
深入分析 Java I/O 的工作機制
Java 的 I/O 類庫的基本架構
I/O 問題是任何程式語言都無法迴避的問題,可以說 I/O 問題是整個人機互動的核心問題,因為 I/O 是機器獲取和交換資訊的主要渠道。在當今這個資料大爆炸時代,I/O 問題尤其突出,很容易成為一個性能瓶頸。正因如此,所以 Java 在 I/O 上也一直在做持續的優化,如從 1.4 開始引入了 NIO,提升了 I/O 的效能。關於 NIO 我們將在後面詳細介紹。
Java 的 I/O 操作類在包 java.io 下,大概有將近 80 個類,但是這些類大概可以分成四組,分別是:
- 基於位元組操作的 I/O 介面:InputStream 和 OutputStream
- 基於字元操作的 I/O 介面:Writer 和 Reader
- 基於磁碟操作的 I/O 介面:File
- 基於網路操作的 I/O 介面:Socket
前兩組主要是根據傳輸資料的資料格式,後兩組主要是根據傳輸資料的方式,雖然 Socket 類並不在 java.io 包下,但是我仍然把它們劃分在一起,因為我個人認為 I/O 的核心問題要麼是資料格式影響 I/O 操作,要麼是傳輸方式影響 I/O 操作,也就是將什麼樣的資料寫到什麼地方的問題,I/O 只是人與機器或者機器與機器互動的手段,除了在它們能夠完成這個互動功能外,我們關注的就是如何提高它的執行效率了,而資料格式和傳輸方式是影響效率最關鍵的因素了。我們後面的分析也是基於這兩個因素來展開的。
基於位元組的 I/O 操作介面
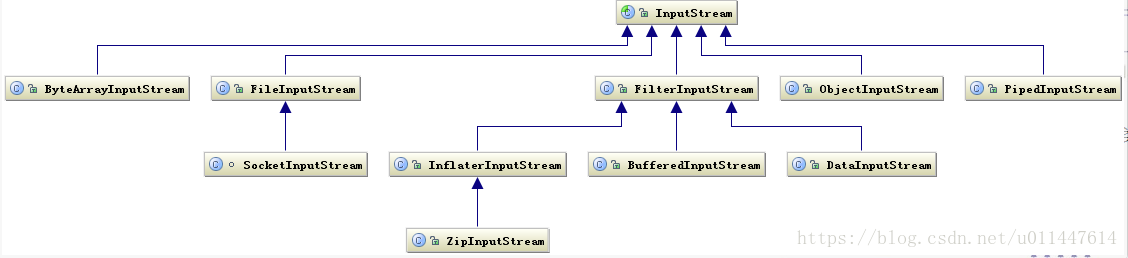
基於位元組的 I/O 操作介面輸入和輸出分別是:InputStream 和 OutputStream,InputStream 輸入流的類繼承層次如下圖所示:
圖 1. InputStream 相關類層次結構(檢視大圖)
{kind=link}
輸入流根據資料型別和操作方式又被劃分成若干個子類,每個子類分別處理不同操作型別,OutputStream 輸出流的類層次結構也是類似,如下圖所示:
圖 2. OutputStream 相關類層次結構(檢視大圖)
{kind=link}

這裡就不詳細解釋每個子類如何使用了,如果不清楚的話可以參考一下 JDK 的 API 說明文件,這裡只想說明兩點,一個是操作資料的方式是可以組合使用的,如這樣組合使用
OutputStream out = new BufferedOutputStream(new ObjectOutputStream(new FileOutputStream("fileName"));
還有一點是流最終寫到什麼地方必須要指定,要麼是寫到磁碟要麼是寫到網路中,其實從上面的類圖中我們發現,寫網路實際上也是寫檔案,只不過寫網路還有一步需要處理就是底層作業系統再將資料傳送到其它地方而不是本地磁碟。關於網路 I/O 和磁碟 I/O 我們將在後面詳細介紹。
基於字元的 I/O 操作介面
不管是磁碟還是網路傳輸,最小的儲存單元都是位元組,而不是字元,所以 I/O 操作的都是位元組而不是字元,但是為啥有操作字元的 I/O 介面呢?這是因為我們的程式中通常操作的資料都是以字元形式,為了操作方便當然要提供一個直接寫字元的 I/O 介面,如此而已。我們知道字元到位元組必須要經過編碼轉換,而這個編碼又非常耗時,而且還會經常出現亂碼問題,所以 I/O 的編碼問題經常是讓人頭疼的問題。關於 I/O 編碼問題請參考另一篇文章 《深入分析Java中的中文編碼問題》。
