
英特爾® 高階向量擴充套件(AVX)指令集簡介
來源:https://software.intel.com/zh-cn/articles/introduction-to-intel-advanced-vector-extensions
作者:Chris Lomont
下載文章
下載 英特爾® 高階向量擴充套件指令集簡介 [PDF 1.4MB]
英特爾® 高階向量擴充套件指令集(英特爾® AVX)是在英特爾® 架構 CPU 上執行單指令多資料 (SIMD) 運算的指令集。這些指令添加了以下特性,對之前的 SIMD 產品——MMX™ 指令和英特爾® 資料流單指令多資料擴充套件指令集(英特爾® SSE)進行了擴充套件:
- 將 128 位 SIMD 暫存器擴充套件至 256 位。英特爾® AVX 的目標是在未來可以支援 512 或 1024 位。
- 添加了 3 運算元非破壞性運算。之前在 A = A + B 類運算中執行的是 2 運算元指令,它將覆蓋源運算元,而新的運算元可以執行 A = B + C 類運算,且保持原始源運算元不變。.
- 少數幾個指令採用 4 暫存器運算元,通過移除不必要的指令,支援更小、更快的程式碼。
- 對於運算元的記憶體對齊要求有所放寬。
- 新的擴充套件編碼方案 (VEX) 旨在使得以後新增更加容易以及所執行的指令編碼更小、速度更快。
與這些改進密切相關的是新的融合乘加 (FMA) 指令,它可以更快、更精確地執行專門運算,例如單指令 A = A * B + C。第二代英特爾® 酷睿™ CPU 中將可提供 FMA 指令。其他特性還包括處理高階加密標準 (AES) 加密和解密的指令、用於某些加密基元的緊縮 carry-less 乘法運算 (PCLMULQDQ) 以及某些用於未來指令的預留槽,如硬體隨機數生成器。
指令集概述
新指令使用英特爾的 VEX prefix 進行編碼,VEX prefix 是一個 2個或 3 個位元組的字首,旨在降低當前和未來 x86/x64 指令編碼的複雜性。兩個新的 VEX prefix 形成於兩個過時的 32 位指令——使用 DS 的 Load Pointer(LDS-0xC4,3 位元組形式)和使用 ES 的 Load Pointer(LES-0xC5, 2 位元組形式),它們以 32 位模式載入 DS 和 ES 段暫存器。在 64 位模式中,操作碼 LDS 和 LES 生成一個無效操作碼異常,但是在英特爾® AVX 下,這些操作碼可另外用作編碼新指令字首。最終,VEX 指令只能在 64 位模式中執行時使用。字首可比之前的 x86 指令編碼更多的暫存器,可用於訪問新的 256 位 SIMD 暫存器或者使用 3 和 4 運算元語法。作為使用者,您無需擔心這個問題(除非您正在編寫彙編器或反彙編器)。
注:下文假定運算都是在 64 位模式中進行。
SIMD 指令可以在一個單一步驟中處理多個片段的資料,加速許多工的吞吐量,包括視訊編解碼、影象處理、資料分析和物理模擬。在 32 位長度(稱之為單精度)和64 位長度(稱之為雙精度)中,英特爾® AVX 指令在IEEE-754浮點值上執行。IEEE-754 是一個標準定義的、可複製的強大浮點運算,是大多數主流數字計算的標準。
較早的相關英特爾® SSE 指令還支援各種帶符號和無符號整數大小,包括帶符號和無符號位元組(B,8 位)、字(W,16 位)、雙字(DW,32 位)、四字(QW,64 位)和雙四字(DQ,128 位)長度。並非所有指令都適用於所有大小組合,更多詳細資訊,敬請參閱“更多資訊”中提供的連結。請參閱本文後文中的圖 2,瞭解資料型別的圖形表示法。
暫存器
支援英特爾® AVX(和 FMA)的硬體包括 16 個 256 位 YMM 暫存器 YMM0-YMM15 和一個名為 MXCSR的 32 位控制/狀態暫存器。YMM 暫存器替代了英特爾® SSE 使用的較早的 128 位 XMM 暫存器,它將 XMM 暫存器視作相應 YMM 暫存器的下層部分,如圖 1 所示。

圖 1. XMM 暫存器覆蓋 YMM 暫存器。
MXCSR 的 0-5 位顯示設定“粘滯”位後 SIMD 浮點異常,除非使用位LDMXCSR 或 FXRSTOR清除,否則它們將一直保持設定。設定時 7-12 位遮蔽個體異常,可通過啟動進行初始設定或重置。0-5 位分別顯示為無效運算、非法、被零除、溢位和精度。如欲獲取詳細資訊,請參閱“更多資訊”部分提供的連結。
