
Kafka入門學習
Kafka入門學習
用簡單的話來說,你可以把Kafka當作可順序寫入的一大卷磁帶, 可以隨時倒帶,快進到某個時間點重放。

====常用開源分散式訊息系統
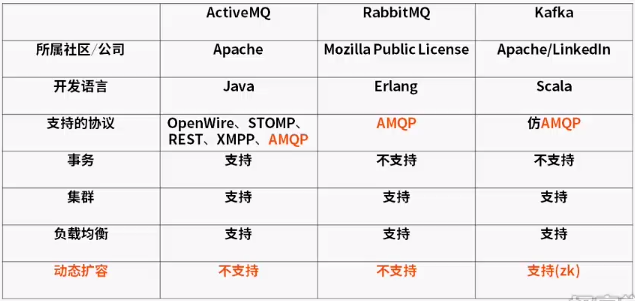
*叢集:多臺機器組成的系統叫叢集。
*ActiveMQ還是支援JMS的一種訊息中介軟體。
*阿里巴巴metaq,rocketmq都有kafka的影子。
*kafka的動態擴容目前是通過zookeeper來完成的。
====kafka定義及使用背景
是一個分散式訊息系統,由Linkedln使用Scala編寫,用作Linkedln的活動流(Activity Stream)
和運營資料處理管道(Pipeline)的基礎,具有高水平擴充套件和高吞吐量
應用領域:已經被多家不同型別的公司作為多種型別的資料管道和訊息系統使用,如:淘寶、支付寶、百度、twitter等。
目前越來越多的開元分散式處理系統都支援與Kafka整合,如
Apache flume(用於日誌收集)
Apache Storm(用於實時資料處理)
Spark(用於記憶體資料處理)
elasticsearch(用於全文檢索)
====kafka相關概念
1)AMPQ協議(即Advanced Message Queuing Protocol)
詳細參考部落格:

--消費者(Consumer):從訊息佇列中請求訊息的客戶端應用程式;
--生產者(Producer):從broker釋出訊息的客戶端應用程式;
--APQP伺服器端(broker):用來接收生產者傳送的訊息並將這些訊息路由給伺服器中的佇列;
2)kafka支援的客戶端語言
kafaka客戶端支援當前大部分主流語言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ryby、Go、JavaScript。
可以使用以上任何一種語言和kafka伺服器進行通訊(即編寫自己的consumer和producer程式)
3)kafka的架構
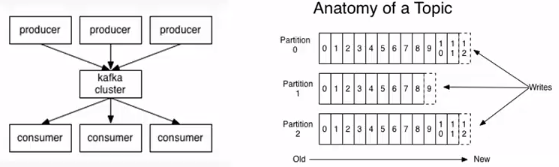
和傳統的分散式訊息佇列一樣,是由生產者向kafka叢集生產訊息、消費者從kafka叢集訂閱訊息z這樣的架構所組成。
kafka叢集中的訊息是按照主題(或者說Topic)來進行組成的。
--主題(Topic):一個主題類似新聞中的體育、娛樂、教育等分類概念,在實際工程中通常一個業務一個主題。
--分割槽(Partition):一個Topic中的訊息資料按照多個分割槽組織,分割槽是kafka訊息佇列組織的最小單位,一個分割槽可以看做是一個FIFO(先進先出)佇列;kafka分割槽是提高kafka效能的關鍵手段。
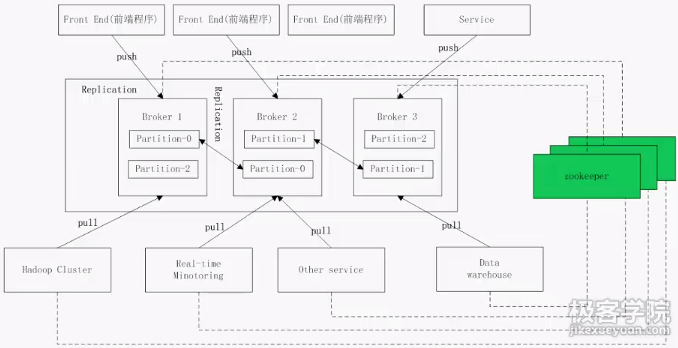
這張圖在整體上對kafka叢集進行了概要,途中kafka叢集是由三臺機器(Broker)組成,當然,實際情況可能更多。
相應的有3個分割槽,Partition-0~Partition-2,圖中能看到每個分割槽的資料備份了2份。備份的數量可以通過kafka的配置引數來進行配置。在圖中配置成了2.
kafka叢集從前端應用程式(producer)生產訊息,後端通過各種異構的消費者來訂閱訊息。
kafka叢集和各種異構的生產者、消費者都使用zookeeper叢集來進行分散式協調管理和分散式狀態管理、分散式鎖服務的。
*備份(Replication):為了保證分散式可靠性,kafka0.8開始對每個分割槽的資料進行備份(不同Broker上),防止其中一個Broker宕機造成分割槽資料不可用。
====zookeeper叢集搭建
參考部落格:http://www.cnblogs.com/ggjucheng/p/3352591.html
- 軟體環境:
1)Linux伺服器一臺、三臺、舞臺(2*n+1臺)。
問:是否可以用偶數臺來搭建?
答:不一定,但是沒有必要。根據zookeeper的工作原理,只要有超過半數以上存活,就可以對外提供服務。奇數方便判斷“半數存活”。
2)JDK(我這裡選擇jdk-7u80-linux-x64.rpm)
3)zookeeper(我這裡選擇zookeeper-3.4.6.tar.gz,kafka在該版本上進行了大量測試,並修復了大量Bug)
- JDK安裝
(省略)
環境變數可以修改兩個檔案
1)/etc/profile:對所有使用者都有效的。
2)~/.bashrc:代表的是當前使用者。
- zookeeper安裝
1)解壓縮:tar -zxvf zookeeper-3.4.6.tar.gz
2)配置檔案:
--zoo.cfg檔案的配置
zoo_sample.cfg是zk官方為我們提供的樣本配置檔案。
需要以它為副本複製一個zoo.cfg檔案。zoo.cfg中需要配置以下內容:
•dataDir:存放資料
•dataLogDir:存放日誌和快照
•server.1=<host>:<Master和Slave之間的通訊埠。預設為2888>:<Leader選舉的埠。預設3888>。
叢集中的每臺機器都需要感知整個叢集是由哪幾臺機器組成的,在配置檔案中,可以按照這樣的格式,每行寫一個機器配置:server.id=host:port:port。
關於這個id,我們稱之為Server ID,標識host機器在叢集中的機器序號,在每個ZK機器上,我們需要在資料目錄(資料目錄就是dataDir引數指定的那個目錄)下建立一個myid檔案,
myid中就是這個Server ID數字。
配置之後如下:
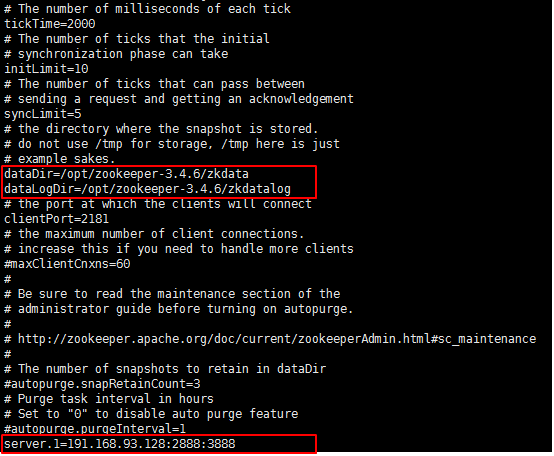
*zkdata和zkdatalog是新建的資料夾。用來存放資料和Log。
*dataLogDir這個屬性如果不進行配置,將預設將zk事務日誌和快照存放到dataDir下面,會嚴重影響效能。
*ip地址可以通過hostname -i來檢視。
--myid的配置
可以通過echo命令來建立myid檔案。命令:echo "1" > myid
3)啟動zookeeper
啟動方法:./zkServer.sh start
====kafka叢集搭建
- 軟體環境
Linux伺服器一臺或多臺
已經搭建好的zookeeper叢集
kafka_2.9.2-0.8.1.1
- kafka安裝
1)解壓縮kafka壓縮包:tar -zxvf kafka_2.9.2-0.8.1.1
2)修改配置檔案。kafka的配置檔案很多,我們重點關注server.properties
具體配置內容請參考官方網站的配置:http://kafka.apache.org/documentation.html#brokerconfigs
以及中文部落格:http://www.cnblogs.com/quchunhui/p/5356720.html
我這裡配置了一下幾項:
###Socket Server Settings###
port=9092
host.name=192.168.93.128
###Log Basics###
log.dirs=/opt/kafka_2.9.2-0.8.1.1/kafkalog
###Log Retention Policy###
message.max.bytes=5048576
default.replication.factor=2 //kafka叢集儲存訊息的副本數
replica.fetch.max.bytes=5048576 //取訊息的最大位元組數
###Zookeeper###
zookeeper.connect=192.168.93.128:2181
- kafka啟動
