
阿里巴巴開發手冊解析個人筆記(二)Mysql規約
阿新 • • 發佈:2018-12-16
文章目錄
1.建立資料庫
11.【推薦】庫名與應用名稱儘量一致。
2. 建立表
14.【推薦】單錶行數超過 500 萬行或者單表容量超過 2GB,才推薦進行分庫分表。
說明: 如果預計三年後的資料量根本達不到這個級別,請不要在建立表時就分庫分表。
2.1 建立名稱
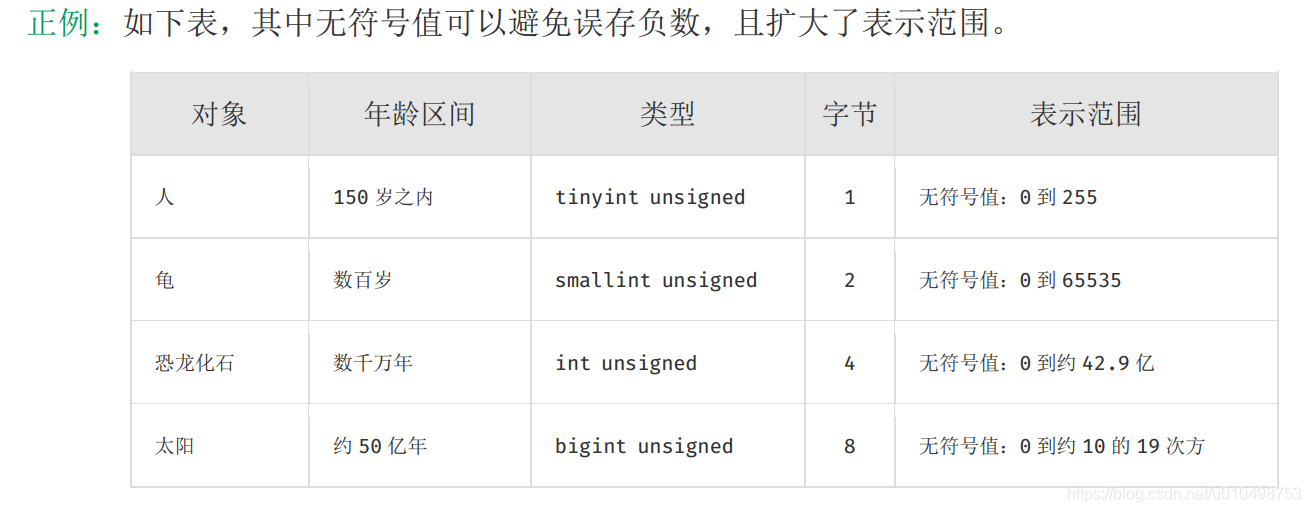
2.【強制】表名、欄位名必須使用小寫字母或數字, 禁止出現數字開頭,禁止兩個下劃線中間只 出現數字。資料庫欄位名的修改代價很大,因為無法進行預釋出,所以欄位名稱需要慎重考慮。 說明: MySQL 在 Windows 下不區分大小寫,但在 Linux 下預設是區分大小寫。因此,資料庫名、 表名、欄位名,都不允許出現任何大寫字母,避免節外生枝。
3. 【強制】表名不使用複數名詞。
10.【推薦】表的命名最好是加上“業務名稱_表的作用”。
2.2 建立索引
11.【參考】建立索引時避免有如下極端誤解:
1) 寧濫勿缺。 認為一個查詢就需要建一個索引。
2) 寧缺勿濫。 認為索引會消耗空間、嚴重拖慢更新和新增速度。
3) 抵制惟一索引。 認為業務的惟一性一律需要在應用層通過“先查後插”方式解決。
3.建立欄位
13.【推薦】欄位允許適當冗餘,以提高查詢效能,但必須考慮資料一致。冗餘欄位應遵循: 1) 不是頻繁修改的欄位。 2) 不是 varchar 超長欄位,更不能是 text 欄位。 正例: 商品類目名稱使用頻率高,欄位長度短,名稱基本一成不變,可在相關聯的表中冗餘存 儲類目名稱,避免關聯查詢
6. 【強制】不得使用外來鍵與級聯,一切外來鍵概念必須在應用層解決。
說明:以學生和成績的關係為例,學生表中的 student_id是主鍵,那麼成績表中的 student_id
則為外來鍵。如果更新學生表中的 student_id,同時觸發成績表中的 student_id 更新, 即為
級聯更新。外來鍵與級聯更新適用於單機低併發,不適合分散式、高併發叢集; 級聯更新是強阻
塞,存在資料庫更新風暴的風險; 外來鍵影響資料庫的插入速度。
10.【參考】 如果有國際化需要,所有的字元儲存與表示,均以 utf-8 編碼,注意字元統計函式
的區別。
說明:
SELECT LENGTH("輕鬆工作"); 返回為 12
SELECT CHARACTER_LENGTH("輕鬆工作"); 返回為 4
如果需要儲存表情,那麼選擇 utf8mb4 來進行儲存,注意它與 utf-8 編碼的區別。
3.1 建立名稱
1. 【強制】表達是與否概念的欄位,必須使用 is_xxx 的方式命名,資料型別是 unsigned tinyint(1 表示是, 0 表示否)。
5. 【強制】 主鍵索引名為 pk_欄位名; 唯一索引名為 uk_欄位名; 普通索引名則為 idx_欄位名。
9. 【強制】表必備三欄位: id, gmt_create, gmt_modified
12.【推薦】如果修改欄位含義或對欄位表示的狀態追加時,需要及時更新欄位註釋。
3.2 建立型別
6. 【強制】小數型別為 decimal,禁止使用 float 和 double。
7. 【強制】如果儲存的字串長度幾乎相等,使用 char 定長字串型別。
8. 【強制】 varchar 是可變長字串,不預先分配儲存空間,長度不要超過 5000,如果儲存長度大於此值,定義欄位型別為text,獨立出來一張表,用主鍵來對應,避免影響其它欄位索引效率
15. 【參考】合適的字元儲存長度,不但節約資料庫表空間、節約索引儲存,更重要的是提升檢
索速度。
4.sql的執行流程
4.1解析
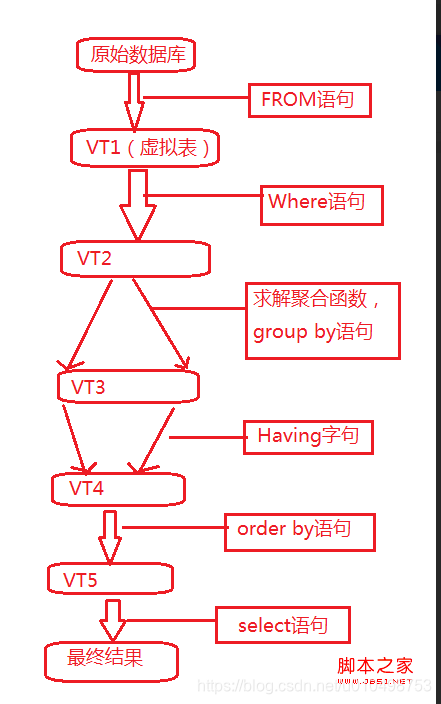
4.2編寫sql
4. 【強制】禁用保留字,如 desc、 range、 match、 delayed 等, 請參考 MySQL 官方保留字。
