
反爬蟲的一些心得
- 轉載請註明來源
- 本帖持續更新
1. 為什麼會彈出驗證碼
訪問頻率太高,網站會針對性的彈出驗證碼限制你的訪問,一般有這幾種情況:
- 記錄了你的IP訪問頻率,針對IP彈出驗證碼
- 記錄了你的cookies訪問頻率,針對此賬號彈出驗證碼
- 雙管齊下,同時限制你的IP和賬號的訪問
2. 比較好的驗證碼設計
2.1 第一種
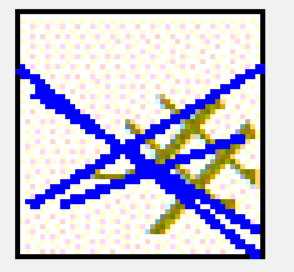
這種好像是谷歌的驗證碼生成庫生成的中文驗證碼。
拋開大量樣本的深度學習不說,這種驗證碼的難點在於:
- 干擾線粗,幾乎和字元差不多,佔面積大,難以使用一般的降噪演算法解決;
- 干擾線和字型顏色多變,有時候為同一種顏色,無法使用顏色分離演算法;
- 背景色跨度大,加上干擾線和字元顏色也多變,難以準確的消除背景。
特徵:觀察了若干樣本,發現干擾線的顏色一致,長度也固定在某個範圍,且基本上都會比漢字字元的筆畫長。
3. 引數加密是怎麼回事
相關推薦
反爬蟲的一些心得
轉載請註明來源 本帖持續更新 1. 為什麼會彈出驗證碼 訪問頻率太高,網站會針對性的彈出驗證碼限制你的訪問,一般有這幾種情況: 記錄了你的IP訪問頻率,針對IP彈出驗證碼 記錄了你的cookies訪問頻率,針對此賬號彈出驗證碼 雙管齊下
反爬蟲——使用chrome headless時一些需要註意的細節
mem -- protoc 啟用 pre 使用 web 內容 bom 以前我們介紹過chrome headless的用法(https://www.cnblogs.com/apocelipes/p/9264673.html)。 今天我們要稍微提一下其中一個細節。 反爬和w
爬蟲的一些步驟和怎樣進行反爬蟲
爬蟲是一個比較容易上手的技術,也許花5分鐘看一篇文件就能爬取單個網頁上的資料。但對於大規模爬蟲,完全就是另一回事,並不是1*n這麼簡單,還會衍生出許多別的問題。系統的大規模爬蟲流程如圖所示。先檢查是否有APIAPI是網站官方提供的資料介面,如果通過呼叫API採集資料,則相當於
對於反爬蟲的一些思考
1.反爬蟲宗旨爬蟲與反爬蟲是一個迴圈往復、互相博弈的過程,並沒有一種一勞永逸的辦法杜絕所有爬蟲的爬取(更何況搜尋引擎也算是爬蟲的一種)。在應用反爬蟲的過程中,只能做到儘可能的識別爬蟲,儘可能的提高爬蟲爬
python 反編譯 pyc 一些心得
0x01 , 現在用python的人也多了起來,程式碼安全始終是我們要考慮的問題,比如說我們要將我們的成果釋出出去,py直接釋出肯定是不行的(除非你是開源的),那麼我們就只能考慮釋出pyc檔案了, 0x02,今天討論的就是怎麼反編譯pyc到原始碼的技術,從道理上來講,這個是完全沒問題的,而且反編譯出
使用scrapy做爬蟲遇到的一些坑:網站常用的反爬蟲策略,如何機智的躲過反爬蟲Crawled (403)
在這幅圖中我們可以很清晰地看到爬蟲與反爬蟲是如何進行鬥智鬥勇的。在學習使用爬蟲時,我們製作出來的爬蟲往往是在“裸奔”,非常的簡單。簡單低階的爬蟲有一個很大的優點:速度快,偽裝度低。如果你爬取的網站沒有反爬機制,爬蟲們可以非常簡單粗暴地快速抓取大量資料,但是這樣往往就導致一個問
關於反爬蟲的一些總結
1、爬取過程中的302重定向 在爬取某個網站速度過快或者發出的請求過多的時候,網站會向你所在的客戶端傳送一個連結,需要你去驗證圖片。我在爬鏈家和拉鉤網的過程中就曾經遇到過: 對於302重定向的問題,是由於抓取速度過快引起網路流量異常,伺服器識別出是機器傳送的請求,
寫了項目的一些心得
代碼 寫代碼 邏輯 解決 慢慢 console 提示 這一 清晰 在這幾周我們在寫以後後臺管理人員的項目 在這期間出現了各種各樣大問題,小問題,對有些 功能代碼實現也熟練不少,但是問題還是挺多的,最典型的就是沒思路,對於剛拿到分配的任務 盡力自己先試試,慢慢入手,實在不行讓
爬蟲與反爬蟲