下圖是寫字元的 I/O 操作介面涉及到的類,Writer 類提供了一個抽象方法 write(char cbuf[], int off, int len) 由子類去實現。
圖 3. Writer 相關類層次結構(檢視大圖)
{kind=link}

讀字元的操作介面也有類似的類結構,如下圖所示:
圖 4.Reader 類層次結構(檢視大圖)
{kind=link}

讀字元的操作介面中也是 int read(char cbuf[], int off, int len),返回讀到的 n 個位元組數,不管是 Writer 還是 Reader 類它們都只定義了讀取或寫入的資料字元的方式,也就是怎麼寫或讀,但是並沒有規定資料要寫到哪去,寫到哪去就是我們後面要討論的基於磁碟和網路的工作機制。
位元組與字元的轉化介面
另外資料持久化或網路傳輸都是以位元組進行的,所以必須要有字元到位元組或位元組到字元的轉化。字元到位元組需要轉化,其中讀的轉化過程如下圖所示:
圖 5. 字元解碼相關類結構

InputStreamReader 類是位元組到字元的轉化橋樑,InputStream 到 Reader 的過程要指定編碼字符集,否則將採用作業系統預設字符集,很可能會出現亂碼問題。StreamDecoder 正是完成位元組到字元的解碼的實現類。也就是當你用如下方式讀取一個檔案時:
清單 1.讀取檔案
|
1 2 3 4 5 6 7 8 9 |
|
FileReader 類就是按照上面的工作方式讀取檔案的,FileReader 是繼承了 InputStreamReader 類,實際上是讀取檔案流,然後通過 StreamDecoder 解碼成 char,只不過這裡的解碼字符集是預設字符集。
寫入也是類似的過程如下圖所示:
圖 6. 字元編碼相關類結構

通過 OutputStreamWriter 類完成,字元到位元組的編碼過程,由 StreamEncoder 完成編碼過程。
磁碟 I/O 工作機制
前面介紹了基本的 Java I/O 的操作介面,這些介面主要定義瞭如何操作資料,以及介紹了操作兩種資料結構:位元組和字元的方式。還有一個關鍵問題就是資料寫到何處,其中一個主要方式就是將資料持久化到物理磁碟,下面將介紹如何將資料持久化到物理磁碟的過程。
我們知道資料在磁碟的唯一最小描述就是檔案,也就是說上層應用程式只能通過檔案來操作磁碟上的資料,檔案也是作業系統和磁碟驅動器互動的一個最小單元。值得注意的是 Java 中通常的 File 並不代表一個真實存在的檔案物件,當你通過指定一個路徑描述符時,它就會返回一個代表這個路徑相關聯的一個虛擬物件,這個可能是一個真實存在的檔案或者是一個包含多個檔案的目錄。為何要這樣設計?因為大部分情況下,我們並不關心這個檔案是否真的存在,而是關心這個檔案到底如何操作。例如我們手機裡通常存了幾百個朋友的電話號碼,但是我們通常關心的是我有沒有這個朋友的電話號碼,或者這個電話號碼是什麼,但是這個電話號碼到底能不能打通,我們並不是時時刻刻都去檢查,而只有在真正要給他打電話時才會看這個電話能不能用。也就是使用這個電話記錄要比打這個電話的次數多很多。
何時真正會要檢查一個檔案存不存?就是在真正要讀取這個檔案時,例如 FileInputStream 類都是操作一個檔案的介面,注意到在建立一個 FileInputStream 物件時,會建立一個 FileDescriptor 物件,其實這個物件就是真正代表一個存在的檔案物件的描述,當我們在操作一個檔案物件時可以通過 getFD() 方法獲取真正操作的與底層作業系統關聯的檔案描述。例如可以呼叫 FileDescriptor.sync() 方法將作業系統快取中的資料強制重新整理到物理磁碟中。