後臺啟動命令:./kafka-server-start.sh -daemon ../config/server.properties
使用jps命令檢視程序是否存在,以驗證是否正確啟動。
- 驗證是否搭建正確
(1)首先嚐試建立一個topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
(2)檢視所有的topic
./kafka-topics.sh --list --zookeeper localhost:2181
(3)啟動一個consumer
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
(4)向consumer傳送訊息
./kafka-console-producer.sh --broker-list 192.168.93.129:9092 --topic test
(5)檢視建立的topic
./kafka-topics.sh --describe --zookeeper 192.168.93.129:2181 --topic test
kafka中server.properties配置檔案引數說明
轉自:http://blog.csdn.net/lizhitao/article/details/25667831
| 引數 |
說明(解釋) |
| broker.id =0 |
每一個broker在叢集中的唯一表示,要求是正數。當該伺服器的IP地址發生改變時,broker.id沒有變化,則不會影響consumers的訊息情況 |
| log.dirs=/data/kafka-logs |
kafka資料的存放地址,多個地址的話用逗號分割/data/kafka-logs-1,/data/kafka-logs-2 |
| port =9092 |
broker server服務埠 |
| message.max.bytes =6525000 |
表示訊息體的最大大小,單位是位元組 |
| num.network.threads =4 |
broker處理訊息的最大執行緒數,一般情況下不需要去修改 |
| num.io.threads =8 |
broker處理磁碟IO的執行緒數,數值應該大於你的硬碟數 |
| background.threads =4 |
一些後臺任務處理的執行緒數,例如過期訊息檔案的刪除等,一般情況下不需要去做修改 |
| queued.max.requests =500 |
等待IO執行緒處理的請求佇列最大數,若是等待IO的請求超過這個數值,那麼會停止接受外部訊息,應該是一種自我保護機制。 |
| host.name |
broker的主機地址,若是設定了,那麼會繫結到這個地址上,若是沒有,會繫結到所有的介面上,並將其中之一發送到ZK,一般不設定 |
| socket.send.buffer.bytes=100*1024 |
socket的傳送緩衝區,socket的調優引數SO_SNDBUFF |
| socket.receive.buffer.bytes =100*1024 |
socket的接受緩衝區,socket的調優引數SO_RCVBUFF |
| socket.request.max.bytes =100*1024*1024 |
socket請求的最大數值,防止serverOOM,message.max.bytes必然要小於socket.request.max.bytes,會被topic建立時的指定引數覆蓋 |
| log.segment.bytes =1024*1024*1024 |
topic的分割槽是以一堆segment檔案儲存的,這個控制每個segment的大小,會被topic建立時的指定引數覆蓋 |
| log.roll.hours =24*7 |
這個引數會在日誌segment沒有達到log.segment.bytes設定的大小,也會強制新建一個segment會被 topic建立時的指定引數覆蓋 |
| log.cleanup.policy = delete |
日誌清理策略選擇有:delete和compact主要針對過期資料的處理,或是日誌檔案達到限制的額度,會被 topic建立時的指定引數覆蓋 |
| log.retention.minutes=3days |
