
初學者CentOS7安裝hadoop-2.8.0叢集詳細過程以及問題解決
一、安裝前準備
- VMware-workstation-full-10.0.4
- CentOS-7-x86_64-DVD-1804.iso映象
- jdk-8u181-linux-x64.tar.gz
- hadoop-2.8.0.tar.gz
- 二、安裝過程
- 虛擬機器設定
(1)3臺虛擬機器
一臺命名master,作為namenode節點
一臺命名slave1, 作為datanode節點
一臺命名slave2, 作為datanode節點
(2)虛擬機器配置
每臺虛擬機器設定2g記憶體(選1g後邊hadoop計算會報記憶體不夠)
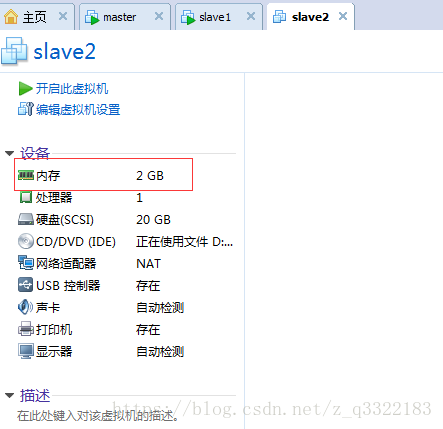
提示:先安裝並配置好master,然後克隆master兩次得到slave1和slave2)
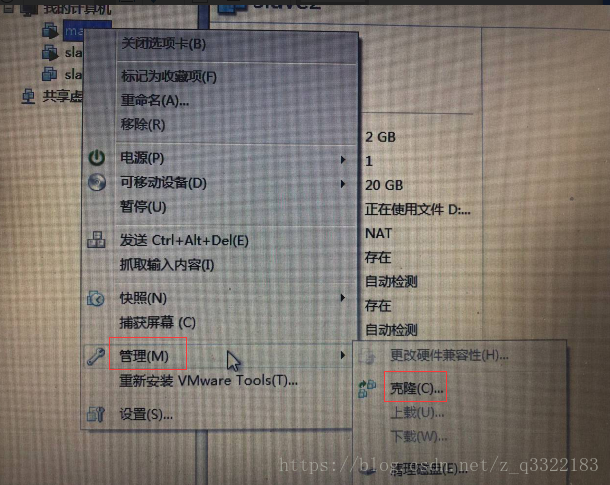
(3) 虛擬機器名字修改
安裝完三臺虛擬機器後,分別修改它們的主機名字為master 、slave1、slave2
檢視主機名字:hostname
修改主機名字:hostname master
(4) IP設定
1)分別從三個虛擬機器獲取IP 地址,使用vim /etc/hosts
2)將三臺機子的IP地址以及對應的主機名新增到檔案/etc/hosts (三臺虛擬機器都需要做這個步驟)

(5)SSH免密碼登入
1)使用命令ssh-keygen -t rsa 生成公鑰(三個機器都需要進行這個步驟)
2)在/root/.ssh資料夾下,可以看到產生了兩個檔案
3)將三臺機器的公鑰放到檔案authorized_keys裡
cat id_rsa.pub >> authorized_keys(master)
scp authorized_keys [email protected]:/root/.ssh (將帶有master的公鑰的檔案authorized_keys 傳到機器slave1的/root/.ssh資料夾內)
cat id_rsa.pub >> authorized_keys(slave1)
slave2同理,最後在每臺機器上都存放帶有三臺機器公鑰的authorized_keys檔案
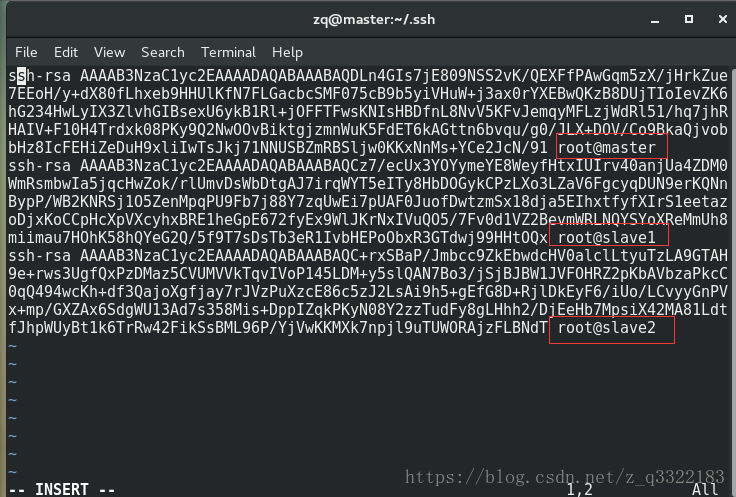
4)ssh無密碼登入測試
三臺機器之間是可以互相登入的