下面以清單 1 的程式為例,介紹下如何從磁碟讀取一段文字字元。如下圖所示:
圖 7. 從磁碟讀取檔案

當傳入一個檔案路徑,將會根據這個路徑建立一個 File 物件來標識這個檔案,然後將會根據這個 File 物件建立真正讀取檔案的操作物件,這時將會真正建立一個關聯真實存在的磁碟檔案的檔案描述符 FileDescriptor,通過這個物件可以直接控制這個磁碟檔案。由於我們需要讀取的是字元格式,所以需要 StreamDecoder 類將 byte 解碼為 char 格式,至於如何從磁碟驅動器上讀取一段資料,由作業系統幫我們完成。至於作業系統是如何將資料持久化到磁碟以及如何建立資料結構需要根據當前作業系統使用何種檔案系統來回答,至於檔案系統的相關細節可以參考另外的文章。
Java Socket 的工作機制
Socket 這個概念沒有對應到一個具體的實體,它是描述計算機之間完成相互通訊一種抽象功能。打個比方,可以把 Socket 比作為兩個城市之間的交通工具,有了它,就可以在城市之間來回穿梭了。交通工具有多種,每種交通工具也有相應的交通規則。Socket 也一樣,也有多種。大部分情況下我們使用的都是基於 TCP/IP 的流套接字,它是一種穩定的通訊協議。
下圖是典型的基於 Socket 的通訊的場景:
圖 8.Socket 通訊示例

主機 A 的應用程式要能和主機 B 的應用程式通訊,必須通過 Socket 建立連線,而建立 Socket 連線必須需要底層 TCP/IP 協議來建立 TCP 連線。建立 TCP 連線需要底層 IP 協議來定址網路中的主機。我們知道網路層使用的 IP 協議可以幫助我們根據 IP 地址來找到目標主機,但是一臺主機上可能執行著多個應用程式,如何才能與指定的應用程式通訊就要通過 TCP 或 UPD 的地址也就是埠號來指定。這樣就可以通過一個 Socket 例項唯一代表一個主機上的一個應用程式的通訊鏈路了。
建立通訊鏈路
當客戶端要與服務端通訊,客戶端首先要建立一個 Socket 例項,作業系統將為這個 Socket 例項分配一個沒有被使用的本地埠號,並建立一個包含本地和遠端地址和埠號的套接字資料結構,這個資料結構將一直儲存在系統中直到這個連線關閉。在建立 Socket 例項的建構函式正確返回之前,將要進行 TCP 的三次握手協議,TCP 握手協議完成後,Socket 例項物件將建立完成,否則將丟擲 IOException 錯誤。
與之對應的服務端將建立一個 ServerSocket 例項,ServerSocket 建立比較簡單隻要指定的埠號沒有被佔用,一般例項建立都會成功,同時作業系統也會為 ServerSocket 例項建立一個底層資料結構,這個資料結構中包含指定監聽的埠號和包含監聽地址的萬用字元,通常情況下都是“*”即監聽所有地址。之後當呼叫 accept() 方法時,將進入阻塞狀態,等待客戶端的請求。當一個新的請求到來時,將為這個連線建立一個新的套接字資料結構,該套接字資料的資訊包含的地址和埠資訊正是請求源地址和埠。這個新建立的資料結構將會關聯到 ServerSocket 例項的一個未完成的連線資料結構列表中,注意這時服務端與之對應的 Socket 例項並沒有完成建立,而要等到與客戶端的三次握手完成後,這個服務端的 Socket 例項才會返回,並將這個 Socket 例項對應的資料結構從未完成列表中移到已完成列表中。所以 ServerSocket 所關聯的列表中每個資料結構,都代表與一個客戶端的建立的 TCP 連線。
資料傳輸
傳輸資料是我們建立連線的主要目的,如何通過 Socket 傳輸資料,下面將詳細介紹。
當連線已經建立成功,服務端和客戶端都會擁有一個 Socket 例項,每個 Socket 例項都有一個 InputStream 和 OutputStream,正是通過這兩個物件來交換資料。同時我們也知道網路 I/O 都是以位元組流傳輸的。當 Socket 物件建立時,作業系統將會為 InputStream 和 OutputStream 分別分配一定大小的緩衝區,資料的寫入和讀取都是通過這個快取區完成的。寫入端將資料寫到 OutputStream 對應的 SendQ 佇列中,當佇列填滿時,資料將被髮送到另一端 InputStream 的 RecvQ 佇列中,如果這時 RecvQ 已經滿了,那麼 OutputStream 的 write 方法將會阻塞直到 RecvQ 佇列有足夠的空間容納 SendQ 傳送的資料。值得特別注意的是,這個快取區的大小以及寫入端的速度和讀取端的速度非常影響這個連線的資料傳輸效率,由於可能會發生阻塞,所以網路 I/O 與磁碟 I/O 在資料的寫入和讀取還要有一個協調的過程,如果兩邊同時傳送資料時可能會產生死鎖,在後面 NIO 部分將介紹避免這種情況。
NIO 的工作方式
BIO 帶來的挑戰
BIO 即阻塞 I/O,不管是磁碟 I/O 還是網路 I/O,資料在寫入 OutputStream 或者從 InputStream 讀取時都有可能會阻塞。一旦有執行緒阻塞將會失去 CPU 的使用權,這在當前的大規模訪問量和有效能要求情況下是不能接受的。雖然當前的網路 I/O 有一些解決辦法,如一個客戶端一個處理執行緒,出現阻塞時只是一個執行緒阻塞而不會影響其它執行緒工作,還有為了減少系統執行緒的開銷,採用執行緒池的辦法來減少執行緒建立和回收的成本,但是有一些使用場景仍然是無法解決的。如當前一些需要大量 HTTP 長連線的情況,像淘寶現在使用的 Web 旺旺專案,服務端需要同時保持幾百萬的 HTTP 連線,但是並不是每時每刻這些連線都在傳輸資料,這種情況下不可能同時建立這麼多執行緒來保持連線。即使執行緒的數量不是問題,仍然有一些問題還是無法避免的。如這種情況,我們想給某些客戶端更高的服務優先順序,很難通過設計執行緒的優先順序來完成,另外一種情況是,我們需要讓每個客戶端的請求在服務端可能需要訪問一些競爭資源,由於這些客戶端是在不同執行緒中,因此需要同步,而往往要實現這些同步操作要遠遠比用單執行緒複雜很多。以上這些情況都說明,我們需要另外一種新的 I/O 操作方式。
NIO 的工作機制
我們先看一下 NIO 涉及到的關聯類圖,如下:
圖 9.NIO 相關類圖

上圖中有兩個關鍵類:Channel 和 Selector,它們是 NIO 中兩個核心概念。我們還用前面的城市交通工具來繼續比喻 NIO 的工作方式,這裡的 Channel 要比 Socket 更加具體,它可以比作為某種具體的交通工具,如汽車或是高鐵等,而 Selector 可以比作為一個車站的車輛執行排程系統,它將負責監控每輛車的當前執行狀態:是已經出戰還是在路上等等,也就是它可以輪詢每個 Channel 的狀態。