資料型別
圖 2 顯示了英特爾® SSE 和英特爾® AVX 指令中使用的資料型別。對於英特爾® AVX,允許使用增加至 128 或 256 位的 32 位或 64 位浮點型別的倍數以及增加至 128 位的任意整數型別的倍數。

圖 2.英特爾® AVX 和英特爾® SSE 資料型別
向量指令和標量指令
指令通常分為標量版本和向量版本,如圖 3 所示。向量版本通過將資料以並行“SIMD”模式在暫存器中處理進行運算;而標量版本則只在每個暫存器的一個條目中進行運算。這一區別減少了某些演算法中的資料移動,提供了更加出色的整體吞吐量。
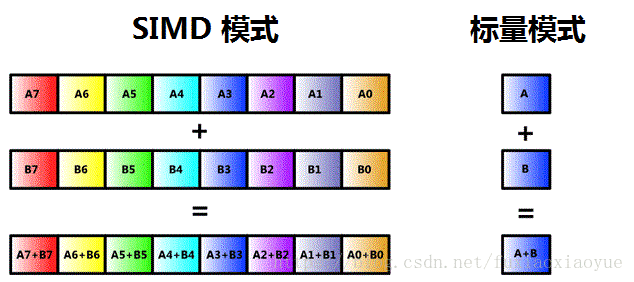
圖 3. SIMD 與標量運算
AVX 放寬了某些記憶體對齊要求
當資料以 n 位元組記憶體界限上儲存的 n 位元組塊進行運算時,資料為記憶體對齊資料。例如,將 256 位資料載入至 YMM 暫存器中時,如果資料來源為 256 位對齊,則資料被稱為“對齊”.
對於英特爾® SSE 運算,除非明確規定,否則都需要記憶體對齊。例如,在英特爾® SSE 下,有針對記憶體對齊和記憶體未對齊運算的特定指令,如MOVAPD(移動對齊的緊縮雙精度值)和 MOVUPD(移動非對齊的緊縮雙精度值)指令。沒有像這樣分為兩個的指令需要執行對齊訪問。
英特爾® AVX 已經放寬了某些記憶體對齊要求,因此預設情況下,英特爾® AVX 允許未對齊的訪問;但是,這樣的訪問將導致效能下降,因此旨在要求資料保持記憶體對齊的原規則仍然是不錯的選擇(面向 128 位訪問的 16 位對齊和面向 256 位訪問的 32 位對齊)。主要例外是明確指出需要記憶體對齊資料的 SSE 指令的VEX 擴充套件版本:這些指令仍然要求使用對齊的資料。其他要求對齊訪問的特定指令請參閱英特爾® 高階向量擴充套件指令集程式設計指南中的表2.4(請參閱“更多資訊”中提供的連結)。
混合使用VEX/非 VEX 指令
除了未對齊資料問題外,另外一個性能問題是混合使用舊的僅 XMM 的指令和較新的英特爾® AVX 指令會導致延遲,因此需要最大限度地控制 VEX 編碼指令和舊的英特爾® SSE 程式碼之間的轉換。也就是說,不要將 VEX 字首的指令和非 VEX 字首的指令混合使用,以實現最佳吞吐量。如果您非要這麼做,請對同一 VEX/非 VEX 級別的指令進行分組,最大限度地控制二者之間的轉換。此外,如果上層 YMM 位通過 VZEROUPPER 或 VZEROALL 設定為零(編譯器應自動插入),則無轉換損失。該插入要求另外一個指令,因此推薦使用分析 (profiling)。
英特爾® AVX 指令類
如上所述,英特爾® AVX 增加了對許多新指令的支援並將當前的英特爾® SSE 指令擴充套件至新的 256 位暫存器,大部分舊的英特爾® SSE 指令都具有一個 V 字首的英特爾® AVX 版本,以訪問新的暫存器容量和 3 運算元形式。根據指令的計算方式,新英特爾® AVX 指令的數量多達幾百個。
例如,舊的 2 運算元英特爾® SSE 指令ADDPS xmm1、xmm2/m128 現在可以使用 VADDPS ymm1、ymm2、ymm3/m256 形式以 3 運算元語法表示為 VADDPS xmm1、xmm2、xmm3/m128 或者 256 位暫存器。少數指令還支援 4 運算元,例如 VBLENDVPS ymm1、ymm2、ymm3/m256、ymm4 ,在一定條件下在 ymm4 中根據掩碼將單精度浮點值由 ymm2 或 ymm3/m256 複製到 ymm1 。這是在之前的形式上進行了改進,其中 xmm0 為隱式需求,要求編譯器解放 xmm0 。現在所有暫存器都明確可見,暫存器的分配有了更大的自由度。此處, m128 是一個 128 位記憶體位置, xmm1 是一個 128 位暫存器,以此類推。
有些新指令僅限 VEX(非英特爾® SSE 擴充套件指令),包括許多將資料移進或移出 YMM 暫存器的方法。以 VBROADCASTS[S/D] 為例,它將一個單一值載入至 XMM 或 YMM 暫存器的所有元素中,並提供了多種使用 VPERMILP[S/D] 將資料移至一個暫存器的方法。(方括號中的內容請參閱附錄 A。)
英特爾® AVX 添加了演算法指令,以使變數對單精度和雙精度緊縮和標量浮點資料進行加、減、乘、除、平方根、比較、最小值、最大值和約數的運算。許多新的條件判定對於 128 位英特爾® SSE 也非常有用,提供了32 種比較型別。英特爾® AVX 還包括從之前的SIMD 中獲得的指令,包括邏輯、混合、轉換、測試、緊縮、解緊縮、移動、載入和儲存。工具集還添加了新指令,包括非跳躍式獲取(將單資料或多資料傳播至 256 位目標,遮蔽移動基元進行有條件的載入和儲存)、向 256 位 SIMD 暫存器中插入多 SIMD 資料或者從中提取多 SIMD 資料、在一個暫存器內轉換基元進行資料處理、分支處理以及緊縮測試指令。
未來新增
英特爾® AVX 手冊還列出了某些未來可能會使用到的指令,此處並未完全列出,有待補充。此處並不確保這些指令都如編寫的那樣可以實現。
預留兩個指令(VCVTPH2PS 和 VCVTPS2PH ),用於支援 16 位浮點轉換為單和雙浮點型別或者從中轉換。16 位格式稱之為半精度,具有一個 10 位尾數(非反向規格化數有一個隱含的以 1 開頭的數,導致 11 位精度)、5 位指數(偏差 15)和 1 位符號。
擬定的 RDRAND 指令使用一個具有密碼的安全硬體數字隨機位生成器,為 16 位、32 位和 64 位暫存器生成隨機數。成功後,進位標識被設定為 1 (CF=1 )。如果沒有足夠的熵值可用,進位標識將被清除 (CF=0 )。
最後,有四個指令(RDFDBASE、RDGSBASE、WRFSBASE 和 WRGSBASE)可在 64 位模式中以全部許可權等級讀取和寫入 FS 和 GS 暫存器。
另外,以後還會新增 FMA 指令,執行類似 A = + A * B + C 的運算,右側的加號 (+) 都可以變更為減號 (?),而且右側的三個運算元順序可以隨意發生變化。還有交叉加法和減法形式。緊縮 FMA 指令可以執行具有 256 位向量的 8 個單精度 FMA 運算或者 4 個雙精度 FMA 運算。
A = A * B + C 這類的 FMA 運算要優於每次執行一個步驟,因為中間結果被視為無限精度,會在儲存上執行約數計算,因此計算更為精確。這一單個約數是為“融合”字首提供的。它們也比按步驟執行運算的速度要快。
每個指令對於運算元 A、B 和 C 都有三種形式的順序,每個順序對應一個 3 位擴充套件:形式 132 執行 A = AC + B,形式 213 執行 A = BA + C,形式 231 執行 A = BC + A。順序數僅代表表示式右側運算元的順序。
可用性與支援
在硬體中檢測英特爾® AVX 特性的可用性需要使用 CPUID 指令在 CPU 和作業系統中查詢支援,稍後會做詳細說明。2011 年第一季度推出的第二代英特爾® 酷睿™ 處理器(代號為 Sandy Bridge 的英特爾® 微架構)是英特爾首款支援英特爾® AVX 技術的處理器。這些處理器沒有新的 FMA 指令。為了能夠在沒有硬體支援的情況下進行開發和測試,免費的英特爾® 軟體開發模擬器(請參閱“更多資訊”中提供的連結)提供了對這些特性的支援,包括英特爾® AVX、FMA、PCLMULQDQ 和 AES 指令。
為了能夠在大多數設定中可靠地使用英特爾® AVX 擴充套件指令集,作業系統必須支援線上程環境切換中儲存和載入新的暫存器(採用 XSAVE/XRSTOR),以預防資料損壞。為了避免出現此類錯誤,從支援英特爾® AVX 感知環境切換的作業系統明確地設定一個 CPU 位,以支援新的指令;否則,在使用英特爾® AVX 指令時,會生成一個未定義的操作碼 (#UD) 異常。
帶有 Service Pack 1 (SP1) 的 Microsoft Windows* 7 和帶有 SP1 的 Microsoft Windows* Server 2008 R2(32 位和 64 位版本)以及更高版本的 Windows* 都支援英特爾® AVX 線上程和程序切換中進行儲存和恢復。Linux* 核心 2.6.30(2009 年6 月)及更高版本也支援英特爾® AVX。
檢測可用性與支援
對英特爾® AVX、FMA、AES 和 PCLMULQDQ 四個領域進行支援檢測的步驟是類似的,都包括檢查相應特性的硬體和作業系統支援(請參閱表 1)。包括以下步驟(計算位是從位 0 開始):
- 使用
CPUID.1:ECX.OSXSAVE bit 27 = 1確認作業系統支援XGETBV。 - 同時,確認支援
CPUID.1:ECX bit 28=1(支援英特爾® AVX)和/或bit 25=1(支援 AES)和/或bit 12=1(支援 FMA)和/或bit 1=1(PCLMULQDQ)。 - 發出
XGETBV,並驗證在位 1 和位 2 處特性支援的掩碼是 11b(作業系統支援 XMM 狀態和 YMM 狀態)
表 1.特性檢測掩碼
| Feature |
Bits to check | Constant |
|---|---|---|
| 英特爾® AVX | 28,、27 | 018000000H |
| VAES | 28,、27, and 25 | 01A000000H |
| VPCLMULQDQ | 28、 27, and 1 | 018000002H |
| FMA | 28,、27, and 12 | 018001000H |
條目 1 中提供了實施該程序的樣例程式碼,其中 CONSTANT 是表 1 中的值。稍後將提供 Microsoft* Visual Studio* C++ 行內函數版本。
條目 1.特性檢測
INT Supports_Feature()
{
; result returned in eax
mov eax, 1
cpuid
and ecx, CONSTANT
cmp ecx, CONSTANT; check desired feature flags
jne not_supported
; processor supports features
mov ecx, 0; specify 0 for XFEATURE_ENABLED_MASK register
XGETBV; result in EDX:EAX
and eax, 06H
cmp eax, 06H; check OS has enabled both XMM and YMM state support
jne not_supported
mov eax, 1; mark as supported
jmp done
NOT_SUPPORTED:
mov eax, 0 ; // mark as not supported
done:
}
用途
在最低的程式設計級別,大部分常用 x86 彙編器現在都支援英特爾® AVX、FMA、AES 和 VPCLMULQDQ 指令,包括 Microsoft MASM*(Microsoft Visual Studio* 2010 版本)、NASM*、FASM* 和 YASM*。請參閱各自的相關文件,獲取詳細資訊。
對於語言編譯器,英特爾® C++ 編譯器 11.1 版及更高版本和英特爾® Fortran 編譯器都可以通過編譯器開關支援英特爾® AVX;而且這兩種編譯器還支援自動向量化和浮點迴圈。英特爾® C++ 編譯器支援英特爾® AVX 行內函數(使用 #include 訪問行內函數)和內嵌組合語言,甚至還可以使用 #include "avxintrin_emu.h" 支援英特爾® 行內函數模擬。
Microsoft Visual Studio* C++ 2010 (SP1) 及更高版本在編譯 64 位置程式碼(使用 /arch:AVX 編譯器開關)時支援英特爾® AVX(請參閱“更多資訊”)。它使用標頭支援行內函數,但是不支援內嵌組合語言。MASM*、程式碼的反彙編檢視和暫存器的配置程式檢視(完全支援 YMM)中都支援英特爾® AVX。
GNU Compiler Collection* (GCC*) 4.4 版通過同一標頭 支援英特爾® AVX 行內函數。Binutils 2.20.51.0.1 及更高版本、gdb 6.8.50.20090915 及更高版本、最新版的 GNU 彙編器 (GAS) 以及 objdump 中還提供了其他 GNU 工具鏈支援。如果您的編譯器不支援英特爾® AVX,您可以在許多情況下發出所需的位元組,但是一流的支援能為您帶來更多方便。
以上提及的三個 C++ 編譯器都可以從 C 或 C++ 程式碼中使用英特爾® AVX 支援同一行內函數運算,從而簡化運算。行內函數是編譯器使用相應的彙編函式替換的函式。大部分英特爾® AVX 行內函數的命名都遵循以下格式:
_mm256_op_suffix(data_type param1, data_type param2, data_type param3)
其中 _mm256 是在新的 256 位暫存器上執行的字首;_op 是運算,類似於加法 add 或者減法 sub;而 _suffix 則表示運算的資料型別,第一個字母表示緊縮 (p)、擴充套件緊縮 (ep) 或標量 (s)。表 2 中列出了其餘字母所代表的型別。
表 2.英特爾® AVX 字尾標記
| Marking | Meaning |
|---|---|
[s/d] |
單精度或雙精度浮點 |
[i/u]nnn |
位大小 nnn為 128、64、32、16 或 8 |
[ps/pd/sd] |
緊縮單精度、緊縮雙精度或標量雙精度 |
epi32 |
擴充套件緊縮 32 位帶符號整數 |
si256 |
標量 256 位整數 |
表 3 中列出了資料型別。前兩個引數是源暫存器,第三個引數(顯示時)是一個整數掩碼、選擇因子或偏移值。
表 3.英特爾® AVX 行內函數資料型別
| Type | Meaning |
|---|---|
__m256 |
256 位,作為 8 個單精度浮點值,表示一個 YMM 暫存器或記憶體位置 |
__m256d |
256 位,作為 4 個雙精度浮點值,表示一個 YMM 暫存器或記憶體位置 |
__m256i |
256 位,作為整數、(位元組、字等) |
__m128 |
128 位單精度浮點(每個 32 位) |
__m128d |
128 位雙精度浮點(每個 64 位) |
某些行內函數位於其他標頭中,如 中的 AES 和 PCLMULQDQ。檢視您的編譯器文件或者網站,瞭解各種行內函數的位置。
Microsoft Visual Studio* 2010
為了簡單明瞭,本文中的以下部分將使用帶有 SP1 的 Microsoft Visual Studio* 2010,英特爾® 編譯器或 GCC* 上執行的程式碼與之類似。如果您依次點選 Project Properties > Configuration > Code Generation ,在Enable Enhanced Instruction Set 下選擇Not Set ,然後將 /arch:AVX 手動新增至 Command Line 條目下的命令列,帶有 SP1 的Microsoft Visual Studio* 2010 將自動生成英特爾® AVX 程式碼。作為使用行內函數的一個例項,條目 2 提供了基於行內函數的英特爾® AVX 特性檢測例程。
條目 2.基於行內函數的特性檢測
// get AVX intrinsics
#include <immintrin.h>
// get CPUID capability
#include <intrin.h>
// written for clarity, not conciseness
#define OSXSAVEFlag (1UL<<27)
#define AVXFlag ((1UL<<28)|OSXSAVEFlag)
#define VAESFlag ((1UL<<25)|AVXFlag|OSXSAVEFlag)
#define FMAFlag ((1UL<<12)|AVXFlag|OSXSAVEFlag)
#define CLMULFlag ((1UL<< 1)|AVXFlag|OSXSAVEFlag)
bool DetectFeature(unsigned int feature)
{
int CPUInfo[4], InfoType=1, ECX = 1;
__cpuidex(CPUInfo, 1, 1); // read the desired CPUID format
unsigned int ECX = CPUInfo[2]; // the output of CPUID in the ECX register.
if ((ECX & feature) != feature) // Missing feature
return false;
__int64 val = _xgetbv(0); // read XFEATURE_ENABLED_MASK register
if ((val&6) != 6) // check OS has enabled both XMM and YMM support.
return false;
return true;
}
附錄 A:指令集參考
許多指令都是緊縮或標量形式,即它們在暫存器的多個並行元素或者一個單一元素上執行——標記為 [P/S]。條目長度分為雙精度或單精度浮點(簡稱為雙精度和單精度),標記為 [D/S];整數形式分為位元組、字、雙字和四字,標記為 [B/W/D/Q]。整數形式有時還分為帶符號形式和無符號形式,標記為 [S/U] 。有些指令在暫存器的高區或低區執行,標記為 [H/L] ;下文的表格中提供了其他可選元素。英特爾® SSE 形式和英特爾® AVX 形式中的指令以英特爾® AVX 形式的 (V) 為字首,支援 3 運算元和 256 位暫存器。方括號 ( []) 中的條目為必選;圓括號 ( ()) 中的條目為可選。
範例:
(V)ADD[P/S][D/S]是緊縮或標量、雙精度或單精度相加,有 8 種可能的形式——VADDPD, VADDPS, VADDSD, VADDSS, 和不以V開頭的版本。(V)[MIN/MAX][P/S][D/S]表示最大或最小雙精度或單精度緊縮或標量的 16 種不同指令。
下一表格列出了多個比較型別。VEX 字首的指令具有 32 個比較型別;非 VEX 字首的比較僅支援圓括號中的 8 個型別。每個比較型別分為多種形式,其中O = 有序的、U = 無序的、S = 發訊號、Q = 不發訊號。有序/無序表示如果一個運算元是 NaN(浮點中的非數),比較是 false 還是 true,在計算過程中出現某些錯誤時會發生該情形,如被 0 除或者負數的平方根。發訊號/不發訊號表示至少一個運算元是 QnaN(用於錯誤捕獲的靜態非數)時是否會出現一個異常。
| Type | Flavors | Meaning |
|---|---|---|
EQ |
(OQ), UQ, OS, US |
等於 |
LT |
(OS), OQ |
小於 |
LE |
(OS), OQ |
小於等於 |
UNORD |
(Q), S |
無序測試 (NaN) |
NEQ |
(UQ), US, OQ, OS |
不等於 |
NLT |
(US), UQ |
不小於 |
NLE |
(US), UQ |
不小於等於 |
ORD |
(Q), S |
有序測試 (非 NaN) |
NGE |
US, UQ |
不大於等於 |
NGT |
US, UQ |
不大於 |
FALSE |
OQ, OS |
比較一直是 false |
GE |
OS, OQ |
大於等於 |
GT |
OS, OQ |
大於 |
TRUE |
UQ, US |
比較一直是 true |
最後,我們在此提供了所有英特爾® AVX 指令:
| Arithmetic | Description |
|---|---|
(V)[ADD/SUB/MUL/DIV][P/S][D/S] |
加/減/乘/除緊縮/標量雙精度/單精度 |
(V)ADDSUBP[D/S] |
緊縮雙精度/單精度加減互動指數 |
(V)DPP[D/S] |
點積,基於即時任務 |
(V)HADDP[D/S] |
水平相加 |
(V)[MIN/MAX][P/S][D/S] |
最小/最大緊縮/標量雙精度/單精度 |
(V)MOVMSKP[D/S] |
雙精度/單精度符號掩碼開方 |
(V)PMOVMSKB |
生成包括大部分重要位的掩碼 |
(V)MPSADBW |
多個絕對差值求和 |
(V)PABS[B/W/D] |
位元組/字/雙字上的緊縮絕對值 |
(V)P[ADD/SUB][B/W/D/Q] |
加/減緊縮位元組/字/雙字/四字 |
(V)PADD[S/U]S[B/W] |
緊縮帶符號/無符號加飽和位元組/字 |
(V)PAVG[B/W] |
平均緊縮位元組/字 |
(V)PCLMULQDQ |
Carry-less 乘法四字 |
(V)PH[ADD/SUB][W/D] |
緊縮垂直加/減字/雙字 |
(V)PH[ADD/SUB]SW |
緊縮垂直加/減飽和 |
(V)PHMINPOSUW |
最小垂直無符號字和位置 |
(V)PMADDWD |
乘加緊縮整數 |
(V)PMADDUBSW |
無符號位元組和帶符號位元組乘以帶符號字 |
(V)P[MIN/MAX][S/U][B/W/D] |
最小/最大緊縮帶符號/無符號整數 |
(V)PMUL[H/L][S/U]W |
乘以緊縮帶符號/無符號整數和儲存高區/低區結果 |
(V)PMULHRSW |
使用約數和移位乘以緊縮無符號 |
(V)PMULHW |
乘以緊縮整數和儲存高區結果 |
(V)PMULL[W/D] |
乘以緊縮整數和儲存低區結果 |
(V)PMUL(U)DQ |
乘以緊縮帶符號/無符號雙字整數和儲存四字 |
(V)PSADBW |
計算無符號位元組絕對差值總和 |
(V)PSIGN[B/W/D] |
根據其他運算元上的符號更改一個運算元中每個元素的符號 |
(V)PS[L/R]LDQ |
運算元中位元組左/右移位量 |
(V)SL[L/AR/LR][W/D/Q] |
位左移/演算法右移/邏輯右移 |
(V)PSUB(U)S[B/W] |
緊縮帶符號/無符號減去帶符號/無符號飽和 |
(V)RCP[P/S]S |
計算緊縮/標量單精度的近似倒數 |
(V)RSQRT[P/S]S |
計算緊縮/標量單精度平方根的近似倒數 |
(V)ROUND[P/S][D/S] |
緊縮/標量雙精度/單精度的約數 |
(V)SQRT[P/S][D/S] |
緊縮/標量雙精度/單精度的平方根 |
VZERO[ALL/UPPER] |
將 YMM 暫存器的全部/上層歸零 |
| Comparison | Description |
|---|---|
(V)CMP[P/S][D/S] |
比較緊縮/標量雙精度/單精度 |
(V)COMIS[S/D] |
比較標量雙精度/單精度,設定 EFLAGS |
(V)PCMP[EQ/GT][B/W/D/Q] |
比較緊縮整數等於/大於 |
(V)PCMP[E/I]STR[I/M] |
比較顯式/隱式長度字串,返回指數/掩碼 |
| Control | Description |
|---|---|
V[LD/ST]MXCSR |
載入/儲存 MXCSR 控制/狀態暫存器 |
XSAVEOPT |
儲存優化的處理器延伸狀態 |
| Conversion | Description |
|---|---|
(V)CVTx2y |
將型別 x 轉換為型別 y,其中 x 和 y 從以下選擇:DQ 和 P[D/S],[P/S]S 和[P/S]D, orS[D/S] 和 SI. |
| Load/store | Description |
|---|---|
VBROADCAST[SS/SD/F128] |
通過傳播進行載入(將單個數值載入到多個位置) |
VEXTRACTF128 |
128 位浮點值開方 |
(V)EXTRACTPS |
緊縮單精度開方 |
VINSERTF128 |
插入緊縮浮點值 |
(V)INSERTPS |
插入緊縮單精度值 |
(V)PINSR[B/W/D/Q] |
插入整數 |
(V)LDDQU |
移動四倍未對齊整數 |
(V)MASKMOVDQU |
使用非暫時提示NT Hint儲存雙四字中的指定位元組 |
VMASKMOVP[D/S] |
有條件的 SIMD 緊縮載入/儲存 |
(V)MOV[A/U]P[D/S] |
移動對齊/未對齊的緊縮雙精度/單精度 |
(V)MOV[D/Q] |
移動雙字/四字 |
(V)MOVDQ[A/U] |
移動對齊/未對齊的雙字至四字 |
(V)MOV[HL/LH]P[D/S] |
移動高區到低區/低區到高區的緊縮雙精度/單精度 |
(V)MOV[H/L]P[D/S] |
移動高區/低區的緊縮雙精度/單精度 |
(V)MOVNT[DQ/PD/PS] |
使用非暫時提示移動緊縮整數/雙精度/單精度 |
(V)MOVNTDQA |
使用對齊的非暫時提示移動緊縮整數 |
(V)MOVS[D/S] |
移動或合併標量雙精度/單精度 |
(V)MOVS[H/L]DUP |
移動單個奇/偶指數的單精度 |
(V)PACK[U/S]SW[B/W] |
在位元組/字上對無符號/帶符號飽和進行緊縮 |
(V)PALIGNR |
位元組對齊 |
(V)PEXTR[B/W/D/Q] |
整數開方 |
(V)PMOV[S/Z]X[B/W/D][W/D/Q] |
使用帶符號/零擴充套件緊縮移動(僅根據長度,不支援 DD、DW 等) |
| Logical | Description |
|---|---|
(V)[AND/ANDN/OR]P[D/S] |
緊縮雙精度/單精度值的位邏輯 AND/AND NOT/OR |
(V)PAND(N) |
邏輯AND (NOT) |
(V)P[OR/XOR] |