資料儲存的最大時間超過這個時間會根據log.cleanup.policy設定的策略處理資料,也就是消費端能夠多久去消費資料 log.retention.bytes和log.retention.minutes任意一個達到要求,都會執行刪除,會被topic建立時的指定引數覆蓋 |
| log.retention.bytes=-1 |
topic每個分割槽的最大檔案大小,一個topic的大小限制 =分割槽數*log.retention.bytes。-1沒有大小限log.retention.bytes和log.retention.minutes任意一個達到要求,都會執行刪除,會被topic建立時的指定引數覆蓋 |
| log.retention.check.interval.ms=5minutes |
檔案大小檢查的週期時間,是否處罰 log.cleanup.policy中設定的策略 |
| log.cleaner.enable=false |
是否開啟日誌壓縮 |
| log.cleaner.threads = 2 |
日誌壓縮執行的執行緒數 |
| log.cleaner.io.max.bytes.per.second=None |
日誌壓縮時候處理的最大大小 |
| log.cleaner.dedupe.buffer.size=500*1024*1024 |
日誌壓縮去重時候的快取空間,在空間允許的情況下,越大越好 |
| log.cleaner.io.buffer.size=512*1024 |
日誌清理時候用到的IO塊大小一般不需要修改 |
| log.cleaner.io.buffer.load.factor =0.9 |
日誌清理中hash表的擴大因子一般不需要修改 |
| log.cleaner.backoff.ms =15000 |
檢查是否處罰日誌清理的間隔 |
| log.cleaner.min.cleanable.ratio=0.5 |
日誌清理的頻率控制,越大意味著更高效的清理,同時會存在一些空間上的浪費,會被topic建立時的指定引數覆蓋 |
| log.cleaner.delete.retention.ms =1day |
對於壓縮的日誌保留的最長時間,也是客戶端消費訊息的最長時間,同log.retention.minutes的區別在於一個控制未壓縮資料,一個控制壓縮後的資料。會被topic建立時的指定引數覆蓋 |
| log.index.size.max.bytes =10*1024*1024 |
對於segment日誌的索引檔案大小限制,會被topic建立時的指定引數覆蓋 |
| log.index.interval.bytes =4096 |
當執行一個fetch操作後,需要一定的空間來掃描最近的offset大小,設定越大,代表掃描速度越快,但是也更好記憶體,一般情況下不需要搭理這個引數 |
| log.flush.interval.messages=None |
log檔案”sync”到磁碟之前累積的訊息條數,因為磁碟IO操作是一個慢操作,但又是一個”資料可靠性"的必要手段,所以此引數的設定,需要在"資料可靠性"與"效能"之間做必要的權衡.如果此值過大,將會導致每次"fsync"的時間較長(IO阻塞),如果此值過小,將會導致"fsync"的次數較多,這也意味著整體的client請求有一定的延遲.物理server故障,將會導致沒有fsync的訊息丟失. |
| log.flush.scheduler.interval.ms =3000 |
檢查是否需要固化到硬碟的時間間隔 |
| log.flush.interval.ms = None |
僅僅通過interval來控制訊息的磁碟寫入時機,是不足的.此引數用於控制"fsync"的時間間隔,如果訊息量始終沒有達到閥值,但是離上一次磁碟同步的時間間隔達到閥值,也將觸發. |
| log.delete.delay.ms =60000 |
檔案在索引中清除後保留的時間一般不需要去修改 |
| log.flush.offset.checkpoint.interval.ms =60000 |
控制上次固化硬碟的時間點,以便於資料恢復一般不需要去修改 |
| auto.create.topics.enable =true |
是否允許自動建立topic,若是false,就需要通過命令建立topic |
| default.replication.factor =1 |
是否允許自動建立topic,若是false,就需要通過命令建立topic |
| num.partitions =1 |
