
(2.1.27.3)Java併發程式設計:CAS操作
在前文中我們描述過,物理機計算機的資料快取不一致的時候,我們一般採用兩種方式來處理。一,通過匯流排加鎖的形式,二,通過快取一致性協議來操作。
體現快取一致性的正是CAS(Compare-and-Swap)操作,CAS操作在整個Java併發框架中起著非常重要的作用
- 對於物理計算機中的快取鎖,在Java中是使用CAS操作來實現的。
- CAS操作的實質就是一個 [比較+替換] 的賦值過程, 通過(記憶體地址V,舊的預期值A,即將要更新的目標值B)的方式保證同步的一致性
- CAS操作的實質在於物理裝置開放了一些指令,對於操作和衝突檢測這兩個步驟原子性支援
- CAS操作中會出現三個問題,ABA問題。迴圈時間開銷太大,只能保證一個共享變數的原子操作。
一、物理計算機的快取鎖
在前文中我們提及,在物理機計算機中當處理器中資料快取不一致的時候,一般採用匯流排鎖。匯流排鎖實質是把CPU和記憶體之前的通訊鎖住了,那麼在鎖定期間,其他的處理器是不能操作 “主記憶體中其他記憶體地址的資料”。所以匯流排鎖的開銷比較大
隨著技術的進步,現在計算機已經採用了快取鎖來替代匯流排鎖來進行效能的優化。那麼什麼是快取鎖呢?
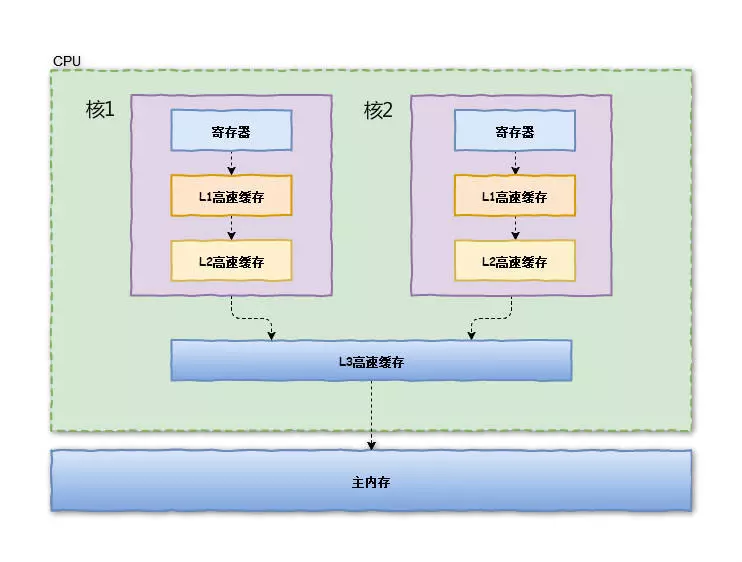
我們都知道在CPU資料處理中,頻繁使用的記憶體會快取在處理器的L1、L2和L3快取記憶體裡,那麼資料的操作都在處理器內部快取中進行,並不需要宣告匯流排鎖
那麼,在目前的處理器中可以使用“快取鎖定”的方式來處理資料不一致的情況,這裡所謂的“快取鎖定”是指:
1.記憶體區域如果被快取在處理器的快取中,並且在操作期間被鎖定,那麼當它執行鎖操作會寫到記憶體時,處理器並不會像鎖匯流排的那樣宣告LOCK#訊號,而是修改其對應的記憶體地址 2. 最重要的是其 允許快取一致性來保證資料的一致性
快取一致性核心思想:在多處理器下,為了保證各個處理器的快取是一致的,就會實現快取一致性協議。
- 每個處理通過嗅探在總線上傳播的資料來檢查自己的快取的值是不是過期了
- 當處理器發現自己快取的資料對應的記憶體地址被修改,就會將當前處理器快取的資料處理為無效。
- 當處理器對這個資料進行修改的操作的時候,會重新從系統記憶體中把資料讀到處理器快取中。
1.1 快取鎖與CAS(Compare-and-Swap)的關係
為了實現快取鎖,在物理計算機中,Intel處理器提供了很多Lock字首的指令(注意是帶Lock字首,字首,字首),被這些指令操作的記憶體區域就會加鎖,導致其他處理器不能同時訪問它。例如,位測試和修改指令:BTS、BTR、BTC;交換指令XADD、CMPXCHG,以及其他一些運算元和邏輯指令(如ADD、OR)等。
不同的處理器實現快取鎖的指令不同,在sparc-TSO使用casa指令,而在ARM和PowerPc架構下,則需要使用一對ldrex/strex指令。
Java作為一個可以跨平臺執行的語言,它勢別是將這些不同的指令進行了封裝以遮蔽使用者對於底層差異性的感知。在Java語言中,涉及到快取鎖的操作就是CAS操作,該操作內部會最終呼叫不同處理器下的快取鎖Lock指令
二、Java世界的CAS操作(Compare-and-Swap)
CAS是Compare-and-swap(比較與替換)的簡寫,是一種有名的無鎖演算法.
CAS指令需要三個運算元,分別是
- 記憶體地址(在Java記憶體模型中可以簡單理解為主記憶體中變數的記憶體地址)
- 舊值(在Java記憶體模型中,可以理解工作記憶體中快取的主記憶體的變數的值)
- 新值
CAS操作執行時,當且僅當主記憶體對應的值等於舊值時,處理器用新值去更新舊值,否則它就不執行更新。但是無論是否更新了主記憶體中的值,都會返回舊值,上述的處理過程是一個原子操作。
CAS操作並不是程式碼級別的互斥同步,而是直接藉助物理裝置實現的操作和衝突檢測這兩個步驟。在JDK 1.5之後,Java程式中才可以使用CAS操作,該操作由sun.misc.Unsafe類裡面的compareAndSwapInt()和compareAndSwapLong()等幾個方法包裝提供,虛擬機器在內部對這些方法做了特殊處理,即時編譯出來的結果就是一條平臺相關的處理器CAS指令,沒有方法呼叫的過程,或者可以認為是無條件內聯進去了
對於概念類的東西,大家理解起來比較困難,這裡簡單舉個例子。 針對一個共享變數Int,我們使用20個執行緒對它進行a++自增操作10次
public class AtomicTest{
//public static volatile int race=0;//1
public static AtomicInteger race=new AtomicInteger(0);//2
public static void increase(){
race.incrementAndGet();
}
//public static synchronized void increase(){
// race++;
//}
private static final int THREADS_COUNT=20;
public static void main(String[]args)throws Exception{
Thread[]threads=new Thread[THREADS_COUNT];
for(int i=0;i<THREADS_COUNT;i++){
threads[i]=new Thread(new Runnable(){
@Override
public void run(){
for(int i=0;i<10000;i++){
increase();
}
}
});
threads[i].start();
}
//所有執行緒都執行完畢後,列印結果
while(Thread.activeCount()>1) Thread.yield();//yield在於阻塞當前執行緒
System.out.println(race);
}
}
- 如果是1處使用的程式碼volatile,則結果並不是200. 這是由於 volatile只能保證可見性並不能保證 a++自增操作的原子性,多執行緒在讀寫時可能出現覆蓋
- 把“race++”操作或increase()方法用synchronized同步塊包裹起來當然是一個辦法,使用synchronized修飾後,increase方法變成了一個原子操作,因此是肯定能得到正確的結果。但這裡我們暫時不關注這方面
- 使用 AtomicInteger 代替int後,程式輸出了正確的結果 200,一切都要歸功於incrementAndGet()方法的原子性。
AtomicInteger保證了執行緒安全的奧祕就在於 CAS操作,我們來看incrementAndGet():
public final int incrementAndGet(){
for(;;){
int current=get();
int next=current+1;
if(compareAndSet(current,next))
return next;
}
}
incrementAndGet()方法在一個無限迴圈中(也就是CAS的自旋),不斷嘗試將一個比當前值大1的新值賦給自己。如果失敗了,那說明在執行“獲取-設定”操作的時候值已經有了修改,於是再次迴圈進行下一次操作,直到設定成功為止。
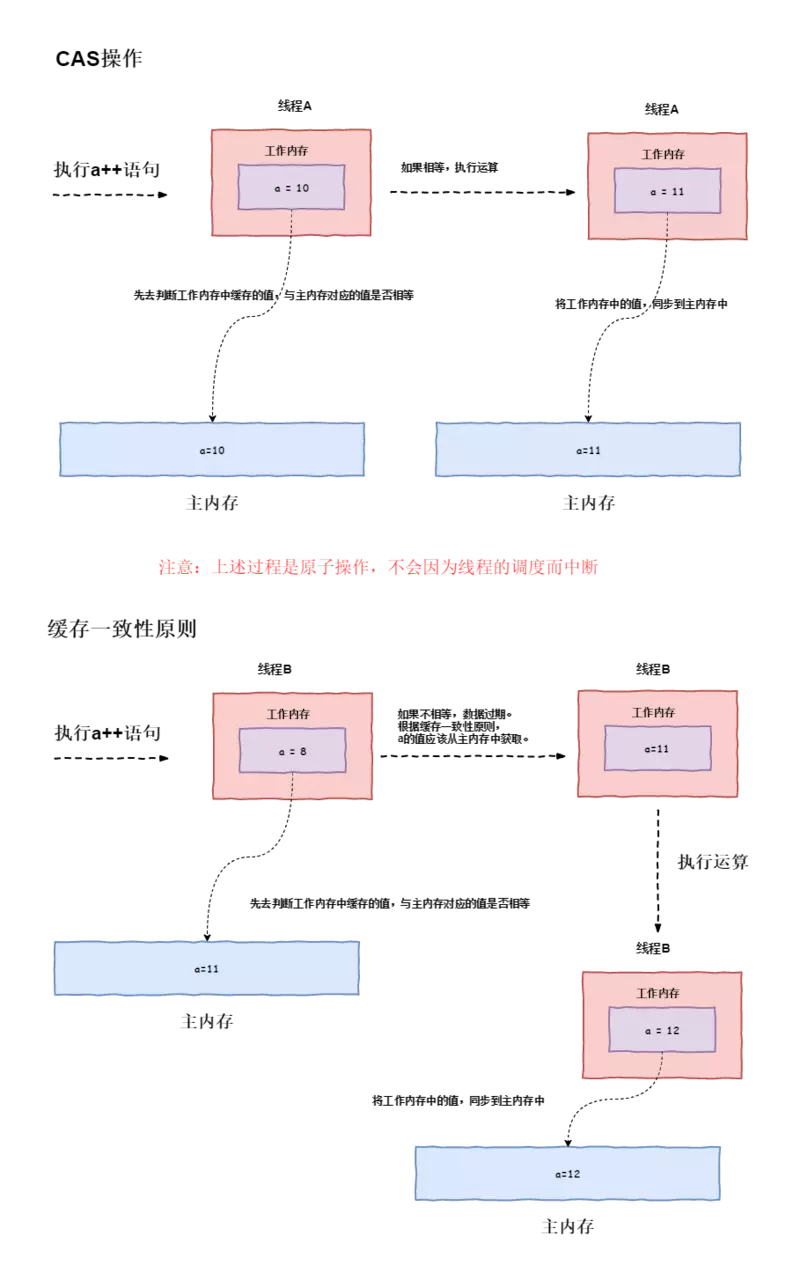
在上圖中,分別有兩條執行緒A與B,假設執行緒A優先與執行緒B執行AtomicInteger a++操作,則
- 對於A執行緒:執行緒A工作記憶體快取a的值為10,主記憶體中的a的值也為10,這個時候如果進行CAS操作 cas(10,11)
- 會將工作記憶體與主記憶體中的a的值進行對比
- 發現是相等的,則執行a++操作運算
- 將執行結果也就是11同步到主記憶體中,這個時候主記憶體中的值為11
- 對於B執行緒:工作記憶體中快取的a的值為8,主記憶體a的值為11,這個時候如果進行CAS操作 cas(8,9)
- 會將工作記憶體與主記憶體中的a的值進行對比
- 發現不相等,據快取一致性原則。會重新去主記憶體讀取a的值(11),此時執行緒B中工作記憶體中快取的a的值為11,
- 執行a++運算後,這個時候如果進行CAS操作 cas(10,12)
- 將執行結果也就是12同步到主記憶體中,這個時候主記憶體中的值為12
需要特別注意的是: CAS操作其實就是一次賦值過程,只不過這個賦值過程前需要校驗正確性,不正確則直接關閉。上述示例中的,再次讀取記憶體中的值並再次執行運算,其實已經不屬於CAS操作的範疇,它的實現可以參看後邊的AtomicXX
三、CAS在Java中的實現
我們繼續上文的AtomicInteger#incrementAndGet(),其中的compareAndSet() 方法的實現很簡單,只有一行程式碼。這裡涉及到兩個重要的物件,一個是 unsafe ,一個是 valueOffset。
private static final sun.misc.Unsafe unsafe = sun.misc.Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (ReflectiveOperationException e) {
throw new Error(e);
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, VALUE, expect, update);
}
- 什麼是unsafe呢?Java語言不像C,C++那樣可以直接訪問底層作業系統,但是JVM為我們提供了一個後門,這個後門就是unsafe。unsafe為我們提供了硬體級別的原子操作。
- 至於valueOffset物件,是通過unsafe.objectFieldOffset方法得到,所代表的是AtomicInteger物件value成員變數在記憶體中的偏移量。我們可以簡單地把valueOffset理解為value變數的記憶體地址。
在java中,我們主要分析Unsafe類,因為所有的CAS操作都是它來實現的,在Unsafe類中這些方法也都是native方法
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
由於Unsafe類不是提供給使用者程式呼叫的類(Unsafe.getUnsafe()的程式碼中限制了只有啟動類載入器(Bootstrap ClassLoader)載入的Class才能訪問它)。因此,如果不採用反射手段,我們只能通過其他的Java API來間接使用它,如J.U.C包裡面的整數原子類,其中的compareAndSet()和getAndIncrement()等方法都使用了Unsafe類的CAS操作。
這裡我們就使用compareAndSwapInt來講解,具體程式碼如下:
private static final jdk.internal.misc.Unsafe theInternalUnsafe = jdk.internal.misc.Unsafe.getUnsafe();
/**
* 第一個引數object是當前物件
* 第二個引數offest表示該變數在記憶體中的偏移地址(CAS底層是根據記憶體偏移位置來獲取的)
* 第三個引數expected為舊值
* 第四個引數x為新值。
*/
public final boolean compareAndSwapInt(Object o, long offset,
int expected,
int x) {
return theInternalUnsafe.compareAndSetInt(o, offset, expected, x);
}
//繼續檢視theInternalUnsafe下的compareAndSetInt()方法。也是一個本地方法。
//這裡具體的本地方法是在hotspot下的unsafe.cpp類具體實現的。
public final native boolean compareAndSetInt(Object o, long offset,
int expected,
int x);
//compareAndSetInt呼叫unsafe.cpp中的JNI方法具體實現如下:
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSetInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)) {
oop p = JNIHandles::resolve(obj);
if (p == NULL) {
volatile jint* addr = (volatile jint*)index_oop_from_field_offset_long(p, offset);
return RawAccess<>::atomic_cmpxchg(x, addr, e) == e;
} else {
assert_field_offset_sane(p, offset);
return HeapAccess<>::atomic_cmpxchg_at(x, p, (ptrdiff_t)offset, e) == e;
}
} UNSAFE_END
unsafe.cpp最終會呼叫atomic.cpp, 而atomic.cpp會根據不同的處理呼叫不同的處理器指令,這裡我們還是以Intel的處理器為例,atomic.cpp最終會呼叫atomic_windows_x86.cpp中的operator()方法。
template<>
template<typename T>
/**
*第一個引數exchange_value為新值
*第二個引數volatile* dest為變數記憶體地址(也就是主記憶體中變數地址)
*第三個引數compare_value為舊值(也就是工作記憶體中快取的變數值)。
*其中在方法中,asm是C++中的關鍵字,主要作用為啟動內聯彙編,同時其能寫在任何C++合法語句之處。它不能單獨出現,必須接彙編指令、一組被大括號包含的指令或一對空括號。
*/
inline T Atomic::PlatformCmpxchg<4>::operator()(T exchange_value,
T volatile* dest,
T compare_value,
atomic_memory_order order) const {
STATIC_ASSERT(4 == sizeof(T));
// alternative for InterlockedCompareExchange
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
lock cmpxchg dword ptr [edx], ecx
}
}
那麼針對於operrator中的彙編語句塊進行分析,要內容分為四個部分(這裡我們就把edx,ecx,eax當做儲存資料的容器):
- mov edx, dest 將變數的記憶體地址賦值到edx中。
- mov ecx, exchange_value 將新值賦值到ecx中。
- mov eax,compare_value 將舊值賦值到eax中。
- lock cmpxchg dword ptr [edx], ecx 如果主記憶體中的值與舊值(也就是工作記憶體中快取的變數值)不同,那麼工作記憶體中的快取的變數值(也就是舊值)就更新為主記憶體中的值。如果相同。那麼主記憶體中的值就更新為最新的值。
- dword彙編指令 dword ptr [edx],簡單來說,就是獲取edx中記憶體地址中的具體的資料值
- cmpxchg彙編指令 格式如下:cmpxchg [第一運算元],[第二個運算元]。cmpxchg彙編指令: 主要操作邏輯是比較eax與第一運算元的值,如果相等,那麼第二運算元的值裝載到第一運算元,如果不相等,那麼第一運算元的值裝載到eax中
- lock彙編指令
- 在Pentium及之前的處理器中,帶有lock字首的指令在執行期間會鎖住匯流排。在新的處理器中,Intel使用快取鎖定來保證指令執行的原子性,快取鎖定將大大降低lock字首指令的執行開銷。
- 禁止該指令與前面和後面的讀寫指令重排序。
- 把寫緩衝區的所有資料重新整理到記憶體中。額外提一句。上面的第2點和第3點所具有的記憶體屏障效果,保證了CAS同時具有volatile讀和volatile寫的記憶體語義