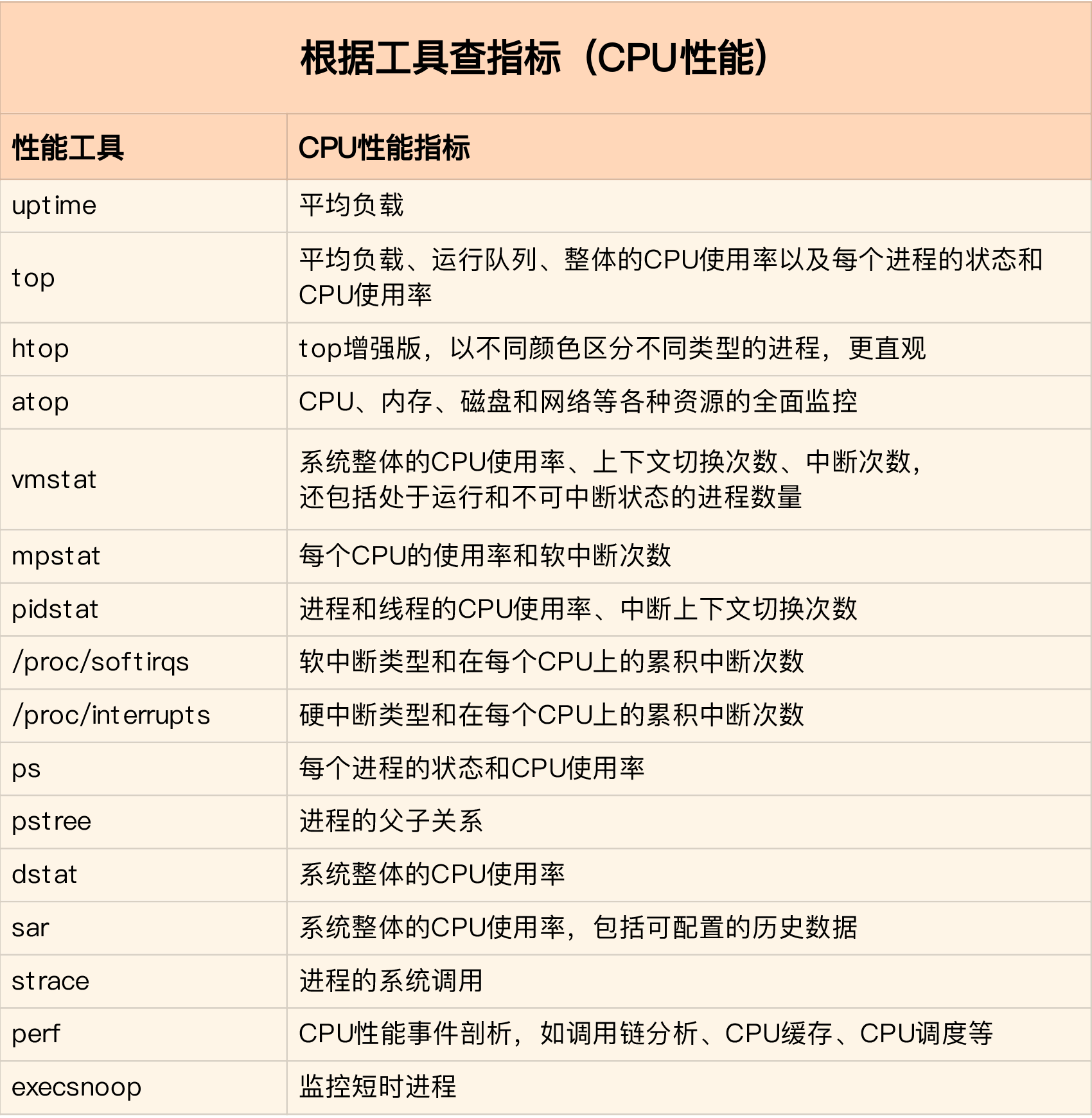
掌握了 CPU 的效能指標,我們還需要知道,怎樣去獲取這些指標,也就是工具的使用。
你還記得前面案例都用了哪些工具嗎?這裡我們也一起回顧一下 CPU 效能工具。
首先,平均負載的案例。我們先用 uptime, 查看了系統的平均負載;而在平均負載升高後,又 用 mpstat 和 pidstat ,分別觀察了每個 CPU 和每個程序 CPU 的使用情況,進而找出了導致平 均負載升高的程序,也就是我們的壓測工具 stress。
第二個,上下文切換的案例。我們先用 vmstat ,查看了系統的上下文切換次數和中斷次數;然 後通過 pidstat ,觀察了程序的自願上下文切換和非自願上下文切換情況;最後通過 pidstat , 觀察了執行緒的上下文切換情況,找出了上下文切換次數增多的根源,也就是我們的基準測試工具 sysbench。
第三個,程序 CPU 使用率升高的案例。我們先用 top ,查看了系統和程序的 CPU 使用情況, 發現 CPU 使用率升高的程序是 php-fpm;再用 perf top ,觀察 php-fpm 的呼叫鏈,最終找 出 CPU 升高的根源,也就是庫函式 sqrt() 。
第四個,系統的 CPU 使用率升高的案例。我們先用 top 觀察到了系統 CPU 升高,但通過 top 和 pidstat ,卻找不出高 CPU 使用率的程序。於是,我們重新審視 top 的輸出,又從 CPU 使 用率不高但處於 Running 狀態的程序入手,找出了可疑之處,最終通過 perf record 和 perf report ,發現原來是短時程序在搗鬼。
另外,對於短時程序,我還介紹了一個專門的工具 execsnoop,它可以實時監控程序呼叫的外 部命令。
第五個,不可中斷程序和殭屍程序的案例。我們先用 top 觀察到了 iowait 升高的問題,並發現 了大量的不可中斷程序和殭屍程序;接著我們用 dstat 發現是這是由磁碟讀導致的,於是又通過 pidstat 找出了相關的程序。但我們用 strace 檢視程序系統呼叫卻失敗了,最終還是用 perf 分 析程序呼叫鏈,才發現根源在於磁碟直接 I/O 。
最後一個,軟中斷的案例。我們通過 top 觀察到,系統的軟中斷 CPU 使用率升高;接著檢視 /proc/softirqs, 找到了幾種變化速率較快的軟中斷;然後通過 sar 命令,發現是網路小包的問 題,最後再用 tcpdump ,找出網路幀的型別和來源,確定是一個 SYN FLOOD 攻擊導致的。
