
正則表示式的簡單知識
正則表示式
-
正則.test(字串)
成功返回true,失敗返回false,可用於if()條件判斷。 -
正則.exec(字串)
-
字串.match(正則)
Str.match(reg),匹配成功會返回匹配成的陣列,否則返回null。 -
字串.search(正則)
匹配成功返回匹配成功的位置(即字元的下標),失敗則返回-1。 -
字串.replace(正則)
Str.replace(reg, “字串”| 回撥函式function(引數1[引數2,,,,])),回撥函式的引數1就是匹配成功的字元。str.replace(re,function($0,$1){ //$0代表整體,$1代表第一個子項

字元:
^ 匹配一個輸入或一行的開頭
. 表示除了換行符以外的任意字元,等價於[ ^\n]
$ 匹配一行的結尾
{n, m} 匹配前一項至少n次,但是不能超過m次
{n, } 匹配前一項n次,或者多次
{n} 匹配前一項恰好n次
*:表示匹配0個或多個字元。等價於{0,}
+:表示匹配1個或1個以上的字元.等價於{1,}
. :表示任意字元。(若需要表示單純的. 則要用. )。
?:表示匹配前一項0或1次。,也就是說前一項是可選的. 等價於 {0, 1}
\d 匹配一個字數字符,/\d/ = /[0-9]/
\D 匹配一個非字數字符,/\D/ = /[ ^0-9]/
\w 匹配一個可以組成單詞的字元(alphanumeric,這是我的意譯,含數字),包括下劃線,如[\w]匹配"$5.98"中的5,等於[a-zA-Z0-9]
\W 匹配一個不可以組成單詞的字元,如[\W]匹配"$5.98"中的$,等於[ ^a-zA-Z0-9]。
[xyz] 字符集(character set),匹配這個集合中的任一一個字元(或元字元)
[ ^xyz] 不匹配這個集合中的任何一個字元
\s:表示匹配一個空白字元 ,包括\n,\r,\f,\t,\v等
\S:表示匹配一個非空白字元.等於/[ ^\n\f\r\t\v]/
Eg:/\s+java\s+/ //匹配字串"java" ,並且該串前後可以有一個或多個空格
\ 數字: 重複子項(如\1:重複的第一個子項,\2:重複的第二個子項…)
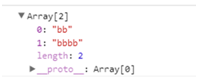
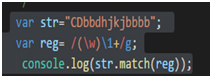
如:var reg = /(\w)\1+/g \1表示重複的字元如bbb,nn類似的
標記:
a) i 執行大小寫不敏感的匹配
b) g 執行一個全域性的匹配,簡而言之,就是找到所有的匹配,而不是在找到第一個之後就停止了。
c) M 表示多行搜尋。