位邏輯 logical OR/exclusive OR |
(V)PTEST |
緊縮位測試,如果位邏輯 AND為 all 0,則設定零標記 |
(V)UCOMIS[D/S] |
無序比較標量雙精度/單精度並設定EFLAGS |
(V)XORP[D/S] |
緊縮雙精度/單精度的位邏輯 XOR |
| Shuffle | Description |
|---|---|
(V)BLENDP[D/S] |
混合緊縮雙精度/單精度,基於掩碼選擇元素 |
(V)BLENDVP[D/S] |
混合值 |
(V)MOVDDUP |
向所有值中複製偶數值 |
(V)PBLENDVB |
變數混合緊縮位元組 |
(V)PBLENDW |
混合緊縮字 |
VPERMILP[D/S] |
轉換雙精度/單精度值 |
VPERM2F128 |
轉換浮點值 |
(V)PSHUF[B/D] |
根據即時值移動緊縮位元組/雙字 |
(V)PSHUF[H/L]W |
移動緊縮高區/低區字 |
(V)PUNPCK[H/L][BW/WD/DQ/QDQ] |
解緊縮高區/低區資料 |
(V)SHUFP[D/S] |
移動緊縮雙精度/單精度 |
(V)UNPCK[H/L]P[D/S] |
解緊縮和交錯緊縮變數雙精度/單精度值 |
| Future Instructions | Description |
|---|---|
[RD/WR][F/G]SBASE |
讀/寫 FS/GS 暫存器 |
RDRAND |
讀取隨機數(至 r16、r32、r64) |
VCVTPH2PS |
將 16 位浮點值轉換為單精度浮點值 |
VCVTPS2PH |
將單精度值轉換為 16 位浮點值 |
| FMA | Each [z] is the string 132 or 213 or 231, giving the order the operands A,B,C are used in: 132 is A=AC+B 213 is A=AB+C 231 is A=BC+A |
|---|---|
VFMADD[z][P/S][D/S] |
面向雙精度/單精度緊縮/標量的融合乘加 A = r1 * r2 + r3 |
VFMADDSUB[z]P[D/S] |
融合乘互動加/減緊縮雙精度/單精度 A = r1 * r2 + r3(奇指數),A = r1 * r2-r3(偶指數) |
VFMSUBADD[z]P[D/S] |
融合乘互動減/加緊縮雙精度/單精度 A = r1 * r2 - r3(奇指數),A = r1 * r2+r3(偶指數) |
VFMSUB[z][P/S][D/S] |
面向雙精度/單精度值緊縮/標量的融合乘減 A = r1 * r2 - r3 |
VFNMADD[z][P/S][D/S] |
緊縮/標量雙精度/單精度的融合負數乘加 A = -r1 * r2+r3 |
VFNMSUB[z][P/S][D/S] |
緊縮/標量雙精度/單精度的融合負數乘減 A = -r1 * r2-r3 |
更多資訊
英特爾® 高階向量擴充套件指令集程式設計指南: http://redfort-software.intel.com/en-us/avx/
聯邦資訊處理標準出版物 197,“釋出高階加密標準”:http://csrc.nist.gov/publications/fips/fips197/fips-197.pdf
The IEEE 754-2008 floating-point format standard at http://en.wikipedia.org/wiki/IEEE_754-2008
IEEE 754-2008 浮點格式標準:http://en.wikipedia.org/wiki/IEEE_754-2008
64 位驅動程式浮點支援:http://msdn.microsoft.com/en-us/library/ff545910.aspx
Mandelbrot 集的維基百科條目:http://en.wikipedia.org/wiki/Mandelbrot_set
英特爾® 軟體開發模擬器:http://redfort-software.intel.com/en-us/articles/intel-software-development-emulator
下載完整的 Mandelbrot 英特爾® AVX 實施:http://www.lomont.org/