
CUDA 核函式執行引數
CUDA核函式執行引數
呼叫定義的和函式時採用類似於下面的形式:
kernel<<<1,1>>>(param1,param2,...)“<<< >>>”中引數的作用是告訴我們該如何啟動核函式(比如如何設定執行緒)。 下面我們先直接介紹引數概念,然後詳細說明其意義。
1. 核函式執行引數
當我們使用 gloabl 宣告核函式後:
__global__ void kernel(param list){ }在主機端(Host)呼叫時採用如下的形式:
kernel<<<Dg,Db, Ns, S>>>(param list);
引數解釋:
- Dg: int型或者dim3型別(x,y,z)。 用於定義一個grid中的block是如何組織的。 int型則直接表示為1維組織結構。
- Db: int型或者dim3型別(x,y,z)。 用於定義一個block中的thread是如何組織的。 int型則直接表示為1維組織結構。
- Ns: size_t型別,可預設,預設為0。 用於設定每個block除了靜態分配的共享記憶體外,最多能動態分配的共享記憶體大小,單位為byte。 0表示不需要動態分配。
- S: cudaStream_t型別,可預設,預設為0。 表示該核函式位於哪個流。
2. 執行緒結構
關於CUDA的執行緒結構,有著三個重要的概念: Grid
- GPU工作時的最小單位是 thread。
- 多個 thread 可以組成一個 block,但每一個 block 所能包含的 thread 數目是有限的。因為一個block的所有執行緒最好應當位於同一個處理器核心上,同時共享同一塊記憶體。 於是一個 block中的所有thread可以快速進行同步的動作而不用擔心資料通訊壁壘。
- 執行相同程式的多個 block,可以組成 grid。 不同 block 中的 thread 無法存取同一塊共享的記憶體,無法直接互通或進行同步。因此,不同 block 中的 thread 能合作的程度是比較低的。不過,利用這個模式,可以讓程式不用擔心顯示晶片實際上能同時執行的 thread 數目限制。例如,一個具有很少量執行單元的顯示晶片,可能會把各個 block 中的 thread 順序執行,而非同時執行。不同的 grid 則可以執行不同的程式(即 kernel)。
下圖是一個結構關係圖:

此外,Block, Thread的組織結構可以是可以是一維,二維或者三維。以上圖為例,Block, Thread的結構分別為二維和三維。
CUDA中每一個執行緒都有一個唯一標識ThreadIdx,這個ID隨著組織結構形式的變化而變化。 (注意:ID的計算,同計算行優先排列的矩陣元素ID思路一樣。)
回顧之前我們的向量加法:
Block是一維的,Tread是二維的:
// Block是一維的,Thread也是一維的
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = blockIdx.x *blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
Block是一維的,Tread是二維的:
// Block是一維的,Thread是二維的
__global__ void addKernel(int *c, int *a, int *b)
{
int i = blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
Block是二維的,Tread是三維的:
// Block是二維的,Thread是三維的
__global__ void addKernel(int *c, int *a, int *b)
{
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int i = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
c[i] = a[i] + b[i];
}
下表是不同計算能力的GPU的技術指標(更多可參見 CUDA Toolkit Documentation)

也可以通過下面的程式碼來直接查詢自己GPU的具體指標:
#include "cuda_runtime.h"
#include <iostream>
int main()
{
cudaError_t cudaStatus;
// 初獲取裝置數量
int num = 0;
cudaStatus = cudaGetDeviceCount(&num);
std::cout << "Number of GPU: " << num << std::endl;
// 獲取GPU裝置屬性
cudaDeviceProp prop;
if (num > 0)
{
cudaGetDeviceProperties(&prop, 0);
// 列印裝置名稱
std::cout << "Device: " <<prop.name << std::endl;
}
system("pause");
return 0;
}
其中 cudaDeviceProp是一個定義在driver_types.h中的結構體。
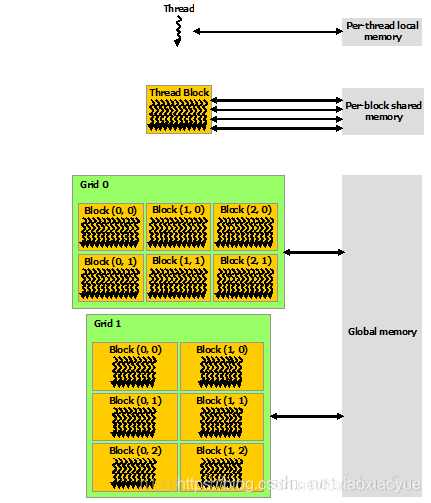
3. 記憶體結構
如下圖所示,每個 thread 都有自己的一份 register 和 local memory 的空間。同一個 block 中的每個 thread 則有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 則有各自的 global memory、constant memory 和 texture memory。
這種特殊的記憶體結構直接影響著我們的執行緒分配策略,因為需要通盤考慮資源限制及利用率。 這些後續再進行討論。
4. 異構程式設計
如下圖所示,是常見的GPU程式的處理流程,其實是一種異構程式,即CPU和GPU的協同。
主機上執行序列程式碼,裝置上則執行並行程式碼。

參考資料:
https://blog.csdn.net/shuzfan/article/details/76679378
https://blog.csdn.net/canhui_wang/article/details/51730264