
Facebook 的 C++ 11 元件庫 Folly Futures
Futures 是一種通過自然的、可組合的方式表達非同步計算的模式。這篇博文介紹了我們在 Facebook 中使用的一種適用於 C++11 的 futures 實現:Folly Futures。
為什麼要使用非同步?
想象一個服務 A 正在與服務 B 互動的場景。如果 A 被鎖定到 B 回覆後才能繼續進行其他操作,則 A 是同步的。此時 A 所在的執行緒是空閒的,它不能為其他的請求提供服務。執行緒會變得非常笨重-切換執行緒是低效的,因為這需要耗費可觀的記憶體,如果你進行了大量這樣的操作,作業系統會因此陷入困境。這樣做的結果就是白白浪費了資源,降低了生產力,增加了等待時間(因為請求都在佇列中等待服務)。

如果將服務 A 做成非同步的,會變得更有效率,這意味著當 B 在忙著運算的時候,A 可以轉進去處理其他請求。當 B 計算完畢得出結果後,A 獲取這個結果並結束請求。
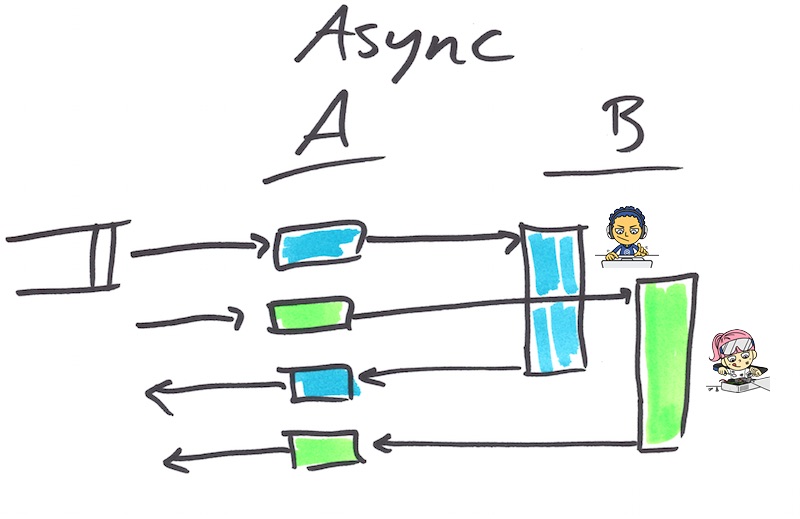
同步程式碼與非同步程式碼的比較
讓我們考慮一個函式 fooSync,這個函式使用完全同步的方式完成基本計算 foo,同時用另一個函式 fooAsync 非同步地在做同樣的工作。fooAsync 需要提供一個輸入和一個能在結果可用時呼叫的回撥函式。
template <typename T> using Callback = std::function<void(T)>; Output fooSync(Input); void fooAsync(Input, Callback<Output>);
這是一種傳統的非同步計算表達方式。(老版本的 C/C++ 非同步庫會提供一個函式指標和一個 void* 型別的上下文引數,但現在 C++11 支援隱蔽功能,已經不再需要顯式提供上下文引數)
傳統的非同步程式碼比同步程式碼更為有效,但它的可讀性不高。對比同一個函式的同步和非同步版本,它們都實現了一個 multiFoo 運算,這個運算為輸入向量(vector)中的每一個元素執行 foo 操作:
using std::vector;vector<Output> multiFooSync(vector<Input> inputs) {
vector<Output> outputs;
for (auto input : inputs) {
outputs.push_back(fooSync(input));
}
return outputs;}void multiFooAsync(
vector<Input> inputs,
Callback<vector<Output>> callback){
struct Context {
vector<Output> outputs;
std::mutex lock;
size_t remaining;
};
auto context = std::make_shared<Context>();
context->remaining = inputs.size();
for (auto input : inputs) {
fooAsync(
input,
[=](Output output) {
std::lock_guard<std::mutex> guard(context->lock);
context->outputs->push_back(output);
if (--context->remaining == 0) {
callback(context->outputs);
}
});
}}
非同步的版本要複雜得多。它需要關注很多方面,如設定一個共享的上下文物件、執行緒的安全性以及簿記工作,因此它必須要指定全部的計算在什麼時候完成。更糟糕的是(儘管在這個例子中體現得並不明顯)這使得程式碼執行的次序關係(computation graph)變得複雜,跟蹤執行路徑變得極為困難。程式設計師需要對整個服務的狀態機和這個狀態機接收不同輸入時的不同行為建立一套思維模式,並且當代碼中的某一處不能體現流程時要找到應該去檢查的地方。這種狀況也被親切地稱為“回撥地獄”。
Futures
Future 是一個用來表示非同步計算結果(未必可用)的物件。當計算完成,future 會持有一個值或是一個異常。例如:
#include <folly/futures/Future.h> using folly::Future; // Do foo asynchronously; immediately return a Future for the output Future<Output> fooFuture(Input); Future<Output> f = fooFuture(input); // f may not have a value (or exception) yet. But eventually it will. f.isReady(); // Maybe, maybe not. f.wait(); // You can synchronously wait for futures to become ready. f.isReady(); // Now this is guaranteed to be true. Output o = f.value(); // If f holds an exception, this will throw that exception.
到目前為止,我們還沒有做任何 std::future 不能做的事情。但是 future 模式中的一個強有力的方面就是可以做到連鎖回撥,std::future 目前尚不支援此功能。我們通過方法 Future::then 來表達這個功能:
Future<double> f =
fooFuture(input)
.then([](Output o) {
return o * M_PI;
})
.onError([](std::exception const& e) {
cerr << "Oh bother, " << e.what()
<< ". Returning pi instead." << endl;
return M_PI;
});// get() first waits, and then returns the valuecout << "Result: " << f.get() << endl;
在這裡我們像使用 onError 一樣使用連線起來的 then 去接住可能引發的任何異常。可以將 future 連線起來是一個重要的能力,它允許我們編寫序列和並行的計算,並將它們表達在同一個地方,併為之提供明晰的錯誤處理。
序列功能組成
如果你想要按順序非同步計算 a、b、c 和 d,使用傳統的回撥方式程式設計就會陷入“回撥地獄”- 或者,你使用的語言具備一流的匿名函式(如 C++11),結果可能是“回撥金字塔”:
// the callback pyramid is syntactically annoying
void asyncA(Output, Callback<OutputA>);
void asyncB(OutputA, Callback<OutputB>);
void asyncC(OutputB, Callback<OutputC>);
void asyncD(OutputC, Callback<OutputD>);
auto result = std::make_shared<double>();
fooAsync(input, [=](Output output) {
// ...
asyncA(output, [=](OutputA outputA) {
// ...
asyncB(outputA, [=](OutputB outputB) {
// ...
asyncC(outputB, [=](OutputC outputC) {
// ...
asyncD(outputC, [=](OutputD outputD) {
*result = outputD * M_PI;
});
});
});
});
});
// As an exercise for the masochistic reader, express the same thing without
// lambdas. The result is called callback hell.
有了 futures,順序地使用then組合它們,程式碼就會變得乾淨整潔:
Future<OutputA> futureA(Output);
Future<OutputB> futureB(OutputA);
Future<OutputC> futureC(OutputB);
// then() automatically lifts values (and exceptions) into a Future.
OutputD d(OutputC) {
if (somethingExceptional) throw anException;
return OutputD();}Future<double> fut =
fooFuture(input)
.then(futureA)
.then(futureB)
.then(futureC)
.then(d)
.then([](OutputD outputD) { // lambdas are ok too
return outputD * M_PI;
});
並行功能組成
再回到我們那個 multiFoo 的例子。下面是它在 future 中的樣子:
using folly::futures::collect;
Future<vector<Output>> multiFooFuture(vector<Input> inputs) {
vector<Future<Output>> futures;
for (auto input : inputs) {
futures.push_back(fooFuture(input));
}
return collect(futures);}
collect 是一種我們提供的構建塊(compositional building block),它以 Future<T> 為輸入並返回一個 Future<vector<T>>,這會在所有的 futures 完成後完成。(collect 的實現依賴於-你猜得到-then)有很多其他的構建塊,包括:collectAny、collectN、map 和 reduce。
請注意這個程式碼為什麼會看上去與同步版本的 multiFooSync 非常相似,我們不需要擔心上下文或執行緒安全的問題。這些問題都由框架解決,它們對我們而言是透明的。
執行上下文
其他一些語言裡的 futures 框架提供了一個執行緒池用於執行回撥函式,你除了要知道上下文在另外一個執行緒中執行,不需要關注任何多餘的細節。但是 C++ 的開發者們傾向於編寫 C++ 程式碼,因為他們需要控制底層細節來實現效能優化,Facebook 也不例外。因此我們使用簡單的 Executor介面提供了一個靈活的機制來明確控制回撥上下文的執行:
struct Executor {
using Func = std::function<void()>;
virtual void add(Func) = 0;};
你可以向 then 函式傳入一個 executor 來命令它的回撥會通過 executor 執行。
a(input).then(executor, b);
在這段程式碼中,b 將會通過 executor 執行,b 可能是一個特定的執行緒、一個執行緒池、或是一些更有趣的東西。本方法的一個常見的用例是將 CPU 從 I/O 執行緒中解放出來,以避免佇列中其他請求的排隊時間。
Futures 意味著你再也不用忘記說對不起
傳統的回撥程式碼有一個普遍的問題,即不易對錯誤或異常情況的呼叫進行跟蹤。程式設計師在檢查錯誤和採取恰當措施上必須做到嚴於律己(即使是超人也要這樣),更不要說當一場被意外丟擲的情況了。Futures 使用包含一個值和一個異常的方式來解決這個問題,這些異常就像你希望的那樣與 futures融合在了一起,除非它留在 future 單元裡直到被 onErorr 接住,或是被同步地,例如,賦值或取值。這使得我們很難(但不是不可能)跟丟一個應該被接住的錯誤。
使用 Promise
我們已經大致看過了 futures 的使用方法,下面來說說我們該如何製作它們。如果你需要將一個值傳入到 Future,使用 makeFuture:
using folly::makeFuture;
std::runtime_error greatScott("Great Scott!");
Future<double> future = makeFuture(1.21e9);
Future<double> future = makeFuture<double>(greatScott);
但如果你要包裝一個非同步操作,你需要使用 Promise:
using folly::Promise; Promise<double> promise; Future<double> future = promise.getFuture();
當你準備好為 promise 賦值的時候,使用 setValue、setException 或是 setWith:
promise.setValue(1.21e9);
promise.setException(greatScott);
promise.setWith([]{
if (year == 1955 || year == 1885) throw greatScott;
return 1.21e9;
});
總之,我們通過生成另一個執行緒,將一個長期執行的同步操作轉換為非同步操作,如下面程式碼所示:
double getEnergySync(int year) {
auto reactor = ReactorFactory::getReactor(year);
if (!reactor) // It must be 1955 or 1885
throw greatScott;
return reactor->getGigawatts(1.21);
}
Future<double> getEnergy(int year) {
auto promise = make_shared<Promise<double>>();
std::thread([=]{
promise->setWith(std::bind(getEnergySync, year));
}).detach();
return promise->getFuture();
}
通常你不需要 promise,即使乍一看這像是你做的。舉例來說,如果你的執行緒池中已經有了一個 executor 或是可以很輕易地獲取它,那麼這樣做會更簡單:
Future<double> future = folly::via(executor, std::bind(getEnergySync, year));
用例學習
我們提供了兩個案例來解釋如何在 Facebook 和 Instagram 中使用 future 來改善延遲、魯棒性與程式碼的可讀性。