這裡還有一個 Buffer 類,它也比 Stream 更加具體化,我們可以將它比作為車上的座位,Channel 是汽車的話就是汽車上的座位,高鐵上就是高鐵上的座位,它始終是一個具體的概念,與 Stream 不同。Stream 只能代表是一個座位,至於是什麼座位由你自己去想象,也就是你在去上車之前並不知道,這個車上是否還有沒有座位了,也不知道上的是什麼車,因為你並不能選擇,這些資訊都已經被封裝在了運輸工具(Socket)裡面了,對你是透明的。NIO 引入了 Channel、Buffer 和 Selector 就是想把這些資訊具體化,讓程式設計師有機會控制它們,如:當我們呼叫 write() 往 SendQ 寫資料時,當一次寫的資料超過 SendQ 長度是需要按照 SendQ 的長度進行分割,這個過程中需要有將使用者空間資料和核心地址空間進行切換,而這個切換不是你可以控制的。而在 Buffer 中我們可以控制 Buffer 的 capacity,並且是否擴容以及如何擴容都可以控制。
理解了這些概念後我們看一下,實際上它們是如何工作的,下面是典型的一段 NIO 程式碼:
清單 2. NIO 工作程式碼示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
呼叫 Selector 的靜態工廠建立一個選擇器,建立一個服務端的 Channel 繫結到一個 Socket 物件,並把這個通訊通道註冊到選擇器上,把這個通訊通道設定為非阻塞模式。然後就可以呼叫 Selector 的 selectedKeys 方法來檢查已經註冊在這個選擇器上的所有通訊通道是否有需要的事件發生,如果有某個事件發生時,將會返回所有的 SelectionKey,通過這個物件 Channel 方法就可以取得這個通訊通道物件從而可以讀取通訊的資料,而這裡讀取的資料是 Buffer,這個 Buffer 是我們可以控制的緩衝器。
在上面的這段程式中,是將 Server 端的監聽連線請求的事件和處理請求的事件放在一個執行緒中,但是在實際應用中,我們通常會把它們放在兩個執行緒中,一個執行緒專門負責監聽客戶端的連線請求,而且是阻塞方式執行的;另外一個執行緒專門來處理請求,這個專門處理請求的執行緒才會真正採用 NIO 的方式,像 Web 伺服器 Tomcat 和 Jetty 都是這個處理方式,關於 Tomcat 和 Jetty 的 NIO 處理方式可以參考文章《 Jetty 的工作原理和與 Tomcat 的比較》。
下圖是描述了基於 NIO 工作方式的 Socket 請求的處理過程:
圖 10. 基於 NIO 的 Socket 請求的處理過程

上圖中的 Selector 可以同時監聽一組通訊通道(Channel)上的 I/O 狀態,前提是這個 Selector 要已經註冊到這些通訊通道中。選擇器 Selector 可以呼叫 select() 方法檢查已經註冊的通訊通道上的是否有 I/O 已經準備好,如果沒有至少一個通道 I/O 狀態有變化,那麼 select 方法會阻塞等待或在超時時間後會返回 0。上圖中如果有多個通道有資料,那麼將會將這些資料分配到對應的資料 Buffer 中。所以關鍵的地方是有一個執行緒來處理所有連線的資料互動,每個連線的資料互動都不是阻塞方式,所以可以同時處理大量的連線請求。
Buffer 的工作方式
上面介紹了 Selector 將檢測到有通訊通道 I/O 有資料傳輸時,通過 selelct() 取得 SocketChannel,將資料讀取或寫入 Buffer 緩衝區。下面討論一下 Buffer 如何接受和寫出資料?
