
資料分析 第七篇:相關分析
相關分析是資料分析的一個基本方法,可以用於發現不同變數之間的關聯性,關聯是指資料之間變化的相似性,這可以通過相關係數來描述。發現相關性可以幫助你預測未來,而發現因果關係意味著你可以改變世界。
一,協方差和相關係數
如果隨機變數X和Y是相互獨立的,那麼協方差
Cov(X,Y) = E{ [X-E(X)] [Y-E(Y)] } = 0,
這意味著當協方差Cov(X,Y) 不等於 0 時,X和Y不相互獨立,而是存在一定的關係,此時,稱作X和Y相關。在統計學上,使用協方差和相關係數來描述隨機變數X和Y的相關性:
協方差:如果兩個變數的變化趨勢一致,也就是說如果其中一個大於自身的期望值,另外一個也大於自身的期望值,那麼兩個變數之間的協方差就是正值。 如果兩個變數的變化趨勢相反,即其中一個大於自身的期望值,另外一個卻小於自身的期望值,那麼兩個變數之間的協方差就是負值。從數值來看,協方差的數值越大,兩個變數同向程度也就越大。
![]() ,µ是變數的期望。
,µ是變數的期望。
相關係數:相關係數消除了兩個變數變化幅度的影響,只是單純反應兩個變數每單位變化時的相似程度。
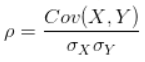 ,δ是變數的標準差。
,δ是變數的標準差。
相關係數用於描述定量變數之間的關係,相關係數的符號(+、-)表明關係的方向(正相關、負相關),其值的大小表示關係的強弱程度(完全不相關時為0,完全相關時為1)。
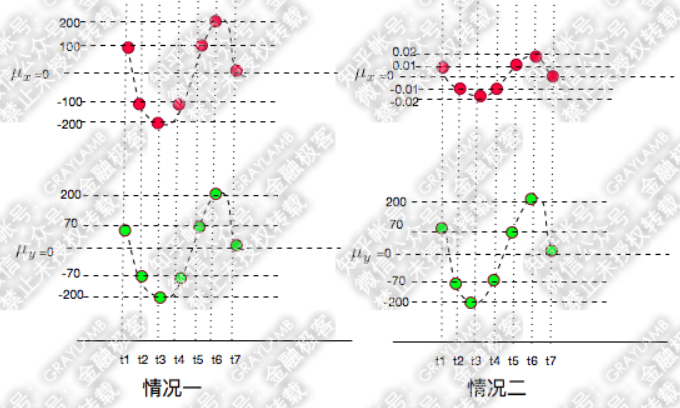
例如,下面兩種情況中,很容易看出X和Y都是同向變化的,而這個“同向變化”有個非常顯著特徵:X、Y同向變化的過程,具有極高的相似度。
1,觀察協方差,情況一的協方差是:
![]()
情況二的協方差是:
![]()
協方差的數值相差一萬倍,只能從兩個協方差都是正數判斷出在這兩種情況下X、Y都是同向變化,但是一點也看不出兩種情況下X、Y的變化都具有相似性這一特點。
2,觀察相關係數,情況一的相關係數是:
![]()
情況二的相關係數是:
![]()
雖然兩種情況的協方差相差1萬倍,但是,它們的相關係數是相同的,這說明,X的變化與Y的變化具有很高的相似度。
二,相關的型別
R可以計算多種相關係數,包括Pearson相關係數、Spearman相關係數、Kendall相關係數、偏相關係數、多分格(polychoric)相關係數和多系列(polyserial)相關係數。下面讓我們依次理解這些相關係數。
1,Pearson、Spearman和Kendall相關係數
Pearson積差相關係數衡量了兩個定量變數之間的線性相關程度,Spearman等級相關係數則衡量分級定序變數之間的相關程度,Kendall相關係數也是一種非引數的等級相關度量。cor()函式可以計算這三種相關係數,而cov()函式可以計算協方差。
cor(x, y = NULL, use = "everything", method = c("pearson", "kendall", "spearman")) cov(x, y = NULL, use = "everything", method = c("pearson", "kendall", "spearman"))
引數註釋:
- x:矩陣或資料框
- y:預設情況下,y=NULL表示y=x,也就是說,所有變數之間兩兩計算相關,也可以指定其他的矩陣或資料框,使得x和y的變數之間兩兩計算相關。
- use:指定缺失資料的處理方式,可選的方式為all.obs(遇到缺失資料時報錯)、everything(遇到缺失資料時,把相關係數的計算結果設定為missing)、complete.obs(行刪除)以及pairwise.complete.obs(成對刪除)
- method:指定相關係數的型別,可選型別為"pearson", "kendall", "spearman"
例如,使用R基礎安裝包中的state.x77資料集,它提供了美國50個州的人口、收入、文盲率(Illiteracy)、預期壽命(Life Exp)、謀殺率和高中畢業率(HS Grad)等資料。
states <- state.x77[,1:6] > cor(states) Population Income Illiteracy Life Exp Murder HS Grad Population 1.00000000 0.2082276 0.1076224 -0.06805195 0.3436428 -0.09848975 Income 0.20822756 1.0000000 -0.4370752 0.34025534 -0.2300776 0.61993232 Illiteracy 0.10762237 -0.4370752 1.0000000 -0.58847793 0.7029752 -0.65718861 Life Exp -0.06805195 0.3402553 -0.5884779 1.00000000 -0.7808458 0.58221620 Murder 0.34364275 -0.2300776 0.7029752 -0.78084575 1.0000000 -0.48797102 HS Grad -0.09848975 0.6199323 -0.6571886 0.58221620 -0.4879710 1.00000000
可以看到,收入和高中畢業率之間存在很強的正相關(約0.620),文盲率和謀殺率之間存在很強的正相關(約0.703),文盲率和高中畢業率之間存在很強的負相關(約-0.657),預期壽命和謀殺率之間存在很強的負相關(約-0.781)等。
2,偏相關
偏相關是指在控制一個或多個定量變數(稱作條件變數)時,另外兩個定量變數之間的相關關係。可以使用ggm包中的pcor()函式計算偏相關係數。
pcor(u, S)
引數註釋:
- u:位置向量,前兩個整數表示要計算偏相關係數的變數下標,其餘的整數為條件變數的下標。
- S:是資料集的協方差矩陣,即cov()函式計算的結果
例如:在控制了收入、文盲率和高中畢業率的條件下,計算的人口和謀殺率之間的偏相關係數為0.346:
> library(igraph) > library(ggm) > colnames(states) [1] "Population" "Income" "Illiteracy" "Life Exp" "Murder" "HS Grad" > pcor(c(1,5,2,3,6),cov(states)) [1] 0.3462724
三,相關性的顯著性檢驗
在計算好相關係數之後,需要進行統計顯著性檢驗,常用的原假設是變數間不相關(即總體的相關係數為0),可以使用cor.test()函式對單個的Pearson、Spearman和Kendall相關係數進行顯著性檢驗,以驗證原假設是否成立。
顯著性檢驗返回的結果中,p值(p value)就是當原假設為真時所得到的樣本觀察結果出現的概率。如果p值很小,說明原假設情況的發生的概率很小,而如果出現了,根據小概率原理,我們就有理由拒絕原假設,p值越小,我們拒絕原假設的理由越充分。
小概率原理是指:在統計學中,通常把在現實世界中發生機率小於5%的事件稱之為“不可能事件”,通常把顯著性水平定義為0.05,或0.025。當p值小於顯著性水平時,把原假設視為不可能事件,因為拒絕原假設。
1,cor.test()檢驗
cor.test()每次只能檢驗一種相關關係,原假設是變數間不相關,即總體的相關係數是0。
cor.test(x, y, alternative = c("two.sided", "less", "greater"), method = c("pearson", "kendall", "spearman"), exact = NULL, conf.level = 0.95, continuity = FALSE, ...)
引數註釋:
- alternative:用於指定進行雙側檢驗還是單側檢驗,有效值是 "two.sided", "greater" 和 "less",對於單側檢驗,當總體的相關係數小於0時,使用alternative="less";當總體的相關係數大於0時,使用alternative="greater";預設情況下,alternative="two.side",表示總體相關係數不等於0。
- method:指定計算的相關型別,
- exact:邏輯值,是否計算出精確的p值
- conf.level:檢驗的置信水平
例如,下面的程式碼用於檢驗預期壽命和謀殺率的Pearson相關係數為0的原假設,
> cor.test(states[,3],states[,5]) Pearson's product-moment correlation data: states[, 3] and states[, 5] t = 6.8479, df = 48, p-value = 1.258e-08 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.5279280 0.8207295 sample estimates: cor 0.7029752
檢驗的結果是:p值(p-value=1.258e-08),樣本估計的相關係數cor 是 0.703,這說明:
假設總體的相關度為0,則預計在1千萬次中只會有少於1次的機會見到0.703的樣本相關度,由於這種情況幾乎不可能發生,所以拒絕原假設,即預期壽命和謀殺率之間的總體相關度不為0。
2,corr.test()檢驗
psych包中的corr.test()函式,可以依次為Pearson、Spearman或Kendall計算相關矩陣和顯著性水平。
corr.test(x, y = NULL, use = "pairwise",method="pearson",adjust="holm", alpha=.05,ci=TRUE)
引數註釋:
- use:指定缺失資料的處理方式,預設值是pairwise(成對刪除);complete(行刪除)
- method:計算相關的方法,Pearson(預設值)、Spearman或Kendall
3,偏相關的顯著性檢驗
在多元正態性的假設下,psych包中的pcor.test()函式用於檢驗在控制一個或多個條件變數時,兩個變數之間的獨立性。
pcor.test(r, q, n)
引數註釋:
- r:是由pcor()函式計算得到的偏相關係數
- q:要控制的變數(以位置向量表示)
- n:樣本大小
參考文件: