
HashMap 的底層原理(JDK1.7以前)
1. HashMap的資料結構
資料結構中有陣列和連結串列來實現對資料的儲存,但這兩者基本上是兩個極端。
陣列
陣列儲存區間是連續的,佔用記憶體嚴重,故空間複雜的很大。但陣列的二分查詢時間複雜度小,為O(1);陣列的特點是:定址容易,插入和刪除困難;
連結串列
連結串列儲存區間離散,佔用記憶體比較寬鬆,故空間複雜度很小,但時間複雜度很大,達O(N)。連結串列的特點是:定址困難,插入和刪除容易。
雜湊表
那麼我們能不能綜合兩者的特性,做出一種定址容易,插入刪除也容易的資料結構?答案是肯定的,這就是我們要提起的雜湊表。雜湊表((Hash table)既滿足了資料的查詢方便,同時不佔用太多的內容空間,使用也十分方便。
雜湊表有多種不同的實現方法,我接下來解釋的是最常用的一種方法—— 拉鍊法,我們可以理解為“連結串列的陣列” ,如圖:
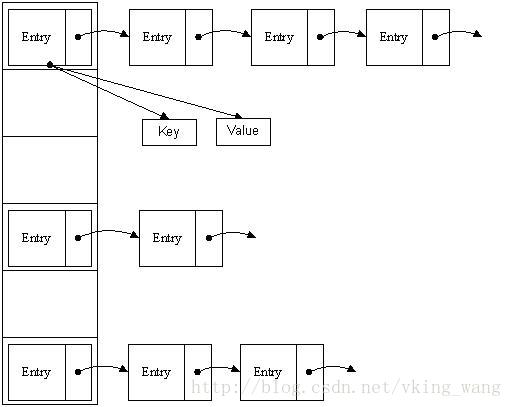
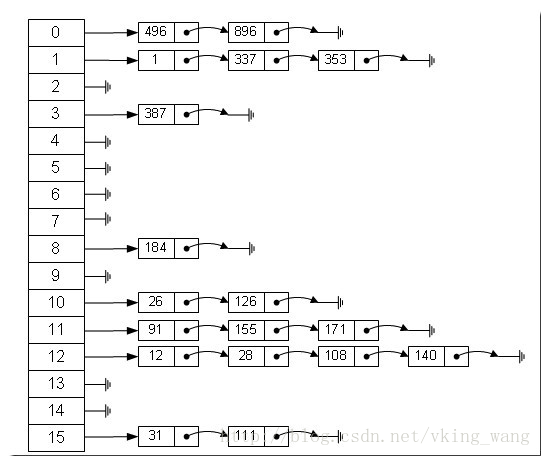
從上圖我們可以發現雜湊表是由陣列+連結串列組成的,一個長度為16的陣列中,每個元素儲存的是一個連結串列的頭結點。那麼這些元素是按照什麼樣的規則儲存到陣列中呢。一般情況是通過hash(key)%len獲得,也就是元素的key的雜湊值對陣列長度取模得到。比如上述雜湊表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都儲存在陣列下標為12的位置。
HashMap其實也是一個線性的陣列實現的,所以可以理解為其儲存資料的容器就是一個線性陣列。這可能讓我們很不解,一個線性的陣列怎麼實現按鍵值對來存取資料呢?這裡HashMap有做一些處理。
首先HashMap裡面實現一個靜態內部類Entry,其重要的屬性有 key , value, next,從屬性key,value我們就能很明顯的看出來Entry就是HashMap鍵值對實現的一個基礎bean,我們上面說到HashMap的基礎就是一個線性陣列,這個陣列就是Entry[],Map裡面的內容都儲存在Entry[]裡面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
2. HashMap的存取實現
既然是線性陣列,為什麼能隨機存取?這裡HashMap用了一個小演算法,大致是這樣實現:
// 儲存時:
int hash = key.hashCode(); // 這個hashCode方法這裡不詳述,只要理解每個key的hash是一個固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值時:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
1)put
疑問:如果兩個key通過hash%Entry[].length得到的index相同,會不會有覆蓋的危險?
這裡HashMap裡面用到鏈式資料結構的一個概念。上面我們提到過Entry類裡面有一個next屬性,作用是指向下一個Entry。打個比方, 第一個鍵值對A進來,通過計算其key的hash得到的index=0,記做:Entry[0] = A。一會後又進來一個鍵值對B,通過計算其index也等於0,現在怎麼辦?HashMap會這樣做:B.next = A,Entry[0] = B,如果又進來C,index也等於0,那麼C.next = B,Entry[0] = C;這樣我們發現index=0的地方其實存取了A,B,C三個鍵值對,他們通過next這個屬性連結在一起。所以疑問不用擔心。也就是說陣列中儲存的是最後插入的元素。到這裡為止,HashMap的大致實現,我們應該已經清楚了。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null總是放在陣列的第一個連結串列中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍歷連結串列
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在連結串列中已存在,則替換為新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //引數e, 是Entry.next
//如果size超過threshold,則擴充table大小。再雜湊
if (size++ >= threshold)
resize(2 * table.length);
}
當然HashMap裡面也包含一些優化方面的實現,這裡也說一下。比如:Entry[]的長度一定後,隨著map裡面資料的越來越長,這樣同一個index的鏈就會很長,會不會影響效能?HashMap裡面設定一個因子,隨著map的size越來越大,Entry[]會以一定的規則加長長度。
2)get
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到陣列元素,再遍歷該元素處的連結串列
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
3)null key的存取
null key總是存放在Entry[]陣列的第一個元素。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
4)確定陣列index:hashcode % table.length取模
HashMap存取時,都需要計算當前key應該對應Entry[]陣列哪個元素,即計算陣列下標;演算法如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取並,作用上相當於取模mod或者取餘%。
這意味著陣列下標相同,並不表示hashCode相同。
5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
注意table初始大小並不是建構函式中的initialCapacity!!
而是 >= initialCapacity的2的n次冪!!!!
————為什麼這麼設計呢?——
3. 解決hash衝突的辦法
- 開放定址法(線性探測再雜湊,二次探測再雜湊,偽隨機探測再雜湊)
- 再雜湊法
- 鏈地址法
- 建立一個公共溢位區
Java中hashmap的解決辦法就是採用的鏈地址法。
4. 再雜湊rehash過程
當雜湊表的容量超過預設容量時,必須調整table的大小。當容量已經達到最大可能值時,那麼該方法就將容量調整到Integer.MAX_VALUE返回,這時,需要建立一張新表,將原表的對映到新表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新計算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}