
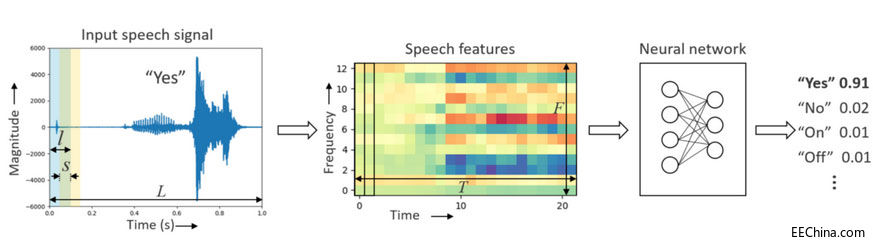
如何在Cortex-M處理器上實現高精度關鍵詞識別
我們可以對神經網路架構進行優化,使之適配微控制器的記憶體和計算限制範圍,並且不會影響精度。我們將在本文中解釋和探討深度可分離卷積神經網路在 Cortex-M 處理器上實現關鍵詞識別的潛力。
關鍵詞識別 (KWS) 對於在智慧裝置上實現基於語音的使用者互動十分關鍵,需要實時響應和高精度,才能確保良好的使用者體驗。最近,神經網路已經成為 KWS 架構的熱門選擇,因為與傳統的語音處理演算法相比,神經網路的精度更勝一籌。
由於要保持“永遠線上”,KWS 應用的功耗預算受到很大限制。雖然 KWS 應用也可在專用 DSP 或高效能 CPU 上執行,但更適合在 Arm Cortex-M 微控制器上執行,有助於最大限度地降低成本,Arm
但是,要在基於 Cortex-M 的微控制器上部署基於神經網路的 KWS,我們面臨著以下挑戰:
1. 有限的記憶體空間
典型的 Cortex-M 系統最多提供幾百 KB 的可用記憶體。這意味著,整個神經網路模型,包括輸入/輸出、權重和啟用,都必須在這個很小的記憶體範圍內執行。
2. 有限的計算資源
由於 KWS 要保持永遠線上,這種實時性要求限制了每次神經網路推理的總運算數量。
以下是適用於 KWS 推理的典型神經網路架構:
• 深度神經網路 (DNN)
DNN 是標準的前饋神經網路,由全連線層和非線性啟用層堆疊而成。
•卷積神經網路 (CNN)
基於 DNN 的 KWS 的一大主要缺陷是無法為語音功能中的局域關聯性、時域關聯性、頻域關聯性建模。CNN 則可將輸入時域和頻域特徵當作影象處理,並且在上面執行 2D 卷積運算,從而發現這種關聯性。
• 迴圈神經網路 (RNN)
RNN 在很多序列建模任務中都展現出了出色的效能,特別是在語音識別、語言建模和翻譯中。RNN 不僅能夠發現輸入訊號之間的時域關係,還能使用“門控”機制來捕捉長時依賴關係。
•卷積迴圈神經網路 (CRNN)
卷積迴圈神經網路是 CNN 和 RNN 的混合,可發現區域性時間/空間關聯性。CRNN 模型從卷積層開始,然後是 RNN,對訊號進行編碼,接下來是密集全連線層。
• 深度可分離卷積神經網路 (DS-CNN)
最近,深度可分離卷積神經網路被推薦為標準 3D 卷積運算的高效替代方案,並已用於實現計算機視覺的緊湊網路架構。
