
centos6.0下如何Hadoop環境搭建
準備工作
Hadoop環境搭建:
1.主機名
2.防火牆關閉
3.免密登入
(ssh-keygen
按4個回車後
ssh-copy-id [email protected]虛擬機器主機ip)
4.Jdk(具體安裝步驟可以看上一篇文章)
正式搭建步驟
開啟虛擬機器,進入hadoop目錄下
1、vim hadoop-env.sh
1.1、Line 25: 修改JAVA_HOME=jdk的安裝目錄

2.2、Line 33:修改HADOOP_CONF_DIR=hadoop配置檔案所在的目錄

2、編輯 core-site.xml
core-site.xml 主要配置的是 namenode所在的地址 及hadoop在執行過程中產生的資料存放的臨時目錄
vim core-site.xml
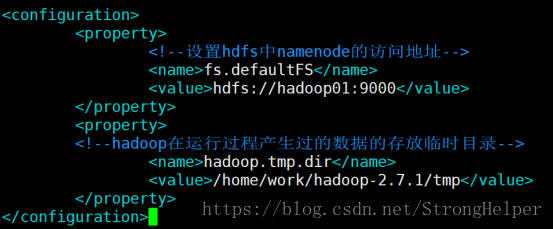
<configuration>
<property>
<!--設定hdfs中namenode的訪問地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!--hadoop在執行過程產生過的資料的存放臨時目錄--> 3、編輯hdfs-site.xml
hdfs-site.xml針對於hadoop中檔案系統配置,主要配置塊的副本數及hdfs中許可權操作
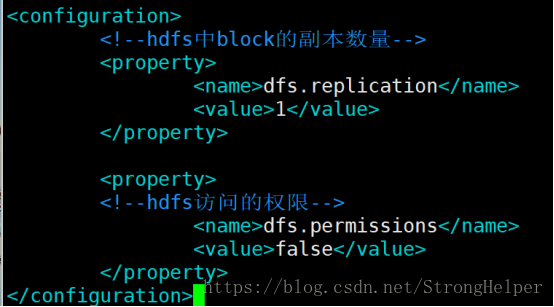
<configuration>
<!--hdfs中block的副本數量--> 4、mapred-site.xml
主要配置 mapreduce運行於yarn資源協調框架中
mapred-site.xml這個在hadoop的配置中沒有直接存在,將mapred-site.xml.template拷貝為mapred-site.xml,然後對mapred-site.xml進行編輯。
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!--指定mapreduce執行時呼叫yarn進行資源協調-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5、編輯yarn-site.xml
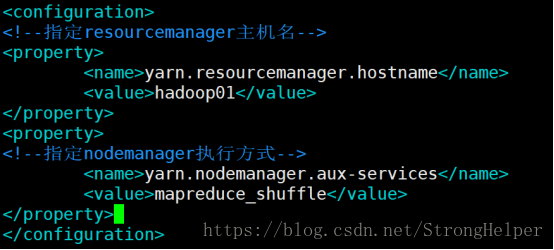
Yarn-site.xml指定資源協調的方式,其中:指定resourcemanager的主機,指定nodemanager的執行方式

<configuration>
<!--指定resourcemanager主機名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--指定nodemanager執行方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>6、編輯slaves
指定真正資料儲存的機器(datanode)

7、配置hadoop環境變數
注意:只要提到linux中系統環境變數,就是對/etc/profile進行編輯。
vim /etc/profile
bin sbin

`
JAVA_HOME=/home/work/jdk1.8.0_65
HADOOP_HOME=/home/work/hadoop-2.7.1
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME PATH HADOOP_HOME
利用:
source /etc/profile 儲存並讓配置立即生效。`
Hadoop格式化操作:
由於配置了hadoop的環境變數,可以任何目錄下執行:
hadoop namenode -format
若沒有配置該環境變數,需要到 hadoop安裝目錄的bin目錄下執行,其中./不能省略。
./hadoop namenode -format
如果出現如下標識,代表格式化成功。。。
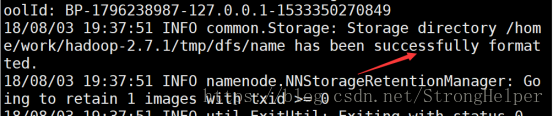
啟動hadoop
由於配置了hadoop的環境變數,可以任何目錄下執行:
start-all.sh
若沒有配置該環境變數,需要到 hadoop安裝目錄的sbin目錄下執行,其中./不能省略。
./start-all.sh
停止命令:
stop-all.sh
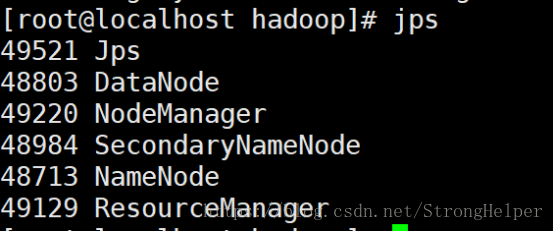
檢視程序
利用jps命令檢視,如果有如下程序,代表啟動成功。
如果出現錯誤,請檢視錯誤日誌追蹤錯誤來源。