Buffer 可以簡單的理解為一組基本資料型別的元素列表,它通過幾個變數來儲存這個資料的當前位置狀態,也就是有四個索引。如下表所示:
表 1.Buffer 中的引數項
| 索引 | 說明 |
|---|---|
| capacity | 緩衝區陣列的總長度 |
| position | 下一個要操作的資料元素的位置 |
| limit | 緩衝區陣列中不可操作的下一個元素的位置,limit<=capacity |
| mark | 用於記錄當前 position 的前一個位置或者預設是 0 |
在實際操作資料時它們有如下關係圖:

我們通過 ByteBuffer.allocate(11) 方法建立一個 11 個 byte 的陣列緩衝區,初始狀態如上圖所示,position 的位置為 0,capacity 和 limit 預設都是陣列長度。當我們寫入 5 個位元組時位置變化如下圖所示:

這時我們需要將緩衝區的 5 個位元組資料寫入 Channel 通訊通道,所以我們需要呼叫 byteBuffer.flip() 方法,陣列的狀態又發生如下變化:

這時底層作業系統就可以從緩衝區中正確讀取這 5 個位元組資料傳送出去了。在下一次寫資料之前我們在調一下 clear() 方法。緩衝區的索引狀態又回到初始位置。
這裡還要說明一下 mark,當我們呼叫 mark() 時,它將記錄當前 position 的前一個位置,當我們呼叫 reset 時,position 將恢復 mark 記錄下來的值。
還有一點需要說明,通過 Channel 獲取的 I/O 資料首先要經過作業系統的 Socket 緩衝區再將資料複製到 Buffer 中,這個的作業系統緩衝區就是底層的 TCP 協議關聯的 RecvQ 或者 SendQ 佇列,從作業系統緩衝區到使用者緩衝區複製資料比較耗效能,Buffer 提供了另外一種直接操作作業系統緩衝區的的方式即 ByteBuffer.allocateDirector(size),這個方法返回的 byteBuffer 就是與底層儲存空間關聯的緩衝區,它的操作方式與 linux2.4 核心的 sendfile 操作方式類似。
I/O 調優
下面就磁碟 I/O 和網路 I/O 的一些常用的優化技巧進行總結如下:
磁碟 I/O 優化
效能檢測
我們的應用程式通常都需要訪問磁碟讀取資料,而磁碟 I/O 通常都很耗時,我們要判斷 I/O 是否是一個瓶頸,我們有一些引數指標可以參考:
如我們可以壓力測試應用程式看系統的 I/O wait 指標是否正常,例如測試機器有 4 個 CPU,那麼理想的 I/O wait 引數不應該超過 25%,如果超過 25% 的話,I/O 很可能成為應用程式的效能瓶頸。Linux 作業系統下可以通過 iostat 命令檢視。
通常我們在判斷 I/O 效能時還會看另外一個引數就是 IOPS,我們應用程式需要最低的 IOPS 是多少,而我們的磁碟的 IOPS 能不能達到我們的要求。每個磁碟的 IOPS 通常是在一個範圍內,這和儲存在磁碟的資料塊的大小和訪問方式也有關。但是主要是由磁碟的轉速決定的,磁碟的轉速越高磁碟的 IOPS 也越高。
現在為了提高磁碟 I/O 的效能,通常採用一種叫 RAID 的技術,就是將不同的磁碟組合起來來提高 I/O 效能,目前有多種 RAID 技術,每種 RAID 技術對 I/O 效能提升會有不同,可以用一個 RAID 因子來代表,磁碟的讀寫吞吐量可以通過 iostat 命令來獲取,於是我們可以計算出一個理論的 IOPS 值,計算公式如下所以:
( 磁碟數 * 每塊磁碟的 IOPS)/( 磁碟讀的吞吐量 +RAID 因子 * 磁碟寫的吞吐量 )=IOPS
提升 I/O 效能
提升磁碟 I/O 效能通常的方法有:
- 增加快取,減少磁碟訪問次數
- 優化磁碟的管理系統,設計最優的磁碟訪問策略,以及磁碟的定址策略,這裡是在底層作業系統層面考慮的。
- 設計合理的磁碟儲存資料塊,以及訪問這些資料塊的策略,這裡是在應用層面考慮的。如我們可以給存放的資料設計索引,通過定址索引來加快和減少磁碟的訪問,還有可以採用非同步和非阻塞的方式加快磁碟的訪問效率。
