urlib常見異常處理與url解析
阿新 • • 發佈:2018-12-15
一.urlib異常處理
1、URLError異常
通常引起URLError的原因是:無網路連線(沒有到目標伺服器的路由)、訪問的目標伺服器不存在。在這種情況下,異常物件會有reason屬性(是一個(錯誤碼、錯誤原因)的元組)1)訪問成功時:
from urllib import request, error try: url = 'https://www.baidu.com/hello.html' response = request.urlopen(url) print(response.read().decode('utf-8')) except error.HTTPError as e: print(e.reason, e.code, e.headers, sep='\n') except error.URLError as e: print(e.reason) else: print("成功")
我們可以成功的訪問到百度頁面

2)有異常時
from urllib import request, error
url = 'https://www.baidu.com/hello.html'
response = request.urlopen(url)
print(response.read().decode('utf-8'))
這裡我斷開了網路,出現了URLError

2、HTTPError
每一個從伺服器返回的HTTP響應都有一個狀態碼。其中,有的狀態碼錶示伺服器不能完成相應的請求,預設的處理程式可以為我們處理一些這樣的狀態碼(如返回的響應是重定向,urllib2會自動為我們從重定向後的頁面中獲取資訊)。有些狀態碼,urllib2模組不能幫我們處理,那麼urlopen函式就會引起HTTPError異常,其中典型的有404/401
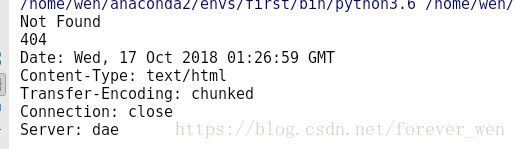
##因為URLError是HTTPError的父類,所以在捕獲異常的時候可以先找子類是否異常,如果子類找不到,再找父類即可 from urllib import request, error try: url = 'http://www.douban.com/hello89.html' response = request.urlopen(url) print(response.read().decode('utf-8')) except error.HTTPError as e: print(e.reason, e.code, e.headers, sep='\n') except error.URLError as e: print(e.reason) else: print("成功")
上例是我訪問一個豆瓣不存在的網頁
常見狀態返回碼
100:繼續 客戶端應當繼續傳送請求。客戶端應當繼續傳送請求的剩餘部分,或者如果請求已經完成,忽略這個響應。
101: 轉換協議 在傳送完這個響應最後的空行後,伺服器將會切換到在Upgrade 訊息頭中定義的那些協議。只有在切換新的協議更有好處的時候才應該採取類似措施。
102:繼續處理 由WebDAV(RFC 2518)擴充套件的狀態碼,代表處理將被繼續執行。
200:請求成功 處理方式:獲得響應的內容,進行處理 201:請求完成,結果是建立了新資源。新建立資源的URI可在響應的實體中得到 處理方式:爬蟲中不會遇到
202:請求被接受,但處理尚未完成 處理方式:阻塞等待
204:伺服器端已經實現了請求,但是沒有返回新的信 息。如果客戶是使用者代理,則無須為此更新自身的文件檢視。 處理方式:丟棄
300:該狀態碼不被HTTP/1.0的應用程式直接使用, 只是作為3XX型別迴應的預設解釋。存在多個可用的被請求資源。 處理方式:若程式中能夠處理,則進行進一步處理,如果程式中不能處理,則丟棄
301:請求到的資源都會分配一個永久的URL,這樣就可以在將來通過該URL來訪問此資源 處理方式:重定向到分配的URL
302:請求到的資源在一個不同的URL處臨時儲存 處理方式:重定向到臨時的URL
304:請求的資源未更新 處理方式:丟棄 400:非法請求 處理方式:丟棄
401:未授權 處理方式:丟棄
403:禁止 處理方式:丟棄
404:沒有找到 處理方式:丟棄
500:伺服器內部錯誤 伺服器遇到了一個未曾預料的狀況,導致了它無法完成對請求的處理。一般來說,這個問題都會在伺服器端的原始碼出現錯誤時出現。
501:伺服器無法識別 伺服器不支援當前請求所需要的某個功能。當伺服器無法識別請求的方法,並且無法支援其對任何資源的請求。
502:錯誤閘道器 作為閘道器或者代理工作的伺服器嘗試執行請求時,從上游伺服器接收到無效的響應。
503:服務出錯 由於臨時的伺服器維護或者過載,伺服器當前無法處理請求。這個狀況是臨時的,並且將在一段時間以後恢復。
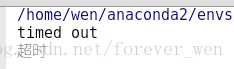
3、超時異常處理
為了捕獲超時異常,我在這裡設定了時間限制,當響應超過0.01s時,就會認為超時。from urllib import request, error
import socket
try:
url = 'https://www.baidu.com'
response = request.urlopen(url, timeout=0.01)
print(response.read().decode('utf-8'))
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
if isinstance(e.reason, socket.timeout):
print("超時")
else:
print("成功")