團隊 不定 足夠 image 上線 向上 互聯 真心 高級技巧 轉自:https://mp.weixin.qq.com/s/-w-yC6PCdTOpfKS8HZEleA 前言 爬蟲與反爬蟲,是一個很不陽光的行業。 這裏說的不陽光,有兩個含義。 第一是,這
有趣的反爬蟲
每次 網站 child m3u8 tel 頁面 -- 改變 分享 今天在爬取一個視頻網站的時候 找到了他的視頻地址,準備開工。 網頁地址:http://m.kankanwu.com/Arts/xianchudangdao2017/player-0-0.html 網頁
爬蟲實踐---悅音臺mv排行榜與簡單反爬蟲技術應用
代碼 int logs 1.8 mac for html req 3.5 由於要抓取的是悅音臺mv的排行榜,這個排行榜是實時更新的,如果要求不停地抓取,這將有可能導致悅音臺官方采用反爬蟲的技術將ip給封掉。所以這裏要應用一些反爬蟲相關知識。 目標網址:http://vcha
【Python】爬蟲與反爬蟲大戰
公司 學校 爬取 nbsp 識別 防止 toc 壓力 自動 爬蟲與發爬蟲的廝殺,一方為了拿到數據,一方為了防止爬蟲拿到數據,誰是最後的贏家? 重新理解爬蟲中的一些概念 爬蟲:自動獲取網站數據的程序反爬蟲:使用技術手段防止爬蟲程序爬取數據誤傷:反爬蟲技術將普通用戶識別為爬蟲,
反-反爬蟲:用幾行代碼寫出和人類一樣的動態爬蟲
簽名 lib rgs 常見 todo 只需要 website 結束 pro 歡迎大家前往騰訊雲技術社區,獲取更多騰訊海量技術實踐幹貨哦~ 作者:李大偉 Phantomjs簡介 什麽是Phantomjs Phantomjs官網介紹是:不需要瀏覽器的完整web協議棧(Fu
爬取豆瓣電影儲存到數據庫MONGDB中以及反反爬蟲
ica p s latest tel mpat side nload self. pro 1.代碼如下: doubanmoive.py # -*- coding: utf-8 -*- import scrapy from douban.items import Douba
destoon使用中的一些心得
href src 解決 index.php 靜態 target ted 在線 無需 destoon使用中的一些心得 Leone- 2014-06-04 原文 //**************************index首頁相關參數******************
關於spring源碼的一些心得(一)
blog clas 實現接口 繼承 classpath mage 獲取 ssp 源碼 總結:通過前面的一些認識,可以大致認為,ioc容器就是獲取一些需要使用的對象如pojo等的引用,相當於new 而ioc容器的作用也就是用於此處,用於獲取或者讀取對象實例
我是怎樣把反反爬蟲把數據爬下來的
ie 6 nav 解決 讓我 tom safari 判斷 head 5.0 最近看到公司的商務一條一條的從某個網站上復制數據到excel裏,於是乎就打算寫個爬蟲把那個網站的數據都爬下來.一般的流程是模擬用戶訪問->獲取數據->解析頁面元素->balab
反爬蟲總結
防盜 json 很好 事情 常見 間隔 request 兩種 固然是 從功能上來講,爬蟲一般分為數據采集,處理,儲存三個部分。這裏我們只討論數據采集部分。 一般網站從三個方面反爬蟲:用戶請求的Headers,用戶行為,網站目錄和數據加載方式。前兩種比較容易遇到,大多數網站都
反反爬蟲 IP代理
ini home 過多 頻繁 寬帶 odi 代理ip com 曲線 0x01 前言 一般而言,抓取稍微正規一點的網站,都會有反爬蟲的制約。反爬蟲主要有以下幾種方式: 通過UA判斷。這是最低級的判斷,一般反爬蟲不會用這個做唯一判斷,因為反反爬蟲非常容易,直接隨機UA即可解決
反爬蟲
想法 phantomjs 標題 遊戲 資料 不用 ejs user abcd 你被爬蟲侵擾過麽?當你看到“爬蟲”兩個字的時候,是不是已經有點血脈賁張的感覺了?千萬要忍耐,稍稍做點什麽,就可以在名義上讓他們勝利,實際上讓他們受損失。 一、為什麽要反爬蟲 1、爬蟲占總PV比例較