- 應用合理的 RAID 策略提升磁碟 IO,每種 RAID 的區別我們可以用下表所示:
表 2.RAID 策略
| 磁碟陣列 | 說明 |
|---|---|
| RAID 0 | 資料被平均寫到多個磁碟陣列中,寫資料和讀資料都是並行的,所以磁碟的 IOPS 可以提高一倍。 |
| RAID 1 | RAID 1 的主要作用是能夠提高資料的安全性,它將一份資料分別複製到多個磁碟陣列中。並不能提升 IOPS 但是相同的資料有多個備份。通常用於對資料安全性較高的場合中。 |
| RAID 5 | 這中設計方式是前兩種的折中方式,它將資料平均寫到所有磁碟陣列總數減一的磁碟中,往另外一個磁碟中寫入這份資料的奇偶校驗資訊。如果其中一個磁碟損壞,可以通過其它磁碟的資料和這個資料的奇偶校驗資訊來恢復這份資料。 |
| RAID 0+1 | 如名字一樣,就是根據資料的備份情況進行分組,一份資料同時寫到多個備份磁碟分組中,同時多個分組也會並行讀寫。 |
網路 I/O 優化
網路 I/O 優化通常有一些基本處理原則:
- 一個是減少網路互動的次數:要減少網路互動的次數通常我們在需要網路互動的兩端會設定快取,比如 Oracle 的 JDBC 驅動程式,就提供了對查詢的 SQL 結果的快取,在客戶端和資料庫端都有,可以有效的減少對資料庫的訪問。關於 Oracle JDBC 的記憶體管理可以參考《 Oracle JDBC 記憶體管理》。除了設定快取還有一個辦法是,合併訪問請求:如在查詢資料庫時,我們要查 10 個 id,我可以每次查一個 id,也可以一次查 10 個 id。再比如在訪問一個頁面時通過會有多個 js 或 css 的檔案,我們可以將多個 js 檔案合併在一個 HTTP 連結中,每個檔案用逗號隔開,然後傳送到後端 Web 伺服器根據這個 URL 連結,再拆分出各個檔案,然後打包再一併發回給前端瀏覽器。這些都是常用的減少網路 I/O 的辦法。
- 減少網路傳輸資料量的大小:減少網路資料量的辦法通常是將資料壓縮後再傳輸,如 HTTP 請求中,通常 Web 伺服器將請求的 Web 頁面 gzip 壓縮後在傳輸給瀏覽器。還有就是通過設計簡單的協議,儘量通過讀取協議頭來獲取有用的價值資訊。比如在代理程式設計時,有 4 層代理和 7 層代理都是來儘量避免要讀取整個通訊資料來取得需要的資訊。
- 儘量減少編碼:通常在網路 I/O 中資料傳輸都是以位元組形式的,也就是通常要序列化。但是我們傳送要傳輸的資料都是字元形式的,從字元到位元組必須編碼。但是這個編碼過程是比較耗時的,所以在要經過網路 I/O 傳輸時,儘量直接以位元組形式傳送。也就是儘量提前將字元轉化為位元組,或者減少字元到位元組的轉化過程。
- 根據應用場景設計合適的互動方式:所謂的互動場景主要包括同步與非同步阻塞與非阻塞方式,下面將詳細介紹。
同步與非同步
所謂同步就是一個任務的完成需要依賴另外一個任務時,只有等待被依賴的任務完成後,依賴的任務才能算完成,這是一種可靠的任務序列。要麼成功都成功,失敗都失敗,兩個任務的狀態可以保持一致。而非同步是不需要等待被依賴的任務完成,只是通知被依賴的任務要完成什麼工作,依賴的任務也立即執行,只要自己完成了整個任務就算完成了。至於被依賴的任務最終是否真正完成,依賴它的任務無法確定,所以它是不可靠的任務序列。我們可以用打電話和發簡訊來很好的比喻同步與非同步操作。
在設計到 IO 處理時通常都會遇到一個是同步還是非同步的處理方式的選擇問題。因為同步與非同步的 I/O 處理方式對呼叫者的影響很大,在資料庫產品中都會遇到這個問題。因為 I/O 操作通常是一個非常耗時的操作,在一個任務序列中 I/O 通常都是效能瓶頸。但是同步與非同步的處理方式對程式的可靠性影響非常大,同步能夠保證程式的可靠性,而非同步可以提升程式的效能,必須在可靠性和效能之間做個平衡,沒有完美的解決辦法。
阻塞與非阻塞