2. 安裝JDK (三臺機器都需要安裝)
(1)解除安裝虛擬機器自帶的JDK
CentOS7會自帶JDK, 所以我選擇解除安裝自帶的再自行安裝一個
1)查詢系統自帶的JDK: rpm -qa | grep Java
2) 刪除所有不帶noarch檔案: 例如rpm -e –nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
3)java –version, 沒有看大有JDK
(2)安裝JDK
(1) 在/home下新建資料夾java
(2) 將下載好的jdk-8u181-linux-x64.tar.gz拷貝到資料夾java並解壓
(3)JDK環境變數配置:
1)vim /etc/profile
2) 以下三行程式碼放到檔案的最底端
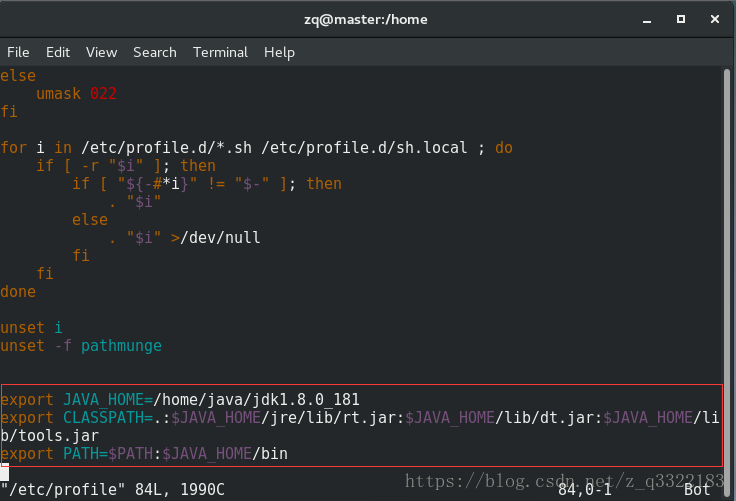
3)source /etc/profile (使環境變數起作用)

3. 安裝hadoop 2.8.0
- 在/home下新建資料夾hadoop
- 將下載好的hadoop-2.8.0.tar.gz放到/home/hadoop並解壓
- 在/home/hadoop新建dfs、tmp、 dfs/data、 dfs/name四個資料夾
- 配置檔案
1)修改 /home/hadoop/hadoop-2.8.0/etc/hadoop資料夾下的
core-site.xml檔案(新增紅框部分,需要對應主機名和檔案路徑)
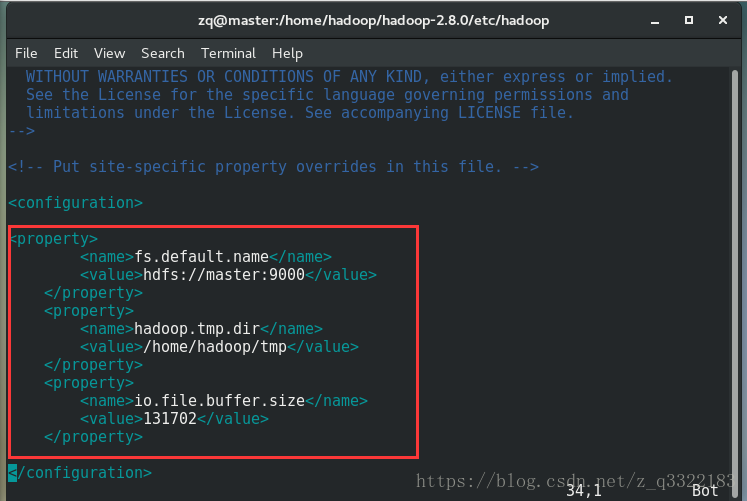
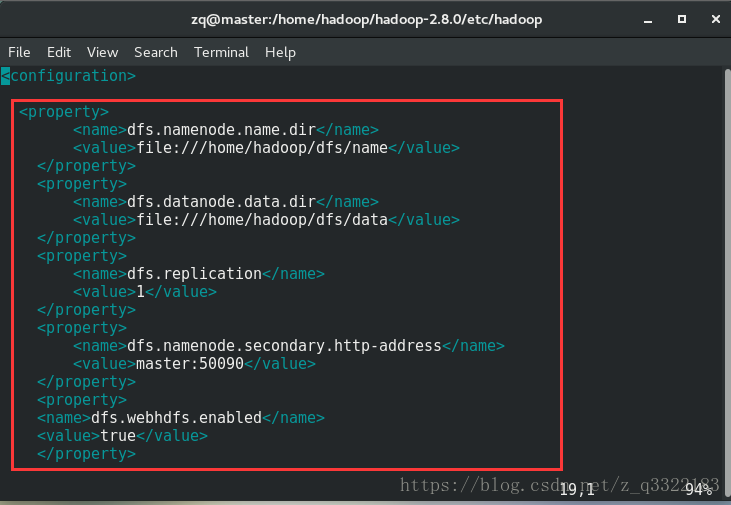
2)修改 /home/hadoop/hadoop-2.8.0/etc/hadoop資料夾下的hdfs-site.xml(新增紅框部分,需要對應自己的主機名和檔案路徑)
3)修改/home/hadoop/hadoop-2.8.0/etc/hadoop資料夾下的mapred-site.xml(首先複製檔案cp mapred-site.xml.template mapred-site.xml)

