
【一文學會】Gumbel-Softmax的取樣技巧
以強化學習為例,假設網路輸出的三維向量代表三個動作(前進、停留、後退)在下一步的收益,value=[-10,10,15],那麼下一步我們就會選擇收益最大的動作(後退)繼續執行,於是輸出動作[0,0,1]。選擇值最大的作為輸出動作,這樣做本身沒問題,但是在網路中這種取法有個問題是不能計算梯度,也就不能更新網路。
基於softmax的取樣
這時通常的做法是加上softmax函式,把向量歸一化,這樣既能計算梯度,同時值的大小還能表示概率的含義(多項分佈)。
於是value=[-10,10,15]通過softmax函式後有σ(value)=[0,0.007,0.993],這樣做不會改變動作或者說類別的選取,同時softmax傾向於讓最大值的概率顯著大於其他值,比如這裡15和10經過softmax放縮之後變成了0.993和0.007,這有利於把網路訓成一個one-hot輸出的形式,這種方式在分類問題中是常用方法。
但這樣就不會體現概率的含義了,因為σ(value)=[0,0.007,0.993]與σ(value)=[0.3,0.2,0.5]在類別選取的結果看來沒有任何差別,都是選擇第三個類別,但是從概率意義上講差別是巨大的。
很直接的方法是依概率取樣完事了,比如直接用np.random.choice函式依照概率生成樣本值,這樣概率就有意義了。所以,經典的取樣方法就是用softmax函式加上輪盤賭方法(np.random.choice)。但這樣還是會有個問題,這種方式怎麼計算梯度?不能計算梯度怎麼更新網路?
def sample_with_softmax(logits, size): # logits為輸入資料 # size為取樣數 pro = softmax(logits) return np.random.choice(len(logits), size, p=pro)
基於gumbel-max的取樣
gumbel分佈的具體介紹會放在後文,我們先看看結論。對於K維概率向量,對
對應的離散變數
新增Gumbel噪聲,再取樣
其中,是獨立同分布的標準Gumbel分佈的隨機變數,標準Gumbel分佈的CDF為
.所以
可以通過Gumbel分佈求逆從均勻分佈生成,即
。
代入計算可知,這裡的
就是上面softmax取樣的
,這樣就得到了基於gumbel-max的取樣過程:
-
對於網路輸出的一個K維向量v,生成K個服從均勻分佈U(0,1)的獨立樣本ϵ1,...,ϵK;
-
通過
計算得到
;
-
對應相加得到新的值向量v′=[v1+G1,v2+G2,...,vK+GK];
-
取最大值作為最終的類別
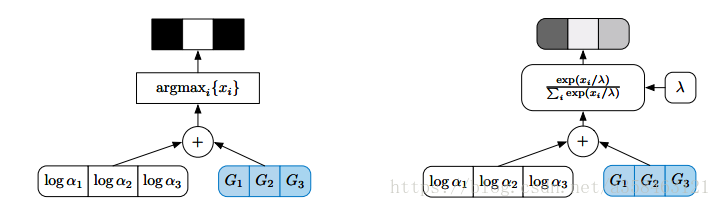
可以證明,gumbel-max 方法的取樣效果等效於基於 softmax 的方式(後文也會證明)。由於 Gumbel 隨機數可以預先計算好,取樣過程也不需要計算 softmax,因此,某些情況下,gumbel-max 方法相比於 softmax,在取樣速度上會有優勢。當然,可以看到由於這中間有一個argmax操作,這是不可導的,依舊沒法用於計算網路梯度。
def sample_with_gumbel_noise(logits, size):
noise = sample_gumbel((size, len(logits))) # 產生gumbel noise
return np.argmax(logits + noise, axis=1)基於gumbel-softmax的取樣
如果僅僅是提供一種常規 softmax 取樣的替代方案, gumbel 分佈似乎應用價值並不大。幸運的是,我們可以利用 gumbel 實現多項分佈取樣的 reparameterization(再引數化)。
在VAE中,假設隱變數(latent variables)服從標準正態分佈。而現在,利用 gumbel-softmax 技巧,我們可以將隱變數建模為服從離散的多項分佈。在前面的兩種方法中,random.choice和argmax註定了這兩種方法不可導,但我們可以將後一種方法中的argmax soft化,變為softmax。
temperature 是在大於零的引數,它控制著 softmax 的 soft 程度。溫度越高,生成的分佈越平滑;溫度越低,生成的分佈越接近離散的 one-hot 分佈。訓練中,可以通過逐漸降低溫度,以逐步逼近真實的離散分佈。
這樣就得到了基於gumbel-max的取樣過程:
-
對於網路輸出的一個K維向量v,生成K個服從均勻分佈U(0,1)的獨立樣本ϵ1,...,ϵK;
-
通過
-
對應相加得到新的值向量v′=[v1+G1,v2+G2,...,vK+GK];
-
通過softmax函式計算概率大小得到最終的類別。
def differentiable_gumble_sample(logits, temperature=1):
noise = tf.random_uniform(tf.shape(logits), seed=11)
logits_with_noise = logits - tf.log(-tf.log(noise))
return tf.nn.softmax(logits_with_noise / temperature)OK,到此就是介紹了不同的取樣方法。我們再回頭看看還有哪些問題沒有講清楚:
1、為什麼方法三能生成和方法一一樣的效果?
2、為什麼使用Gumbel分佈就可以逼近多項分佈取樣?(這一部分我們會有理論證明)
3、為什麼 用了reparameterization(再引數化)就是可導的?
Gumbel分佈
首先,我們介紹一樣何為gumbel分佈,gumbel分佈是一種極值型分佈。舉例而言,假設一天內每次的喝水量為一個隨機變數,它可能服從某個概率分佈,記下這一天內喝的10次水的量並取最大的一個作為當天的喝水量值。顯然,每天的喝水量值也是一個隨機變數,並且它的概率分佈即為 Gumbel 分佈。實際上,只要是指數族分佈,它的極值分佈都服從Gumbel分佈。
它的概率密度函式(PDF)長這樣:
公式中, 是位置係數(Gumbel 分佈的眾數是
),
是尺度係數(Gumbel 分佈的方差是
)。

def gumbel_pdf(x, mu=0, beta=1):
z = (x - mu) / beta
return np.exp(-z - np.exp(-z)) / beta
回答問題一
先定義一個多項分佈,作出真實的概率密度圖。再通過取樣的方式比較各種方法的效果。這裡定義了一個8類別的多項分佈,其真實的密度函式如下左圖。
首先我們直接根據真實的分佈利用np.random.choice函式取樣對比效果(實現程式碼放在文末)

左圖為真實概率分佈,右圖為採用np.random.choice函式取樣的結果(取樣次數為1000)。可見效果還是非常好的,要是沒有不能求梯度這個問題,直接從原分佈取樣是再好不過的。接著通過前述的方法新增Gumbel噪聲取樣,同時也新增正態分佈和均勻分佈的噪聲作對比。(基於gumbel-max的取樣)

可以明顯看到Gumbel噪聲的取樣效果是最好的,正態分佈其次,均勻分佈最差。也就是說用Gumbel分佈的樣本點最接近真實分佈的樣本。

最後,我們基於gumbel-softmax做取樣,左圖設定temperature=0.1,經過softmax函式後得到的概率分佈接近one-hot分佈,用此概率分佈對分類求期望值,得到結果為左圖,可以較好地逼近方法一的取樣結果;右圖設定temperature=5,經過softmax函式後得到的概率分佈接近均勻分佈,再對分類求期望值,得到的結果集中在類別3、 4(中間的類別)。這和gumbel-softmax具備的性質是一致的,temperature控制著softmax的soft程度,溫度越高,生成的分佈越平滑(接近這裡的均勻分佈);溫度越低,生成的分佈越接近離散的one-hot分佈。因此,訓練時可以逐漸降低溫度,以逐步逼近真實的離散分佈。(基於gumbel-softmax的取樣)
到此為此,我們也算用一組實驗去解釋了為什麼方法二、方法三時可行的。具體的程式碼放在文末了,感興趣的可以研究一下。
回答問題二
為什麼它可以有這樣的效果?為什麼新增gumbel噪聲就可以近似範疇分佈(category distribution)取樣。
我們來考慮一個問題,假設一共有K個類別,那麼第k個類別恰好是最大的概率是多少?
對於一個K維的輸出向量,每個維度的值記為,通過softmax函式可得,取到每個維度的概率為:
這是直接用softmax得到的概率密度函式,它也可以換一種方式去說,對每個 新增獨立的標準Gumbel分佈(尺度引數為1,位置引數為0)噪聲,並選擇值最大的維度作為輸出,得到的概率密度同樣為
新增獨立的標準Gumbel分佈(尺度引數為1,位置引數為0)噪聲,並選擇值最大的維度作為輸出,得到的概率密度同樣為 。
。
我們現在來證明這事。
回顧一下剛剛說的gumbel分佈。尺度引數為1,位置引數為的gumbel分佈的PDF為:
以及CDF為:
假設第k個gumbel分佈對應
,相加得到隨機變數
,這就相當於
服從尺度引數為1,位置引數為
的Gumbel分佈。要證明這樣取得的隨機變數
與原隨機變數相同,只需證明取到
的概率為
。也就是
比其他
大的概率為
。
現在我們有了是最大的那個概率值,現在我們想知道第k個元素是最大的概率值是多少,因此,我們需要對所有z的取值進行積分,從而得到第k個位置取值最大的概率。對
求積分可得邊緣累積概率分佈函式
的概率呼叫gumbel分佈的PDF,即
,
為最大的概率上面已經證明,帶入化簡,最後一步積分裡面是的
的Gumbel分佈,所以整個積分為1。於是上面這條等式恰好是一個softmax的公式,也就是說,第k個位置最大的概率,恰好就是對離散概率分佈的一個近似。
回答問題三
最後,再來回答一樣為什麼再引數化(reparameterization tricks)就可以變得可導。
reparameterization tricks是什麼
reparameterization tricks的思想是說如果我們能把一個複雜變數用一個標準變數來表示,比如 ,其中 ϵ∼N(0;1) ,那麼我們就可以用ϵ這個變數取代z。舉個例子,假如p(z;θ)是個複雜分佈
,現在我們想將z再引數化,用p(ϵ)去表示p(z;θ),即ϵ∼N(0;1),用一個one-liners(簡單理解為一行變換,g(ϵ;θ))表示從ϵ到z的聯絡,令g(ϵ;θ)為μ+Rϵ。
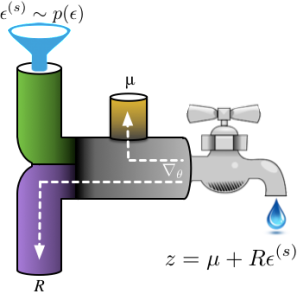
這樣做是有好處的,一方面在更新梯度時可以將隨機變數提取出來,不影響對引數的更新(如上圖中的μ,R);另一方面假如我們要依據p(z;θ)取樣,然後再利用取樣處的梯度修正p,這樣兩次的誤差就會疊加,但現在只需要從一個分佈非常穩定的random seed的分佈中取樣,比如N(0,1)所以noise小得多。常見的變換方法可見此文。實際運用起來就是,
我們現在將reparameterization tricks應用到取樣中。原本,網路中引數包括前向傳遞和反向傳遞(如下圖左半部分),現在我們計算出P(Z)後,依概率取樣(np.random.choice),由P(Z)得到樣本z沒問題,但反向傳遞時如何找到並更新P(Z)就沒法辦了。

然後,再引數化就可以解決這個問題。我們令,在上面的證明中,已經證明了使用隨機變數
去取樣是正確的,現在我們重新觀察此式,
服從gumbel分佈不正是可以看成基分佈(base distribution)p(ϵ)嘛!令g(ϵ;θ)為
,所以從
中取樣就變為從
中取樣,而我們在更新時可以避開簡單隨機變數
,只更新引數
。
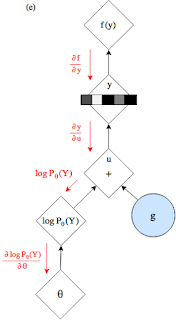
最後,放上用gumbel-max和gumbel-softmax取樣的圖結構。(圖中改成
)圖底下的“+”號可以看到,這是一種重引數的方法,通過加一個隨機的,固定分佈的噪聲,從而實現取樣。
附錄
放上程式碼:
from scipy.optimize import curve_fit
import numpy as np
import matplotlib.pyplot as plt
n_cats = 8
n_samples = 1000
cats = np.arange(n_cats)
probs = np.random.randint(low=1, high=20, size=n_cats)
probs = probs / sum(probs)
logits = np.log(probs)
def plot_probs(): # 真實概率分佈
plt.bar(cats, probs)
plt.xlabel("Category")
plt.ylabel("Original Probability")
def plot_estimated_probs(samples,ylabel=''):
n_cats = np.max(samples)+1
estd_probs,_,_ = plt.hist(samples,bins=np.arange(n_cats+1),align='left',edgecolor='white')
plt.xlabel('Category')
plt.ylabel(ylabel+'Estimated probability')
return estd_probs
def print_probs(probs):
print(probs)
samples = np.random.choice(cats,p=probs,size=n_samples) # 依概率取樣
plt.figure()
plt.subplot(1,2,1)
plot_probs()
plt.subplot(1,2,2)
estd_probs = plot_estimated_probs(samples)
plt.tight_layout() # 緊湊顯示圖片
plt.savefig('/home/zhumingchao/PycharmProjects/matplot/gumbel1')
print('Original probabilities:\t',end='')
print_probs(probs)
print('Estimated probabilities:\t',end='')
print_probs(estd_probs)
plt.show()
######################################
def sample_gumbel(logits):
noise = np.random.gumbel(size=len(logits))
sample = np.argmax(logits+noise)
return sample
gumbel_samples = [sample_gumbel(logits) for _ in range(n_samples)]
def sample_uniform(logits):
noise = np.random.uniform(size=len(logits))
sample = np.argmax(logits+noise)
return sample
uniform_samples = [sample_uniform(logits) for _ in range(n_samples)]
def sample_normal(logits):
noise = np.random.normal(size=len(logits))
sample = np.argmax(logits+noise)
# print('old',sample)
return sample
normal_samples = [sample_normal(logits) for _ in range(n_samples)]
plt.figure(figsize=(10,4))
plt.subplot(1,4,1)
plot_probs()
plt.subplot(1,4,2)
gumbel_estd_probs = plot_estimated_probs(gumbel_samples,'Gumbel ')
plt.subplot(1,4,3)
normal_estd_probs = plot_estimated_probs(normal_samples,'Normal ')
plt.subplot(1,4,4)
uniform_estd_probs = plot_estimated_probs(uniform_samples,'Uniform ')
plt.tight_layout()
plt.savefig('/home/zhumingchao/PycharmProjects/matplot/gumbel2')
print('Original probabilities:\t',end='')
print_probs(probs)
print('Gumbel Estimated probabilities:\t',end='')
print_probs(gumbel_estd_probs)
print('Normal Estimated probabilities:\t',end='')
print_probs(normal_estd_probs)
print('Uniform Estimated probabilities:\t',end='')
print_probs(uniform_estd_probs)
plt.show()
#######################################
def softmax(logits):
return np.exp(logits)/np.sum(np.exp(logits))
def differentiable_sample_1(logits, cats_range, temperature=.1):
noise = np.random.gumbel(size=len(logits))
logits_with_noise = softmax((logits+noise)/temperature)
# print(logits_with_noise)
sample = np.sum(logits_with_noise*cats_range)
return sample
differentiable_samples_1 = [differentiable_sample_1(logits,np.arange(n_cats)) for _ in range(n_samples)]
def differentiable_sample_2(logits, cats_range, temperature=5):
noise = np.random.gumbel(size=len(logits))
logits_with_noise = softmax((logits+noise)/temperature)
# print(logits_with_noise)
sample = np.sum(logits_with_noise*cats_range)
return sample
differentiable_samples_2 = [differentiable_sample_2(logits,np.arange(n_cats)) for _ in range(n_samples)]
def plot_estimated_probs_(samples,ylabel=''):
samples = np.rint(samples)
n_cats = np.max(samples)+1
estd_probs,_,_ = plt.hist(samples,bins=np.arange(n_cats+1),align='left',edgecolor='white')
plt.xlabel('Category')
plt.ylabel(ylabel+'Estimated probability')
return estd_probs
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
gumbelsoft_estd_probs_1 = plot_estimated_probs_(differentiable_samples_1,'Gumbel softmax')
plt.subplot(1,2,2)
gumbelsoft_estd_probs_2 = plot_estimated_probs_(differentiable_samples_2,'Gumbel softmax')
plt.tight_layout()
plt.savefig('/home/zhumingchao/PycharmProjects/matplot/gumbel3')
print('Gumbel Softmax Estimated probabilities:\t',end='')
print_probs(gumbelsoft_estd_probs_1)
plt.show()
我是小明,如果對文章內容或者其他想一起探討的,歡迎前來。

本篇文章參考了以下: