
Spark學習(五)---RDD原理解析和spark執行架構
這次我們介紹RDD的原理和spark執行機制
- RDD依賴關係
- RDD快取
- RDD容錯機制
- spark執行架構
- spark任務排程
1. RDD原理
首先我們對之前的單詞統計的程式碼做一個畫圖展示
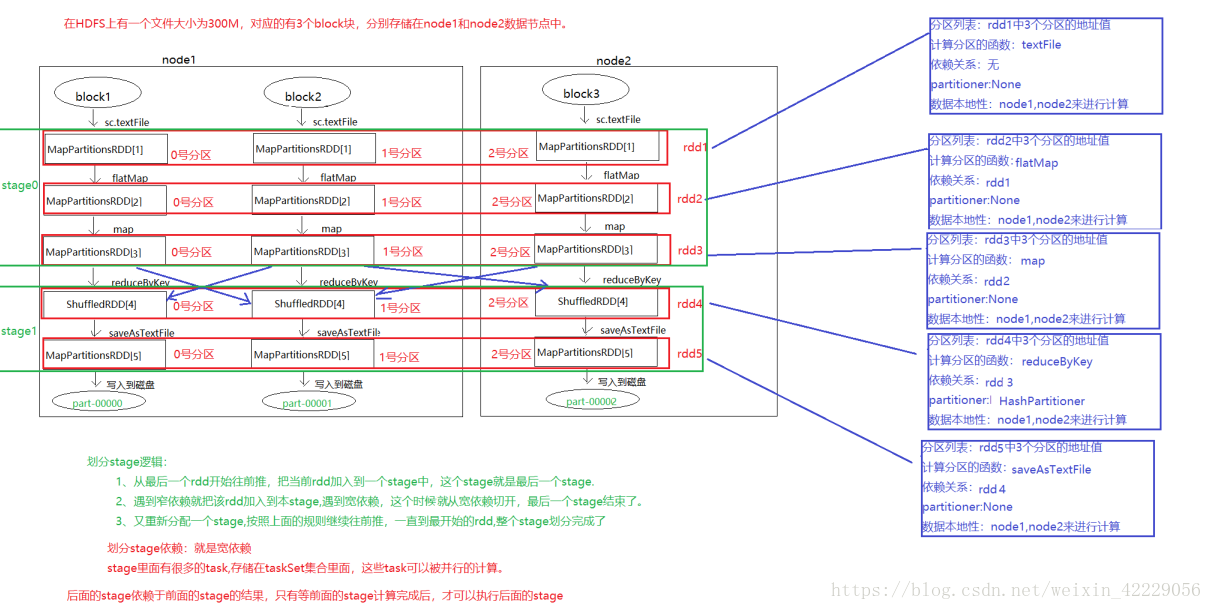
1.1 RDD依賴關係
RDD和它依賴的父RDD的關係有兩種不同的型別,即窄依賴(narrow dependency)和寬依賴(wide dependency)。
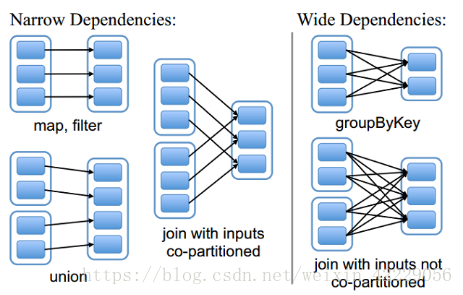
- 窄依賴 窄依賴指的是每一個父RDD的Partition最多被子RDD的一個Partition使用 總結:窄依賴我們形象的比喻為獨生子女
- 寬依賴 寬依賴指的是多個子RDD的Partition會依賴同一個父RDD的Partition 總結:寬依賴我們形象的比喻為超生
- Lineage(血統) RDD只支援粗粒度轉換,即只記錄單個塊上執行的單個操作。將建立RDD的一系列Lineage(即血統)記錄下來,以便恢復丟失的分割槽。RDD的Lineage會記錄RDD的元資料資訊和轉換行為,當該RDD的部分分割槽資料丟失時,它可以根據這些資訊來重新運算和恢復丟失的資料分割槽。
1.2 RDD快取
Spark速度非常快的原因之一,就是在不同操作中可以在記憶體中持久化或者快取資料集。當持久化某個RDD後,每一個節點都將把計算分割槽結果儲存在記憶體中,對此RDD或衍生出的RDD進行的其他動作中重用。這使得後續的動作變得更加迅速。RDD相關的持久化和快取,是Spark最重要的特徵之一。可以說,快取是Spark構建迭代式演算法和快速互動式查詢的關鍵。
- 快取方式 RDD通過persist方法或cache方法可以將前面的計算結果快取,但是並不是這兩個方法被呼叫時立即快取,而是觸發後面的action時,該RDD將會被快取在計算節點的記憶體中,並供後面重用。
- cache方法 通過檢視原始碼發現cache最終也是呼叫了persist方法,預設的儲存級別都是僅在記憶體儲存一份
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) /** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def cache(): this.type = persist()
- Persist方法 在persist方法中,可以設定多個快取級別,檢視原始碼會看到不同的快取機制 用法 file.persist(StorageLevel.MEMORY_ONLY_2)
/**
* Various [[org.apache.spark.storage.StorageLevel]] defined and utility functions for creating
* new storage levels.
*/
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
- 快取丟失的處理機制 從上一個快取的位置讀取檔案,重新執行lineage中的任務資訊,重新計算,而不是重新載入檔案,如果所有的。 快取有可能丟失,或者儲存於記憶體的資料由於記憶體不足而被刪除,RDD的快取容錯機制保證了即使快取丟失也能保證計算的正確執行。通過基於RDD的一系列轉換,丟失的資料會被重算,由於RDD的各個Partition是相對獨立的,因此只需要計算丟失的部分即可,並不需要重算全部Partition。
1.3RDD的容錯機制之checkpoint
- checkpoint是什麼? (1)Spark 在生產環境下經常會面臨transformation的RDD非常多(例如一個Job中包含1萬個RDD)或者具體transformation的RDD本身計算特別複雜或者耗時(例如計算時長超過1個小時),這個時候就要考慮對計算結果資料持久化儲存; (2)Spark是擅長多步驟迭代的,同時擅長基於Job的複用,這個時候如果能夠對曾經計算的過程產生的資料進行復用,就可以極大的提升效率; (3)如果採用persist把資料放在記憶體中,雖然是快速的,但是也是最不可靠的;如果把資料放在磁碟上,也不是完全可靠的!例如磁碟會損壞,系統管理員可能清空磁碟。 (4)Checkpoint的產生就是為了相對而言更加可靠的持久化資料,在Checkpoint的時候可以指定把資料放在本地,並且是多副本的方式,但是在生產環境下是放在HDFS上,這就天然的藉助了HDFS高容錯、高可靠的特徵來完成了最大化的可靠的持久化資料的方式; 假如進行一個1萬個運算元操作,在9000個運算元的時候persist,資料還是有可能丟失的,但是如果checkpoint,資料丟失的概率幾乎為0。
- checkpoint原理機制 當RDD使用cache機制從記憶體中讀取資料,如果資料沒有讀到,會使用checkpoint機制讀取資料。此時如果沒有checkpoint機制,那麼就需要找到父RDD重新計算資料了,因此checkpoint是個很重要的容錯機制。 checkpoint就是對於一個RDD chain(鏈)多次反覆使用的資料,就可以針對該RDD啟動checkpoint機制,使用checkpoint
- 首先需要呼叫sparkContext的setCheckpoint方法,設定一個容錯檔案系統目錄,比如hdfs,
- 然後對RDD呼叫checkpoint方法。之後在RDD所處的job執行結束後,會啟動一個單獨的job來將checkpoint過的資料寫入之前設定的檔案系統持久化,進行高可用。
- 後面的計算在使用該RDD時,如果資料丟失了,但是還是可以從它的checkpoint中讀取資料,不需要重新計算。
RDD快取和checkpoint的區別
- persist或者cache與checkpoint的區別在於,前者持久化只是將資料儲存在BlockManager中但是其lineage是不變的
- 但是後者checkpoint執行完後,rdd已經沒有依賴RDD,只有一個checkpointRDD,checkpoint之後,RDD的lineage就改變了。
- persist或者cache持久化的資料丟失的可能性更大,因為可能磁碟或記憶體被清理,但是checkpoint的資料通常儲存到hdfs上,放在了高容錯檔案系統。
2. spark執行機制
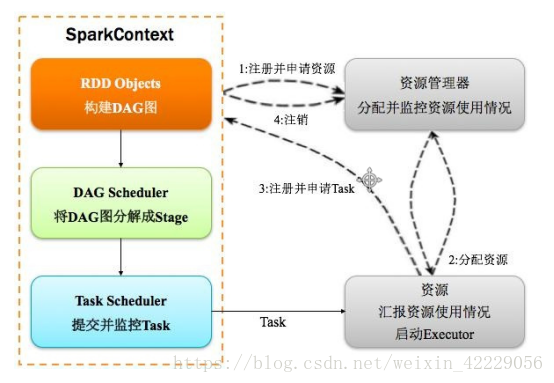
2.1 spark執行基本流程
-
構建Spark Application的執行環境(啟動SparkContext),SparkContext向資源管理器(可以是Standalone、Mesos或YARN)註冊並申請執行Executor資源;
-