4.2.1 from 表
2. 【強制】超過三個表禁止 join。需要 join 的欄位,資料型別必須絕對一致; 多表關聯查詢時,
保證被關聯的欄位需要有索引。
說明: 即使雙表 join 也要注意表索引、 SQL 效能。
4.2.2where
4. 【強制】頁面搜尋嚴禁左模糊或者全模糊,如果需要請走搜尋引擎來解決。
說明: 索引檔案具有 B-Tree 的最左字首匹配特性,如果左邊的值未確定,那麼無法使用此索
引
9. 【推薦】 in 操作能避免則避免,若實在避免不了,需要仔細評估 in 後邊的集合元素數量,控
制在 1000 個之內。
4.2.3 聚合函式
1. 【強制】不要使用 count(列名)或 count(常量)來替代 count(*), count(*)是 SQL92 定義的
標準統計行數的語法,跟資料庫無關,跟 NULL 和非 NULL 無關。
說明: count(*)會統計值為 NULL 的行,而 count(列名)不會統計此列為 NULL 值的行。
2. 【強制】 count(distinct col) 計算該列除 NULL 之外的不重複行數, 注意 count(distinct
col1, col2) 如果其中一列全為 NULL,那麼即使另一列有不同的值,也返回為 0。
3. 【強制】當某一列的值全是 NULL 時, count(col)的返回結果為 0,但 sum(col)的返回結果為
NULL,因此使用 sum()時需注意 NPE 問題。
正例: 可以使用如下方式來避免 sum 的 NPE 問題: SELECT IF(ISNULL(SUM(g)),0,SUM(g))
FROM table;
5. 【強制】 在程式碼中寫分頁查詢邏輯時,若 count 為 0 應直接返回,避免執行後面的分頁語句。
4.2.4 group-by
4.2.5 having
4.2.6 order by
5. 【推薦】如果有 order by 的場景,請注意利用索引的有序性。 order by 最後的欄位是組合
索引的一部分,並且放在索引組合順序的最後,避免出現 file_sort 的情況,影響查詢效能。
正例: where a=? and b=? order by c; 索引: a_b_c
反例: 索引中有範圍查詢,那麼索引有序性無法利用,如: WHERE a>10 ORDER BY b; 索引
a_b 無法排序。
4.2.6 select
8. 【推薦】 SQL 效能優化的目標:至少要達到 range 級別, 要求是 ref 級別, 如果可以是 consts
最好。
說明:
1) consts 單表中最多隻有一個匹配行(主鍵或者唯一索引) ,在優化階段即可讀取到資料。
2) ref 指的是使用普通的索引(normal index) 。
3) range 對索引進行範圍檢索。
反例: explain 表的結果, type=index,索引物理檔案全掃描,速度非常慢,這個 index 級
別比較 range 還低,與全表掃描是小巫見大巫。
1. 【強制】在表查詢中,一律不要使用 * 作為查詢的欄位列表,需要哪些欄位必須明確寫明。
說明: 1) 增加查詢分析器解析成本。 2) 增減欄位容易與 resultMap 配置不一致。 3)無用字
段增加網路消耗,尤其是 text 型別的欄位。
4.2.7 update 與 delete
11.【參考】 TRUNCATE TABLE 比 DELETE 速度快,且使用的系統和事務日誌資源少,但 TRUNCATE
無事務且不觸發 trigger,有可能造成事故,故不建議在開發程式碼中使用此語句。
說明: TRUNCATE TABLE 在功能上與不帶 WHERE 子句的 DELETE 語句相同
8.【強制】資料訂正(特別是刪除、 修改記錄操作) 時,要先 select,避免出現誤刪除,確認
無誤才能執行更新語句。