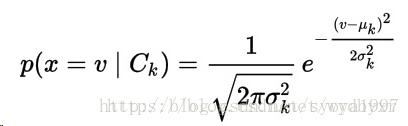樸素貝葉斯(Naive Bayes)分類和Gaussian naive Bayes
樸素貝葉斯(Naive Bayes)
參考資料:https://www.cnblogs.com/pinard/p/6069267.html 樸素貝葉斯最關鍵的就是 (強制認為每種指標都是獨立的)。 不同於其它分類器,樸素貝葉斯是一種基於概率理論的分類演算法;總體上來說,樸素貝葉斯原理和實現都比較簡單,學習和預測的效率都很高,是一種經典而常用的分類演算法。樸素貝葉斯分類是貝葉斯分類中最簡單,也是常見的一種分類方法。其中 naive(樸素)是指的對於模型中各個 feature(特徵) 有強獨立性的假設,並未將 feature 間的相關性納入考慮中。
基本概念
樸素貝葉斯分類器基於一個簡單的假定:給定目標值時屬性之間相互條件獨立。 樸素貝葉斯是生成方法,也就是直接找出特徵輸出Y和特徵X的聯合分佈P(X,Y)P(X,Y),然後用P(Y|X)=P(X,Y)/P(X)P(Y|X)=P(X,Y)/P(X)得出。
優點
1) 演算法邏輯簡單,易於實現(演算法思路很簡單,只要使用貝葉斯公式轉化醫學即可!) 2)分類過程中時空開銷小(假設特徵相互獨立,只會涉及到二維儲存),樸素貝葉斯很快。
缺點:
樸素貝葉斯模型假設屬性之間相互獨立,這個假設在實際應用中往往是不成立的,在屬性個數比較多或者屬性之間相關性較大時,分類效果不好。 而在屬性相關性較小時,樸素貝葉斯效能最為良好。對於這一點,有半樸素貝葉斯之類的演算法通過考慮部分關聯性適度改進。
具體使用
1)特徵之間的條件獨立性假設,顯然這種假設顯得“粗魯”而不符合實際,這也是名稱中“樸素”的由來。然而事實證明,樸素貝葉斯在有些領域很有用,比如垃圾郵件過濾; 2)在具體的演算法實施中,要考慮很多實際問題。比如因為“下溢”問題,需要對概率乘積取對數;再比如詞集模型和詞袋模型,還有停用詞和無意義的高頻詞的剔除,以及大量的資料預處理問題,等等;"
應用
1)多類預測:這個演算法以多類別預測功能聞名,因此可以用來預測多類目標變數的概率。 2)文字分類/垃圾郵件過濾/情感分析:相比較其他演算法,樸素貝葉斯的應用主要集中在文字分類(變數型別多,且更獨立),具有較高的成功率。因此被廣泛應用於垃圾郵件過濾(識別垃圾郵件)和情感分析(在社交媒體平臺分辨積極情緒和消極情緒的使用者)。 3)推薦系統:樸素貝葉斯分類器和協同過濾結合使用可以過濾出使用者想看到的和不想看到的東西。
Gaussian naive Bayes(高斯樸素貝葉斯)
處理連續資料的時候,一個比較典型的假設是與每個分類相關的連續值是按照高斯分佈分佈的。
公式