DS-CNN 首先使用獨立的 2D 濾波,對輸入特徵圖中的每個通道進行卷積計算,然後使用點態卷積(即 1x1),合併縱深維度中的輸出。通過將標準 3D 卷積分解為 2D和後續的 1D,引數和運算的數量得以減少,從而使得更深和更寬的架構成為可能,甚至在資源受限的微控制器器件中也能執行、
在 Cortex-M 處理器上執行關鍵詞識別時,記憶體佔用和執行時間是兩個最重要因素,在設計和優化用於該用途的神經網路時,應該考慮到這兩大因素。以下所示的神經網路的三組限制分別針對小型、中型和大型 Cortex-M 系統,基於典型的 Cortex-M 系統配置

KWS 模型的神經網路類別 (NN) 類別,假定每秒 10 次推理和 8 位權重/啟用
要調節模型,使之不超出微控制器的記憶體和計算限制範圍,必須執行超引數搜尋。下表顯示了神經網路架構及必須優化的相應超引數。
神經網路超引數搜尋空間
首先執行特徵提取和神經網路模型超引數的窮舉搜尋,然後執行手動選擇以縮小搜尋空間,這兩者反覆執行。下圖總結了適用於每種神經網路架構的最佳效能模型及相應的記憶體要求和運算。DS-CNN 架構提供最高的精度,而且需要的記憶體和計算資源也低得多。
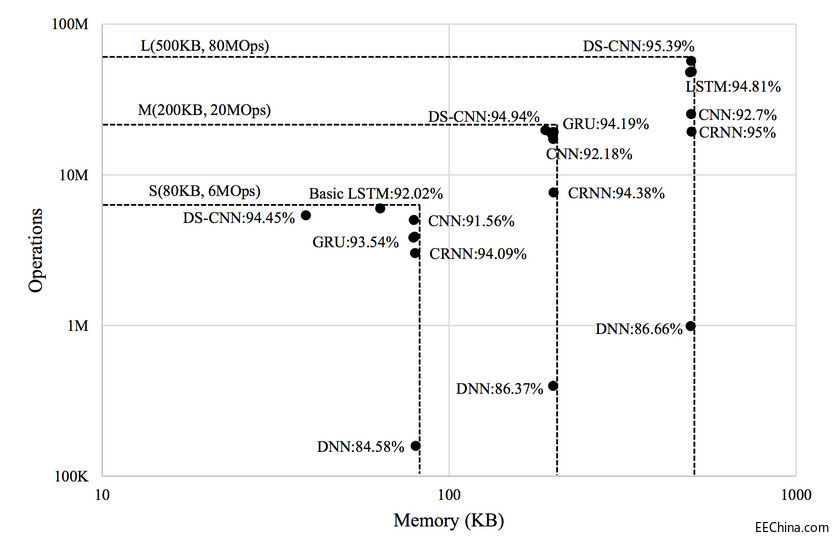
最佳神經網路模型中記憶體與運算/推理的關係
KWS 應用部署在基於 Cortex-M7 的 STM32F746G-DISCO 開發板上(如下圖所示),使用包含 8 位權重和 8 位啟用的 DNN 模型,KWS 在執行時每秒執行 10 次推理。每次推理(包括記憶體複製、MFCC 特徵提取、DNN 執行)花費大約 12 毫秒。為了節省功耗,可讓微控制器在餘下時間處於等待中斷 (WFI) 模式。整個 KWS 應用佔用大約 70 KB 記憶體,包括大約 66 KB 用於權重、大約 1 KB 用於啟用、大約 2 KB 用於音訊 I/O 和 MFCC 特徵。
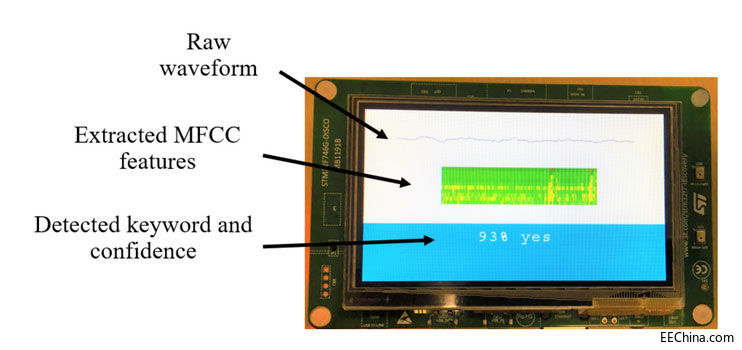
Cortex-M7 開發板上的 KWS 部署
總而言之,Arm Cortex-M 處理器可以在關鍵詞識別應用中達到很高的精度,同時通過調整網路架構來限制記憶體和計算需求。DS-CNN 架構提供最高的精度,而且需要的記憶體和計算資源也低得多。
程式碼、模型定義和預訓練模型可從 github.com/ARM-software 獲取。