4) 修改/home/hadoop/hadoop-2.8.0/etc/hadoop資料夾下的yarn-site.xml
(這裡配2048即2g記憶體)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>
5) 修改/home/hadoop/hadoop-2.8.0/etc/hadoop資料夾下的hadoop-env.sh、yarn-env.sh
將export JAVA_HOME={$JAVA_HOME}修改為機器JDK安裝路徑
即export JAVA_HOME=/home/java/jdk1.8.0_181
6)修改/home/hadoop/hadoop-2.8.0/etc/hadoop資料夾下的slaves檔案刪除預設的localhost,新增slave、slave2
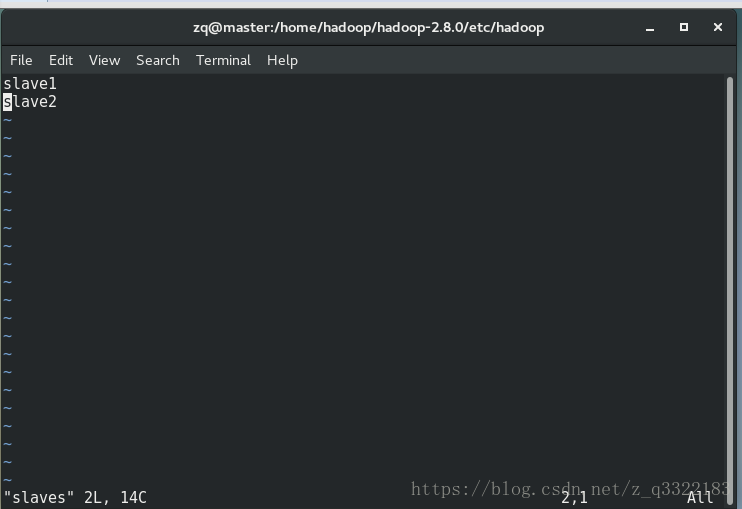
7) 將master機器配好的hadoop 複製到slave1、slave2
scp –r /home/hadoop slave1:/home
scp –r /home/hadoop slave2:/home
4. 啟動hadoop
只需要在master機器上格式化和啟動hadoop即可
(1)格式化
1)關閉防火牆:
systemctl stop firewalld.service(臨時關閉)
systemctl disable firewalld.service(永久關閉)
2)格式化(在資料夾下進行/home/hadoop/hadoop-2.8.0)
bin/hdfs namenode –format
3)啟動hadoop
sbin/start-all.sh
4)在master機器上使用jps檢視

5)在slave機器上使用jps檢視

5. Hadoop程式測試
示例:統計檔案中各單詞的數目
(1) 在/home/hadoop 資料夾下新建資料夾file
(2) 在資料夾file下新建兩個flie1.txt、file2.txt檔案
(3) 執行echo "zq is a silly girl" > file1.txt,即將這句話寫入file1.txt
(4)將file1.txt、file2.txt put到HDFS裡(在資料夾下進行/home/hadoop/hadoop-2.8.0)
1)新建資料夾input: bin/hadoop fs –mkdir /input
2) bin/hadoop fs -put /home/hadoop/file/file1.txt /input
bin/hadoop fs -put /home/hadoop/file/file2.txt /input
(這個時候報錯)
18/10/18 03:03:38 WARN hdfs.DataStreamer: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /input/file1.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1733)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:265)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2496)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:828)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:506)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:447)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:845)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:788)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1807)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2455)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1481)
at org.apache.hadoop.ipc.Client.call(Client.java:1427)
at org.apache.hadoop.ipc.Client.call(Client.java:1337)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy10.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:440)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:398)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:335)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DataStreamer.locateFollowingBlock(DataStreamer.java:1733)
at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1536)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:658)
put: File /input/file1.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
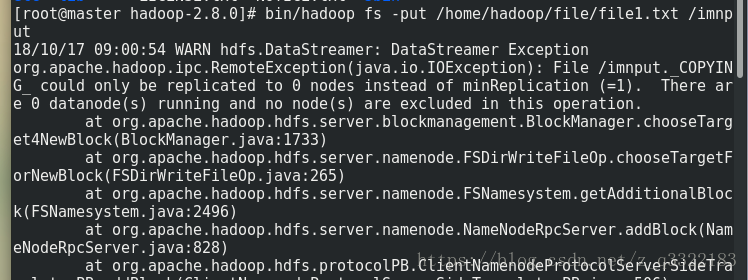
經過多方查詢,發現是datanode節點沒有連上,原因竟是多次格式化造成的
解決方法:
master機器上:rm –rf /home/hadoop/dfs/name/current
slave機器上: rm –rf /home/hadoop/dfs/data/current
重新格式化 (在資料夾下進行/home/hadoop/hadoop-2.8.0)
bin/hdfs namenode –format
sbin/start-all.sh
1)新建資料夾input: bin/hadoop fs –mkdir /input
2) bin/hadoop fs -put /home/hadoop/file/file1.txt /input
bin/hadoop fs -put /home/hadoop/file/file2.txt /input
3) bin/hadoop fs –ls /input

解決啦!!! 嗨森!!!
(5)在資料夾/home/hadoop/hadoop-2.8.0下執行以下命令
bin/hadoop jar
/home/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /input /output2
檢視統計結果:
