
數學基礎之概率統計
3-1、為什麼使用概率?
概率論是用於表示不確定性陳述的數學框架,即它是對事物不確定性的度量。
在人工智慧領域,我們主要以兩種方式來使用概率論。首先,概率法則告訴我們AI系統應該如何推理,所以我們設計一些演算法來計算或者近似由概率論匯出的表示式。其次,我們可以用概率和統計從理論上分析我們提出的AI系統的行為。
電腦科學的許多分支處理的物件都是完全確定的實體,但機器學習卻大量使用概率論。實際上如果你瞭解機器學習的工作原理你就會覺得這個很正常。因為機器學習大部分時候處理的都是不確定量或隨機量。
 3-2、隨機變數
3-2、隨機變數
隨機變數可以隨機地取不同值的變數。我們通常用小寫字母來表示隨機變數本身,而用帶數字下標的小寫字母來表示隨機變數能夠取到的值。例如,
對於向量值變數,我們會將隨機變數寫成X,它的一個值為。就其本身而言,一個隨機變數只是對可能的狀態的描述;它必須伴隨著一個概率分佈來指定每個狀態的可能性。
隨機變數可以是離散的或者連續的。
3-3、概率分佈
給定某隨機變數的取值範圍,概率分佈就是導致該隨機事件出現的可能性。
從機器學習的角度來看,概率分佈就是符合隨機變數取值範圍的某個物件屬於某個類別或服從某種趨勢的可能性。
3-4、條件概率
很多情況下,我們感興趣的是某個事件在給定其它事件發生時出現的概率,這種概率叫條件概率。
我們將給定時
發生的概率記為
,這個概率可以通過下面的公式來計算:
3-5、貝葉斯公式
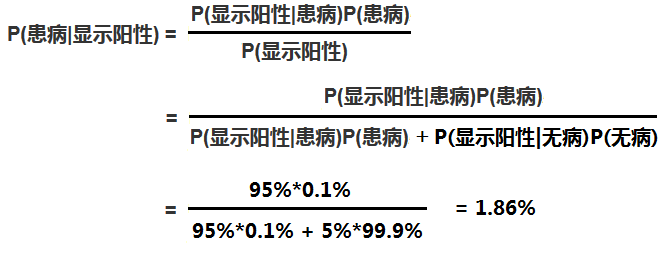
先看看什麼是“先驗概率”和“後驗概率”,以一個例子來說明:
假設某種病在人群中的發病率是0.001,即1000人中大概會有1個人得病,則有: P(患病) = 0.1%;即:在沒有做檢驗之前,我們預計的患病率為P(患病)=0.1%,這個就叫作"先驗概率"。
再假設現在有一種該病的檢測方法,其檢測的準確率為95%;即:如果真的得了這種病,該檢測法有95%的概率會檢測出陽性,但也有5%的概率檢測出陰性;或者反過來說,但如果沒有得病,採用該方法有95%的概率檢測出陰性,但也有5%的概率檢測為陽性。用概率條件概率表示即為:P(顯示陽性|患病)=95%
現在我們想知道的是:在做完檢測顯示為陽性後,某人的患病率P(
而這個叫貝葉斯的人其實就是為我們提供了一種可以利用先驗概率計算後驗概率的方法,我們將其稱為“貝葉斯公式”,如下:
在這個例子裡就是:
 貝葉斯公式貫穿了機器學習中隨機問題分析的全過程。從文字分類到概率圖模型,其基本分類都是貝葉斯公式。
貝葉斯公式貫穿了機器學習中隨機問題分析的全過程。從文字分類到概率圖模型,其基本分類都是貝葉斯公式。
這裡需要說明的是,上面的計算中除了利用了貝葉斯公式外,還利用了“全概率公式”,即:
3-6、期望
在概率論和統計學中,數學期望是試驗中每次可能結果的概率乘以其結果的總和。它是最基本的數學特徵之一,反映隨機變數平均值的大小。
假設X是一個離散隨機變數,其可能的取值有:,各個取值對應的概率取值為:
,則其數學期望被定義為:
假設X是一個連續型隨機變數,其概率密度函式為則其數學期望被定義為:
3-7、方差
概率中,方差用來衡量隨機變數與其數學期望之間的偏離程度;統計中的方差為樣本方差,是各個樣本資料分別與其平均數之差的平方和的平均數。數學表示式如下:
3-8、協方差
在概率論和統計學中,協方差被用於衡量兩個隨機變數X和Y之間的總體誤差。數學定義式為:
3-9、常見分佈函式
1)0-1分佈
0-1分佈是單個二值型離散隨機變數的分佈,其概率分佈函式為:
2)幾何分佈
幾何分佈是離散型概率分佈,其定義為:在n次伯努利試驗中,試驗k次才得到第一次成功的機率。即:前k-1次皆失敗,第k次成功的概率。其概率分佈函式為:
性質:
3)二項分佈
二項分佈即重複n次伯努利試驗,各次試驗之間都相互獨立,並且每次試驗中只有兩種可能的結果,而且這兩種結果發生與否相互對立。如果每次試驗時,事件發生的概率為p,不發生的概率為1-p,則n次重複獨立試驗中發生k次的概率為:
性質:
4)高斯分佈
高斯分佈又叫正態分佈,其曲線呈鍾型,兩頭低,中間高,左右對稱因其曲線呈鐘形,如下圖所示:

若隨機變數X服從一個數學期望為,方差為
的正態分佈,則我們將其記為:
。其期望值
決定了正態分佈的位置,其標準差
(方差的開方)決定了正態分佈的幅度。
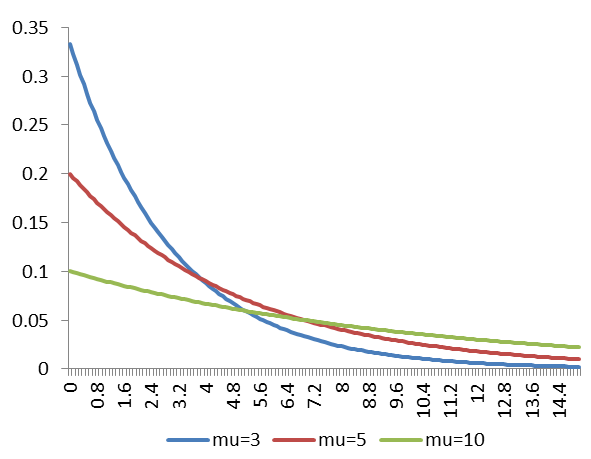
5)指數分佈
指數分佈是事件的時間間隔的概率,它的一個重要特徵是無記憶性。例如:如果某一元件的壽命的壽命為T,已知元件使用了t小時,它總共使用至少t+s小時的條件概率,與從開始使用時算起它使用至少s小時的概率相等。下面這些都屬於指數分佈:
- 嬰兒出生的時間間隔
- 網站訪問的時間間隔
- 奶粉銷售的時間間隔
指數分佈的公式可以從泊松分佈推斷出來。如果下一個嬰兒要間隔時間t,就等同於t之內沒有任何嬰兒出生,即:
則:
如:接下來15分鐘,會有嬰兒出生的概率為:
指數分佈的影象如下:
6)泊松分佈
日常生活中,大量事件是有固定頻率的,比如:
- 某醫院平均每小時出生3個嬰兒
- 某網站平均每分鐘有2次訪問
- 某超市平均每小時銷售4包奶粉
它們的特點就是,我們可以預估這些事件的總數,但是沒法知道具體的發生時間。已知平均每小時出生3個嬰兒,請問下一個小時,會出生幾個?有可能一下子出生6個,也有可能一個都不出生,這是我們沒法知道的。
泊松分佈就是描述某段時間內,事件具體的發生概率。其概率函式為:
其中:
P表示概率,N表示某種函式關係,t表示時間,n表示數量,1小時內出生3個嬰兒的概率,就表示為 P(N(1) = 3) ;λ 表示事件的頻率。
還是以上面醫院平均每小時出生3個嬰兒為例,則;
那麼,接下來兩個小時,一個嬰兒都不出生的概率可以求得為:
同理,我們可以求接下來一個小時,至少出生兩個嬰兒的概率:
【注】上面的指數分佈和泊松分佈參考了阮一峰大牛的部落格:“泊松分佈和指數分佈:10分鐘教程”,在此說明,也對其表示感謝!
3-10、Lagrange乘子法
對於一般的求極值問題我們都知道,求導等於0就可以了。但是如果我們不但要求極值,還要求一個滿足一定約束條件的極值,那麼此時就可以構造Lagrange函式,其實就是把約束項新增到原函式上,然後對構造的新函式求導。對於一個要求極值的函式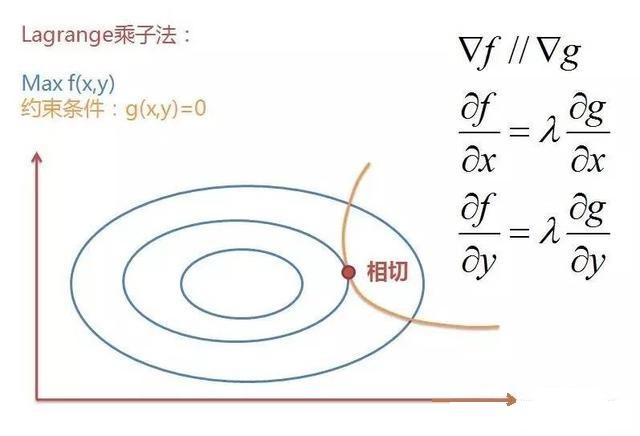
也就是說和
相切,或者說它們的梯度▽
和▽
平行,因此它們的梯度(偏導)成倍數關係;那我麼就假設為
倍,然後把約束條件加到原函式後再對它求導,其實就等於滿足了下圖上的式子。
3-11、最大似然法
最大似然也稱為最大概似估計,即:在“模型已定,引數θ未知”的情況下,通過觀測資料估計未知引數θ 的一種思想或方法。
其基本思想是: 給定樣本取值後,該樣本最有可能來自引數為何值的總體。即:尋找
使得觀測到樣本資料的可能性最大。
舉個例子,假設我們要統計全國人口的身高,首先假設這個身高服從服從正態分佈,但是該分佈的均值與方差未知。由於沒有足夠的人力和物力去統計全國每個人的身高,但是可以通過取樣(所有的取樣要求都是獨立同分布的),獲取部分人的身高,然後通過最大似然估計來獲取上述假設中的正態分佈的均值與方差。
求極大似然函式估計值的一般步驟:
- 1、寫出似然函式;
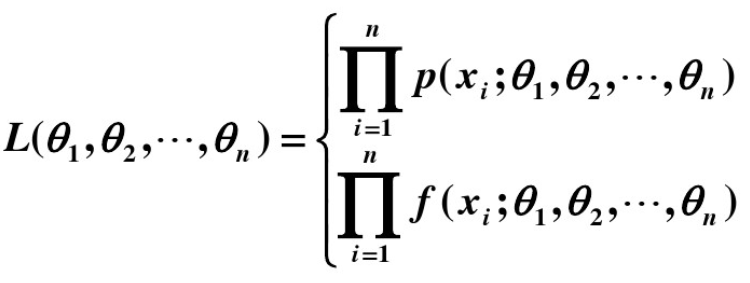
- 2、對似然函式取對數;
- 3、兩邊同時求導數;
- 4、令導數為0解出似然方程。
最大似然估計也是統計學習中經驗風險最小化的例子。如果模型為條件概率分佈,損失函式定義為對數損失函式,經驗風險最小化就等價於最大似然估計。
 四、資訊理論
四、資訊理論
資訊理論是應用數學的一個分支,主要研究的是對一個訊號能夠提供資訊的多少進行量化。如果說概率使我們能夠做出不確定性的陳述以及在不確定性存在的情況下進行推理,那資訊理論就是使我們能夠量化概率分佈中不確定性的總量。
1948年,夏農引入資訊熵,將其定義為離散隨機事件的出現概率。一個系統越是有序,資訊熵就越低;反之,一個系統越是混亂,資訊熵就越高。所以說,資訊熵可以被認為是系統有序化程度的一個度量。
4-1、熵
如果一個隨機變數X的可能取值為,其概率分佈為
,則隨機變數X的熵定義為H(X):
4-2、聯合熵
兩個隨機變數X和Y的聯合分佈可以形成聯合熵,定義為聯合自資訊的數學期望,它是二維隨機變數XY的不確定性的度量,用H(X,Y)表示:
4-3、條件熵
在隨機變數X發生的前提下,隨機變數Y發生新帶來的熵,定義為Y的條件熵,用H(Y|X)表示:
條件熵用來衡量在已知隨機變數X的條件下,隨機變數Y的不確定性。
實際上,熵、聯合熵和條件熵之間存在以下關係:
推導過程如下:
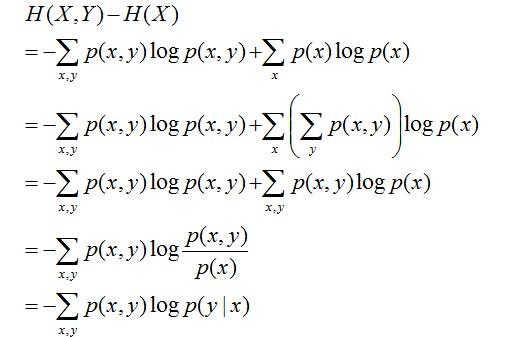 其中:
其中:
- 第二行推到第三行的依據是邊緣分佈P(x)等於聯合分佈P(x,y)的和;
- 第三行推到第四行的依據是把公因子logP(x)乘進去,然後把x,y寫在一起;
- 第四行推到第五行的依據是:因為兩個sigma都有P(x,y),故提取公因子P(x,y)放到外邊,然後把裡邊的-(log P(x,y) - log P(x))寫成- log (P(x,y) / P(x) ) ;
- 第五行推到第六行的依據是:P(x,y) = P(x) * P(y|x),故P(x,y) / P(x) = P(y|x)。
4-4、相對熵
相對熵又稱互熵、交叉熵、KL散度、資訊增益,是描述兩個概率分佈P和Q差異的一種方法,記為D(P||Q)。在資訊理論中,D(P||Q)表示當用概率分佈Q來擬合真實分佈P時,產生的資訊損耗,其中P表示真實分佈,Q表示P的擬合分佈。
對於一個離散隨機變數的兩個概率分佈P和Q來說,它們的相對熵定義為:
注意:D(P||Q) ≠ D(Q||P)
4-5、互資訊
兩個隨機變數X,Y的互資訊定義為X,Y的聯合分佈和各自獨立分佈乘積的相對熵稱為互資訊,用I(X,Y)表示。互資訊是資訊理論裡一種有用的資訊度量方式,它可以看成是一個隨機變數中包含的關於另一個隨機變數的資訊量,或者說是一個隨機變數由於已知另一個隨機變數而減少的不肯定性。
互資訊、熵和條件熵之間存在以下關係:
推導過程如下:
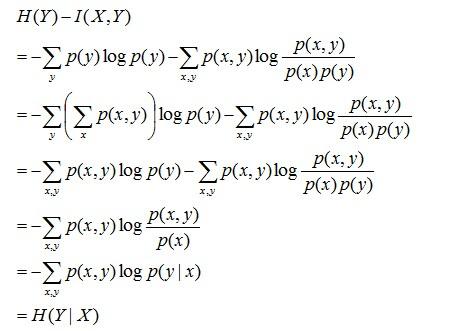 通過上面的計算過程發現有:H(Y|X)
= H(Y) - I(X,Y),又由前面條件熵的定義有:H(Y|X) = H(X,Y) - H(X),於是有I(X,Y)= H(X) + H(Y) - H(X,Y),此結論被多數文獻作為互資訊的定義。
通過上面的計算過程發現有:H(Y|X)
= H(Y) - I(X,Y),又由前面條件熵的定義有:H(Y|X) = H(X,Y) - H(X),於是有I(X,Y)= H(X) + H(Y) - H(X,Y),此結論被多數文獻作為互資訊的定義。
4-6、最大熵模型
最大熵原理是概率模型學習的一個準則,它認為:學習概率模型時,在所有可能的概率分佈中,熵最大的模型是最好的模型。通常用約束條件來確定模型的集合,所以,最大熵模型原理也可以表述為:在滿足約束條件的模型集合中選取熵最大的模型。
前面我們知道,若隨機變數X的概率分佈是,則其熵定義如下:
熵滿足下列不等式:
式中,|X|是X的取值個數,當且僅當X的分佈是均勻分佈時右邊的等號成立。也就是說,當X服從均勻分佈時,熵最大。
直觀地看,最大熵原理認為:要選擇概率模型,首先必須滿足已有的事實,即約束條件;在沒有更多資訊的情況下,那些不確定的部分都是“等可能的”。最大熵原理通過熵的最大化來表示等可能性;“等可能”不易操作,而熵則是一個可優化的指標。