每個topic的分割槽個數,若是在topic建立時候沒有指定的話會被topic建立時的指定引數覆蓋 |
|
|
|
| 以下是kafka中Leader,replicas配置引數 |
|
| controller.socket.timeout.ms =30000 |
partition leader與replicas之間通訊時,socket的超時時間 |
| controller.message.queue.size=10 |
partition leader與replicas資料同步時,訊息的佇列尺寸 |
| replica.lag.time.max.ms =10000 |
replicas響應partition leader的最長等待時間,若是超過這個時間,就將replicas列入ISR(in-sync replicas),並認為它是死的,不會再加入管理中 |
| replica.lag.max.messages =4000 |
如果follower落後與leader太多,將會認為此follower[或者說partition relicas]已經失效 ##通常,在follower與leader通訊時,因為網路延遲或者連結斷開,總會導致replicas中訊息同步滯後 ##如果訊息之後太多,leader將認為此follower網路延遲較大或者訊息吞吐能力有限,將會把此replicas遷移 ##到其他follower中. ##在broker數量較少,或者網路不足的環境中,建議提高此值. |
| replica.socket.timeout.ms=30*1000 |
follower與leader之間的socket超時時間 |
| replica.socket.receive.buffer.bytes=64*1024 |
leader複製時候的socket快取大小 |
| replica.fetch.max.bytes =1024*1024 |
replicas每次獲取資料的最大大小 |
| replica.fetch.wait.max.ms =500 |
replicas同leader之間通訊的最大等待時間,失敗了會重試 |
| replica.fetch.min.bytes =1 |
fetch的最小資料尺寸,如果leader中尚未同步的資料不足此值,將會阻塞,直到滿足條件 |
| num.replica.fetchers=1 |
leader進行復制的執行緒數,增大這個數值會增加follower的IO |
| replica.high.watermark.checkpoint.interval.ms =5000 |
每個replica檢查是否將最高水位進行固化的頻率 |
| controlled.shutdown.enable =false |
是否允許控制器關閉broker ,若是設定為true,會關閉所有在這個broker上的leader,並轉移到其他broker |
| controlled.shutdown.max.retries =3 |
控制器關閉的嘗試次數 |
| controlled.shutdown.retry.backoff.ms =5000 |
每次關閉嘗試的時間間隔 |
| leader.imbalance.per.broker.percentage =10 |
leader的不平衡比例,若是超過這個數值,會對分割槽進行重新的平衡 |
| leader.imbalance.check.interval.seconds =300 |
檢查leader是否不平衡的時間間隔 |
| offset.metadata.max.bytes |
客戶端保留offset資訊的最大空間大小 |
| kafka中zookeeper引數配置 |
|
| zookeeper.connect = localhost:2181 |
zookeeper叢集的地址,可以是多個,多個之間用逗號分割hostname1:port1,hostname2:port2,hostname3:port3 |
| zookeeper.session.timeout.ms=6000 |
ZooKeeper的最大超時時間,就是心跳的間隔,若是沒有反映,那麼認為已經死了,不易過大 |
| zookeeper.connection.timeout.ms =6000 |
ZooKeeper的連線超時時間 |
| zookeeper.sync.time.ms =2000 |
ZooKeeper叢集中leader和follower之間的同步實際那
|
頂