機器學習_論文筆記_1: A few useful things to know about machine learning
阿新 • • 發佈:2018-12-17
> 翻譯總結by joey周琦
希望把自己閱讀到的,覺得有營養的論文,總結筆記和自己想法,留給自己,也分享給大家。因為英文論文中一些專有,有難度的詞句,會給出英文原文。
這篇文章總結了有關機器學習的12條重要,簡單,明瞭的經驗。本文面對分類問題總結,但不限於分類問題。
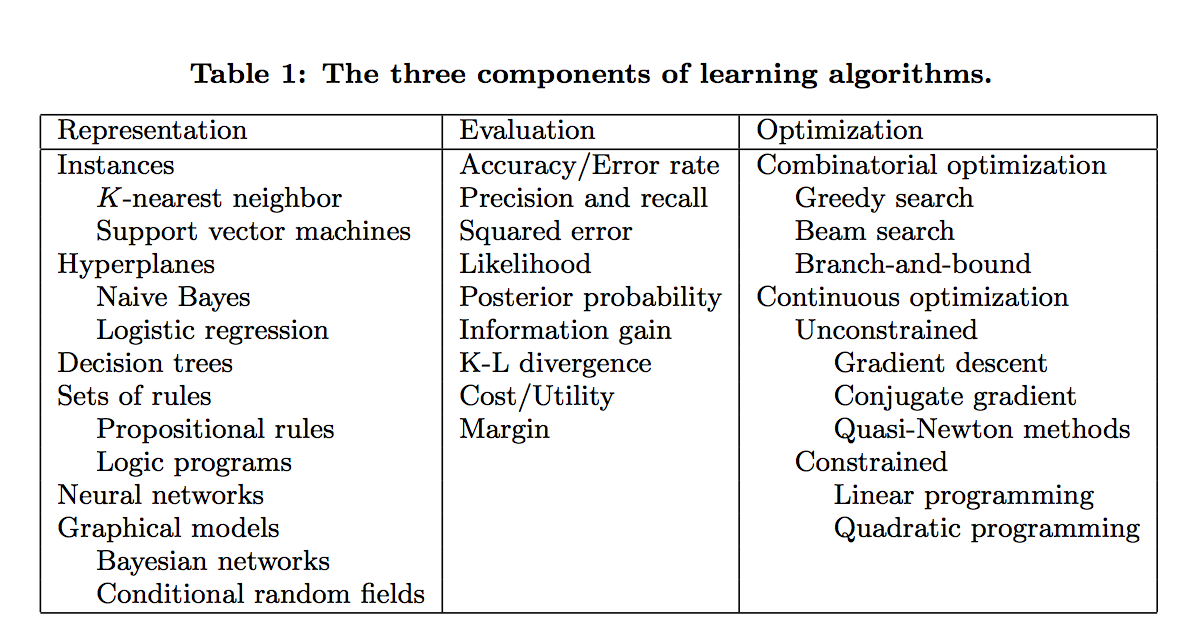
學習=模型+評估+優化
Learning = representation + evaluation + optimization。- representation(模型): 對於一個學習演算法選擇一個模型,相當於選擇一個分類器的集合,這個集合可稱為假設空間,空間中的分類器被認為是可以學習的。常見的模型有:KNN, SVM, Naive Bayes, 邏輯迴歸LR, 決策樹等等。
- evaluation (評估): 也就是目標函式(cost function)或得分函式。常見的評估指標有, 準確率召回率,平方誤差和,似然函式,後驗概率等。
- optimization (優化): 也就是優化演算法。常見的優化演算法有梯度下降法,高斯牛頓法,線性優化,二次優化等。
- 課本中一般都是以模型來分章節講解,但是評估與優化同等重要。
泛化能力才是重要的(It’s Generalization that counts)
- 資料要分為訓練資料和測試資料,只提高訓練資料的預測精度是不夠,這樣可能會造成過擬合。100%的在訓練資料上的精度,可能在測試資料上只有50%. 在訓練資料上75%的精度可能測試資料上也是75%的精度,由於前面的分類器。所以說泛化能力才是最重要的。
只有資料是不夠的
- 只有資料是無法進行機器學習的,必須有先驗的知識在演算法裡面。(no free lunch理論)
- 先驗知識比如,用什麼建模,評估,如何優化
- 過擬合有很多方面 (overfitting has many faces)
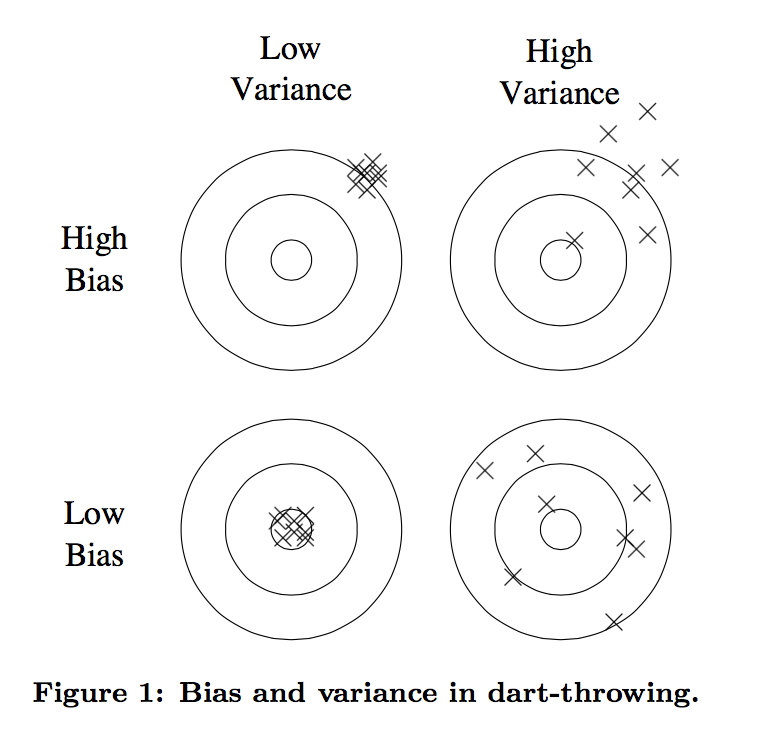
- 誤差可以分解為 bias和variance兩個方面,如下圖
- bias可以理解是預測或估計很多次的均值
- variance表示很多次估計的方差,如右下角的圖,雖然均值和真實接近,但是每一次估計的方差過大。
- 線性模型一般variance小,bias大
- 樹模型一般variance大,bias小
- 下面幾個思路可能減小過擬合:
- 交叉驗證 (cross validation), 即每次抽出一部分資料作為test data, 剩下的作為training data
- 可以加入正則項,避免模型過於複雜
- 一個常見的誤解是,有噪聲的情況才會出現過擬合。(沒有噪聲也會出現過擬合)
- 誤差可以分解為 bias和variance兩個方面,如下圖
- 直覺在高維度行不通
- 維數災難
- 在高維度的相似度和低緯度的相似度不同
- 直覺上,加入一些資訊量少的feature可能不會影響預測效果,因為它最多少提供一些資訊。然後現實中,這些feature提供的資訊的益處不如它增加的維度對結果所帶來的壞處。
- 可以通過一定方法降維輸入的feature,如PCA等
- 理論保證不一定可靠
- 現實實現中,理論保證不一定可靠
- 理論推動了機器學習的發展,但是在實際中只是參考因素之一
- 特徵工程(選擇)是關鍵 (feature engineering is the key)
- 為什麼有些機器學習專案成功了,有些沒有呢?最核心的原因就是feature的選擇使用。
- 實際專案中,很多時間都在用於,收集、清理、預處理資料,特徵選擇。然後才是放在演算法中跑
- 跑演算法可能是其中最快的一環。(因為很成熟了)
- 在特徵選擇時,需要加入人的知識在裡面,那些效果好的演算法往往是特徵選擇的好。(以呼應了前面的理論,只有data是不夠的,需要人的智慧)
- (插一句,難怪現在資料探勘工程師都被稱為feature engineer)
- 更多的資料可以打敗更聰明的演算法
- 假設你已經拿到了最優的feature,如何繼續優化
- 1 設計更好的演算法
- 2 使用更多的資料
- 很多研究者專注於設計更好的演算法,而最快速簡單的方法就是收集使用更多的資料
- 80年代收集資料是問題,現在主要的問題是處理資料的速度。
- 假設你已經拿到了最優的feature,如何繼續優化
- 學習更多的模型,而不是一個
- 現在 model ensembles的技術非常標準了,最簡單的就是bagging.
- 簡單來說就是多訓練不同的模型,用model ensembles的技術將這些模型綜合起來用,可以得到比任何模型單一都好的效果。(在netflixprize比賽中也得到了體現,不同隊伍的分類器組合到一起可以得到一個更優的分類器)
- 簡單並不代表準確
* 如果假設模型比較的簡單,並且獲取了比較好的結果,說明是假設的比較精確。並不能說明越簡單就越精確
* 簡單本身就是一種優點,但是它和精確沒有必然聯絡 - 可以被建模不一定代表可以被學習
- 相關關係並不意味著因果關係
.