到這裡,估計你已經暈了吧,原來短短几個案例,我們已經用過十幾種 CPU 效能工具了,而且 每種工具的適用場景還不同呢!這麼多的工具要怎麼區分呢?在實際的效能分析中,又該怎麼選 擇呢?
我的經驗是,從兩個不同的維度來理解它們,做到活學活用。
活學活用,把效能指標和效能工具聯絡起來
第一個維度,從 CPU 的效能指標出發。也就是說,當你要檢視某個效能指標時,要清楚知道哪 些工具可以做到。
根據不同的效能指標,對提供指標的效能工具進行分類和理解。這樣,在實際排查效能問題時, 你就可以清楚知道,什麼工具可以提供你想要的指標,而不是毫無根據地挨個嘗試,撞運氣。
其實,我在前面的案例中已經多次用到了這個思路。比如用 top 發現了軟中斷 CPU 使用率高 後,下一步自然就想知道具體的軟中斷型別。那在哪裡可以觀察各類軟中斷的執行情況呢?當然 是 proc 檔案系統中的 /proc/softirqs 這個檔案。
緊接著,比如說,我們找到的軟中斷型別是網路接收,那就要繼續往網路接收方向思考。系統的 網路接收情況是什麼樣的?什麼工具可以查到網路接收情況呢?在我們案例中,用的正是雖然你不需要把所有工具背下來,但如果能理解每個指標對應的工具的特性,一定更高效、更靈 活地使用。這裡,我把提供 CPU 效能指標的工具做成了一個表格,方便你梳理關係和理解記 憶,當然,你也可以當成一個“指標工具”指南來使用。
下面,我們再來看第二個維度。
第二個維度,從工具出發。也就是當你已經安裝了某個工具後,要知道這個工具能提供哪些指 標。
這在實際環境特別是生產環境中也是非常重要的,因為很多情況下,你並沒有許可權安裝新的工具 包,只能最大化地利用好系統中已經安裝好的工具,這就需要你對它們有足夠的瞭解。
具體到每個工具的使用方法,一般都支援豐富的配置選項。不過不用擔心,這些配置選項並不用 背下來。你只要知道有哪些工具、以及這些工具的基本功能是什麼就夠了。真正要用到的時候, 通過 man 命令,查它們的使用手冊就可以了。
同樣的,我也將這些常用工具彙總成了一個表格,方便你區分和理解,自然,你也可以當成一 個“工具指標”指南使用,需要時查表即可。

如何迅速分析 CPU 的效能瓶頸
我相信到這一步,你對 CPU 的效能指標已經非常熟悉,也清楚每種效能指標分別能用什麼工具 來獲取。
那是不是說,每次碰到 CPU 的效能問題,你都要把上面這些工具全跑一遍,然後再把所有的 CPU 效能指標全分析一遍呢?
你估計覺得這種簡單查詢的方式,就像是在傻找。不過,別笑話,因為最早的時候我就是這麼做 的。把所有的指標都查出來再統一分析,當然是可以的,也很可能找到系統的潛在瓶頸。
但是這種方法的效率真的太低了!耗時耗力不說,在龐大的指標體系面前,你一不小心可能就忽 略了某個細節,導致白乾一場。我就吃過好多次這樣的苦。
所以,在實際生產環境中,我們通常都希望儘可能快地定位系統的瓶頸,然後儘可能快地優化性 能,也就是要又快又準地解決效能問題。
那有沒有什麼方法,可以又快又準找出系統瓶頸呢?答案是肯定的。
雖然 CPU 的效能指標比較多,但要知道,既然都是描述系統的 CPU 效能,它們就不會是完全 孤立的,很多指標間都有一定的關聯。想弄清楚效能指標的關聯性,就要通曉每種效能指標的工 作原理。這也是為什麼我在介紹每個效能指標時,都要穿插講解相關的系統原理,希望你能記住 這一點。
舉個例子,使用者 CPU 使用率高,我們應該去排查程序的使用者態而不是核心態。因為使用者 CPU 使用率反映的就是使用者態的 CPU 使用情況,而核心態的 CPU 使用情況只會反映到系統 CPU 使 用率上。
你看,有這樣的基本認識,我們就可以縮小排查的範圍,省時省力。
所以,為了縮小排查範圍,我通常會先執行幾個支援指標較多的工具,如 top、vmstat 和 pidstat 。為什麼是這三個工具呢?仔細看看下面這張圖,你就清楚了。
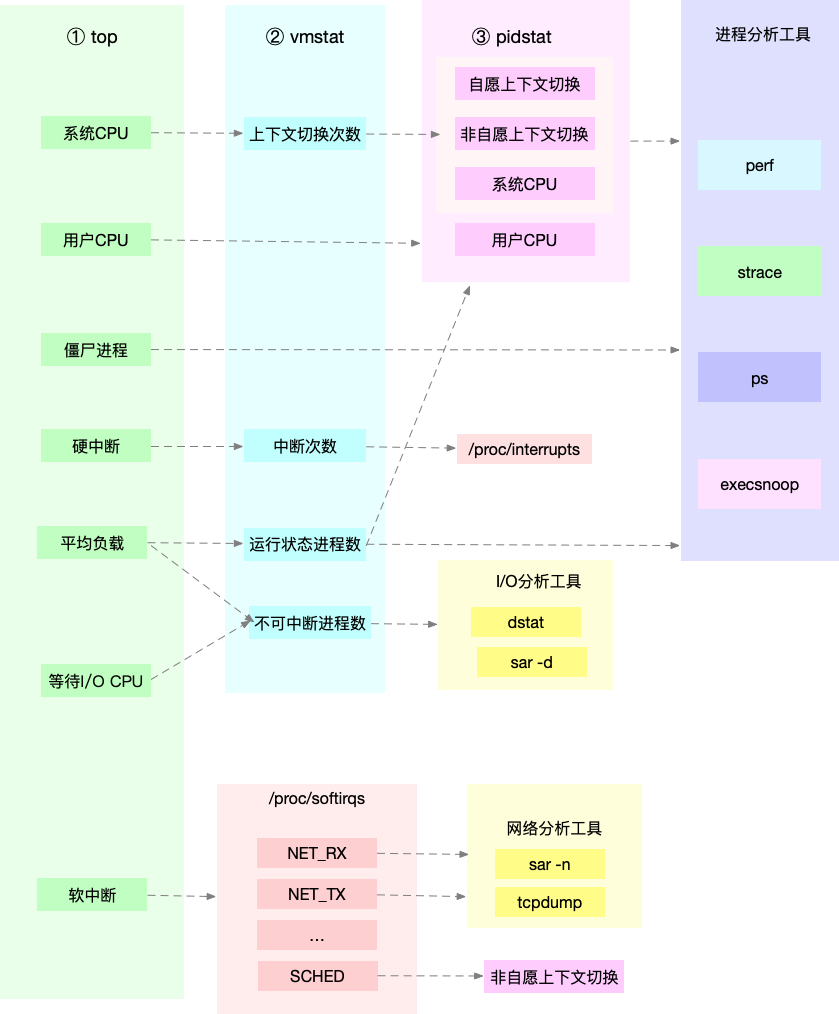
這張圖裡,我列出了 top、vmstat 和 pidstat 分別提供的重要的 CPU 指標,並用虛線表示關聯 關係,對應出了效能分析下一步的方向。
通過這張圖你可以發現,這三個命令,幾乎包含了所有重要的 CPU 效能指標,比如:
- 從 top 的輸出可以得到各種 CPU 使用率以及殭屍程序和平均負載等資訊。
- 從 vmstat 的輸出可以得到上下文切換次數、中斷次數、執行狀態和不可中斷狀態的程序 數。
- 從 pidstat 的輸出可以得到程序的使用者 CPU 使用率、系統 CPU 使用率、以及自願上下文切 換和非自願上下文切換情況。
另外,這三個工具輸出的很多指標是相互關聯的,所以,我也用虛線表示了它們的關聯關係,舉 幾個例子你可能會更容易理解。
第一個例子,pidstat 輸出的程序使用者 CPU 使用率升高,會導致 top 輸出的使用者 CPU 使用率 升高。所以,當發現 top 輸出的使用者 CPU 使用率有問題時,可以跟 pidstat 的輸出做對比,觀 察是否是某個程序導致的問題。
而找出導致效能問題的程序後,就要用程序分析工具來分析程序的行為,比如使用 strace 分析
系統呼叫情況,以及使用 perf 分析呼叫鏈中各級函式的執行情況。
第二個例子,top 輸出的平均負載升高,可以跟 vmstat 輸出的執行狀態和不可中斷狀態的程序 數做對比,觀察是哪種程序導致的負載升高。
- 如果是不可中斷程序數增多了,那麼就需要做 I/O 的分析,也就是用 dstat 或 sar 等工具, 進一步分析 I/O 的情況。
- 如果是執行狀態程序數增多了,那就需要回到 top 和 pidstat,找出這些處於執行狀態的到 底是什麼程序,然後再用程序分析工具,做進一步分析。
最後一個例子,當發現 top 輸出的軟中斷 CPU 使用率升高時,可以檢視 /proc/softirqs 檔案中 各種型別軟中斷的變化情況,確定到底是哪種軟中斷出的問題。比如,發現是網路接收中斷導致 的問題,那就可以繼續用網路分析工具 sar 和 tcpdump 來分析。
注意,我在這個圖中只列出了最核心的幾個效能工具,並沒有列出所有。這麼做,一方面是不想 用大量的工具列表嚇到你。在學習之初就接觸所有或核心或小眾的工具,不見得是好事。另一方 面,是希望你能先把重心放在核心工具上,畢竟熟練掌握它們,就可以解決大多數問題。
所以,你可以儲存下這張圖,作為 CPU 效能分析的思路圖譜。從最核心的這幾個工具開始,通 過我提供的那些案例,自己在真實環境裡實踐,拿下它們。 小結 今天,我帶你回憶了常見的 CPU 效能指標,梳理了常見的 CPU 效能觀測工具,最後還總結了 快速分析 CPU 效能問題的思路。 雖然 CPU 的效能指標很多,相應的效能分析工具也很多,但熟悉了各種指標的含義之後,你就 會發現它們其實都有一定的關聯。順著這個思路,掌握常用的分析套路並不難。