資源管理器分配Executor資源並啟動Executor,Executor執行情況將隨著心跳傳送到資源管理器上;
3)SparkContext構建成DAG圖,將DAG圖分解成Stage,並把Taskset傳送給Task Scheduler。Executor向SparkContext申請Task,Task Scheduler將Task發放給Executor運行同時SparkContext將應用程式程式碼發放給Executor。
4)Task在Executor上執行,執行完畢釋放所有資源。
2.2 Spark執行架構特點
- 每個Application獲取專屬的executor程序,該程序在Application期間一直駐留,並以多執行緒方式執行tasks。
- Spark任務與資源管理器無關,只要能夠獲取executor程序,並能保持相互通訊就可以了。
- 提交SparkContext的Client應該靠近Worker節點(執行Executor的節點),最好是在同一個Rack裡,因為Spark程式執行過程中SparkContext和Executor之間有大量的資訊交換;如果想在遠端叢集中執行,最好使用RPC將SparkContext提交給叢集,不要遠離Worker執行SparkContext。
- Task採用了資料本地性和推測執行的優化機制。
2.3什麼是ADG
DAG(Directed Acyclic Graph)叫做有向無環圖,原始的RDD通過一系列的轉換就形成了DAG,根據RDD之間依賴關係的不同將DAG劃分成不同的Stage(排程階段)。對於窄依賴,partition的轉換處理在一個Stage中完成計算。對於寬依賴,由於有Shuffle的存在,只能在parent RDD處理完成後,才能開始接下來的計算,因此寬依賴是劃分Stage的依據。
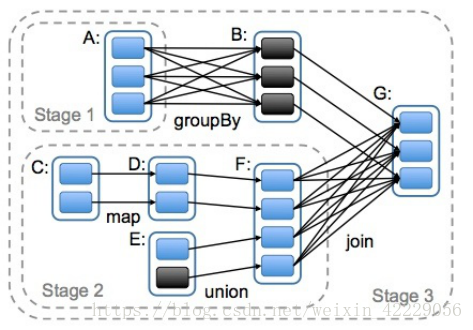
2.4 spark任務排程流程圖
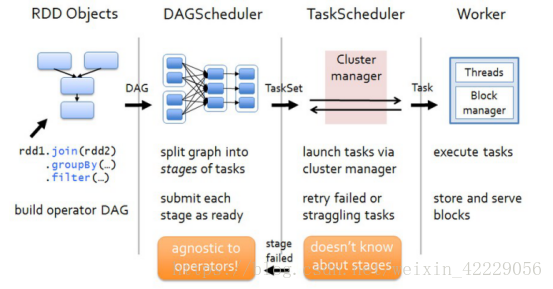
各個RDD之間存在著依賴關係,這些依賴關係就形成有向無環圖DAG,DAGScheduler對這些依賴關係形成的DAG進行Stage劃分,劃分的規則很簡單,從後往前回溯,遇到窄依賴加入本stage,遇見寬依賴進行Stage切分。完成了Stage的劃分。DAGScheduler基於每個Stage生成TaskSet,並將TaskSet提交給TaskScheduler。TaskScheduler 負責具體的task排程,最後在Worker節點上啟動task。
-
DAGScheduler (1)DAGScheduler對DAG有向無環圖進行Stage劃分。 (2)記錄哪個RDD或者 Stage 輸出被物化(快取),通常在一個複雜的shuffle之後,通常物化一下(cache、persist),方便之後的計算。 (3)重新提交shuffle輸出丟失的stage(stage內部計算出錯)給TaskScheduler 將 Taskset 傳給底層排程器 (4)將 Taskset 傳給底層排程器
- a)– spark-cluster TaskScheduler
- b)– yarn-cluster YarnClusterScheduler
- c)– yarn-client YarnClientClusterScheduler
-
TaskScheduler (1)為每一個TaskSet構建一個TaskSetManager 例項管理這個TaskSet 的生命週期 (2)資料本地性決定每個Task最佳位置 (3)提交 taskset( 一組task) 到叢集執行並監控 (4)推測執行,碰到計算緩慢任務需要放到別的節點上重試 (5)重新提交Shuffle輸出丟失的Stage給DAGScheduler
本次介紹結束