Instagram 使用 futures 將他們推薦服務的基礎結構由同步轉換為非同步,以此改善他們的系統。其結果是尾延遲(tail latency)得以顯著下降,並僅用十分之一不到的伺服器就實現了相同的吞吐量。他們把這些改動及相關改動帶來的益處進行了記錄,更多細節可以參考他們的部落格。
下一個案例是一個真正的服務,它是 Facebook 新聞遞送(News Feed)的一個組成部分。這個服務有一個兩階段的葉聚合模式(leaf-aggregate pattern),請求(request)會被分解成多個葉請求將碎片分配到不同的葉伺服器,我們在做同樣的事情,但根據第一次聚合的結果分配的碎片會變得不同。最終,我們獲取兩組結果集並將它們簡化為一個單一的響應(response)。

下面是相關程式碼的簡化版本:
Future<vector<LeafResponse>> fanout(
const map<Leaf, LeafReq>& leafToReqMap,
chrono::milliseconds timeout)
{
vector<Future<LeafResponse>> leafFutures;
for (const auto& kv : leafToReqMap) {
const auto& leaf = kv.first;
const auto& leafReq = kv.second;
leafFutures.push_back(
// Get the client for this leaf and do the async RPC
getClient(leaf)->futureLeafRPC(leafReq)
// If the request times out, use an empty response and move on.
.onTimeout(timeout, [=] { return LeafResponse(); })
// If there's an error (e.g. RPC exception),
// use an empty response and move on.
.onError([=](const exception& e) { return LeafResponse(); }));
}
// Collect all the individual leaf requests into one Future
return collect(leafFutures);
}
// Some sharding function; possibly dependent on previous responses.
map<Leaf, LeafReq> buildLeafToReqMap(
const Request& request,
const vector<LeafResponse>& responses);
// This function assembles our final response.
Response assembleResponse(
const Request& request,
const vector<LeafResponse>& firstFanoutResponses,
const vector<LeafResponse>& secondFanoutResponses);
Future<Response> twoStageFanout(shared_ptr<Request> request) {
// Stage 1: first fanout
return fanout(buildLeafToReqMap(*request, {}),
FIRST_FANOUT_TIMEOUT_MS)
// Stage 2: With the first fanout completed, initiate the second fanout.
.then([=](vector<LeafResponse>& responses) {
auto firstFanoutResponses =
std::make_shared<vector<LeafResponse>>(std::move(responses));
// This time, sharding is dependent on the first fanout.
return fanout(buildLeafToReqMap(*request, *firstFanoutResponses),
SECOND_FANOUT_TIMEOUT_MS)
// Stage 3: Assemble and return the final response.
.then([=](const vector<LeafResponse>& secondFanoutResponses) {
return assembleResponse(*request, *firstFanoutResponses, secondFanoutResponses);
});
});
}
該服務的歷史版本中曾使用只允許整體超時的非同步框架,同時使用了傳統的“回撥地獄”模式。是 Futures 讓這個服務自然地表達了非同步計算,並使用有粒度的超時以便在某些部分執行過慢時採取更積極的行動。其結果是,服務的平均延遲減少了三分之二,尾延遲減少到原來的十分之一,總體超時錯誤明顯減少。程式碼變得更加易讀和推理,作為結果,程式碼還變得更易維護。
當開發人員擁有了幫助他們更好理解和表達非同步操作的工具時,他們可以寫出更易於維護的低延遲服務。
結論
Folly Futures 為 C++11 帶來了健壯的、強大的、高效能的 futures。我們希望你會喜歡上它(就像我們一樣)。如果你想了解更多資訊,可以查閱相關文件、文件塊以及 GitHub 上的程式碼。
致謝
Folly Futures 製作團隊的成員包括 Hans Fugal,Dave Watson,James Sedgwick,Hannes Roth 和 Blake Mantheny,還有許多其他志同道合的貢獻者。我們要感謝 Twitter,特別是 Marius,他在 Facebook 關於 Finagle 和 Futures 的技術講座,激發了這個專案的創作靈感。