阻塞與非阻塞主要是從 CPU 的消耗上來說的,阻塞就是 CPU 停下來等待一個慢的操作完成 CPU 才接著完成其它的事。非阻塞就是在這個慢的操作在執行時 CPU 去幹其它別的事,等這個慢的操作完成時,CPU 再接著完成後續的操作。雖然表面上看非阻塞的方式可以明顯的提高 CPU 的利用率,但是也帶了另外一種後果就是系統的執行緒切換增加。增加的 CPU 使用時間能不能補償系統的切換成本需要好好評估。
兩種的方式的組合
組合的方式可以由四種,分別是:同步阻塞、同步非阻塞、非同步阻塞、非同步非阻塞,這四種方式都對 I/O 效能有影響。下面給出分析,並有一些常用的設計用例參考。
表 3. 四種組合方式
| 組合方式 | 效能分析 |
|---|---|
| 同步阻塞 | 最常用的一種用法,使用也是最簡單的,但是 I/O 效能一般很差,CPU 大部分在空閒狀態。 |
| 同步非阻塞 | 提升 I/O 效能的常用手段,就是將 I/O 的阻塞改成非阻塞方式,尤其在網路 I/O 是長連線,同時傳輸資料也不是很多的情況下,提升效能非常有效。 這種方式通常能提升 I/O 效能,但是會增加 CPU 消耗,要考慮增加的 I/O 效能能不能補償 CPU 的消耗,也就是系統的瓶頸是在 I/O 還是在 CPU 上。 |
| 非同步阻塞 | 這種方式在分散式資料庫中經常用到,例如在網一個分散式資料庫中寫一條記錄,通常會有一份是同步阻塞的記錄,而還有兩至三份是備份記錄會寫到其它機器上,這些備份記錄通常都是採用非同步阻塞的方式寫 I/O。 非同步阻塞對網路 I/O 能夠提升效率,尤其像上面這種同時寫多份相同資料的情況。 |
| 非同步非阻塞 | 這種組合方式用起來比較複雜,只有在一些非常複雜的分散式情況下使用,像叢集之間的訊息同步機制一般用這種 I/O 組合方式。如 Cassandra 的 Gossip 通訊機制就是採用非同步非阻塞的方式。 它適合同時要傳多份相同的資料到叢集中不同的機器,同時資料的傳輸量雖然不大,但是卻非常頻繁。這種網路 I/O 用這個方式效能能達到最高。 |
雖然非同步和非阻塞能夠提升 I/O 的效能,但是也會帶來一些額外的效能成本,例如會增加執行緒數量從而增加 CPU 的消耗,同時也會導致程式設計的複雜度上升。如果設計的不合理的話反而會導致效能下降。在實際設計時要根據應用場景綜合評估一下。
下面舉一些非同步和阻塞的操作例項:
在 Cassandra 中要查詢資料通常會往多個數據節點發送查詢命令,但是要檢查每個節點返回資料的完整性,所以需要一個非同步查詢同步結果的應用場景,部分程式碼如下:
清單 3.非同步查詢同步結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
|
總結
本文闡述的內容較多,從 Java 基本 I/O 類庫結構開始說起,主要介紹了磁碟 I/O 和網路 I/O 的基本工作方式,最後介紹了關於 I/O 調優的一些方法。
相關主題
- 檢視文章 《深入分析Java中文編碼問題》(developerWorks,2011 年 7 月):詳細介紹 Java 中編碼問題出現的根本原因,你將瞭解到:Java 中經常遇到的幾種編碼格式的區別;Java 中經常需要編碼的場景;出現中文問題的原因分析;在開發 Java web 程式時可能會存在編碼的幾個地方,一個 HTTP 請求怎麼控制編碼格式?如何避免出現中文問題?
- 《Oracle JDBC記憶體管理》:這裡詳細分析 Oracle JDBC 記憶體管理的處理方式。
- 《Jetty 的工作原理和與 Tomcat 的比較》:這裡介紹了 Jetty 是如何使用 NIO 技術處理 HTTP 連線請求的,以及與 Tomcat 處理有何不同之處。
- Java I/O Performance:sun.com 上的文章,介紹了一些 I/O 調優的基本方法。
- Java NIO.2:這裡介紹了 JDK7 裡面的新的 I/O 技術,可以參考學習下。
- Understanding Disk I/O:這裡介紹了一點關於磁碟 I/O 一些檢測和調優方法,本文也引用了一些知識點。