
python資料分析--KaggleTitanic專案實戰
主要圍繞Kaggle上的比賽題目: "給出泰坦尼克號上的乘客的資訊, 預測乘客是否倖存" 進行一個簡單的資料分析
環境
win8, python3.7, jupyter notebook
正文
1. 專案背景
泰坦尼克號: 是當時世界上體積最龐大、內部設施最豪華的客運輪船, 於1909年3月31日動工建造, 1912年4月2日完工試航. 於1912年4月10日, 在南安普敦港的海洋碼頭, 啟程駛往紐約, 開始了它的第一次, 也是最後一次的航行. 泰坦尼克號將乘客分為三個等級: 三等艙位於船身較下層也最便宜; 二等艙具備與當時其他一般船隻的頭等艙同樣的等級, 許多二等艙的乘客原先在其他船隻上預定的頭等艙, 卻因為泰坦尼克號的航行, 將煤炭能源轉移給泰坦尼克號; 一等艙是整艘船最為昂貴奢華的部分.
船上時間為1912年4月14日23時40分左右, 泰坦尼克號與一座冰山相撞, 造成水密艙進水, 次日凌晨2時20分左右沉沒. 2224名船員和乘客中1502人遇難, 造成如此巨大的傷亡原因之一是船上沒有足夠的救生艇供乘客和船員使用. 在這次災難中能否倖存下來難免會有些運氣成分, 但是有些人比其他人更可能生存下來, 比如婦女, 兒童和上層階級.
2. 資料概覽
本專案提供了兩份資料: train.csv檔案作為訓練集構建與生存相關的模型; 另一份test.csv檔案則用作測試集, 用我們構建出來的模型預測生存情況.
2.1 讀取資料:
import pandas as pd df_train, df_test= pd.read_csv('train.csv'), pd.read_csv('test.csv')
從訓練集開始介紹:
2.2 檢視前五行資料
#檢視前5行資料 df_train.head()

#檢視後5行資料 df_titanic.tail()

通過以上資料以及題目資料, 可以瞭解到訓練集總共有891行, 以下欄位:
.PassengerId -- Id, 具有唯一標識的作用, 即一個人員對應一個Id.
Survived -- 是否倖存, 1表示是 0則表示否
Pclass -- 船艙等級, 1: 一等艙, 2: 二等艙, 3: 三等艙
Name -- 姓名, 通常西方人的姓名結構為教名+自取名+姓, 但在很多場合中間的"自取名"會省略不寫, 而且很多人更喜歡用教名的暱稱取代正式教名. 有時也會將姓氏寫在逗號前. 比如Dooley, Mr. Patrick, 即Dooley表示姓氏, Patrick表示名, 那Mr.呢? Mr.表示頭銜, 有身份地位的象徵.
Sex -- 性別, female女性, male男性
Age -- 年齡
SibSp -- 同船配偶以及兄弟姐妹的人數
Parch -- 同船父母或者子女的人數
Ticket -- 船票
Fare -- 票價
Cabin -- 艙位
Embarked -- 登船港口
2.3 檢視資料表整體資訊
#檢視資料資訊, 其中包含資料維度, 資料型別, 所佔空間等資訊 df_train.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB
資料維度: 891行X12列
缺失欄位: Age, Cabin, Embarked
資料型別: 2個64位浮點型, 5個64位整型, 5個python物件.
2.4 描述性統計
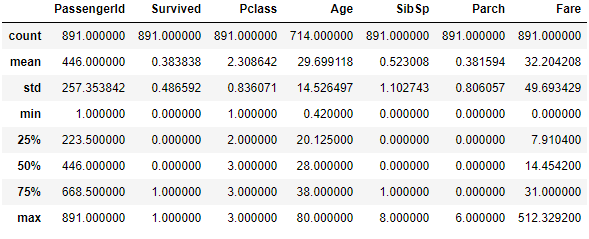
df_train.describe()
除了python物件以外的資料型別, 均參與了計算:
38.4%的人倖存, 死亡率很高;
年齡現有資料714, 缺失佔比714/891=20%;
同船兄弟姐妹與配偶人數最大為8, 同船父母或者子女的人數最大則為6, 且兩者最小值均為0, 看來有大家庭, 小家庭(獨自一人)之分;
票價最小為0, 最大為512.3, 均值為32.20, 中位數為14.45, 正偏, 貧富差距不小.
那麼與python物件對應的該怎麼檢視呢?
#同樣是使用describe()方法 df_train[['Name','Sex','Ticket','Cabin','Embarked']].describe()
顯示結果與上述有點區別, 依次來看:
姓名共有891種, 總數也891個, 姓名是唯一的;
性別中男性最多, 達到577人次;
船票中681種, 總數891, 部分人共用一張票;
艙位總數204, 缺失佔比(891-204)/891= 77%;
登船港口總數889, 缺失2個, 共有3種類型, 其中S最多, 達到644人次,

現在已經對每個特徵的大致資訊有所瞭解, 那麼下一步則是在特徵分析中探索著找出與倖存相關的特徵.
3. 特徵分析
在11個特徵中, 哪些是和倖存相關的呢?
1. PassengerId
Id僅僅是用來標識乘客的唯一性, 必然是與倖存無關.
2. Pclass
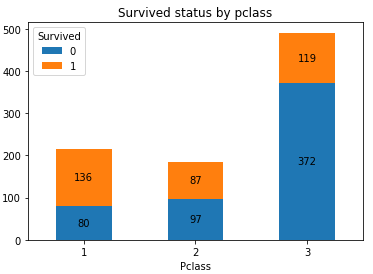
船艙等級, 一等艙是整個船最昂貴奢華的地方, 有錢人才能享受, 想必一等艙的有錢人比三等艙的窮人更容易倖存, 到底是不是呢? 用資料說話:
import numpy as np import matplotlib.pyplot as plt #生成Pclass_Survived的列聯表 Pclass_Survived = pd.crosstab(df_train['Pclass'], df_train['Survived']) #繪製堆積柱形圖 Pclass_Survived.plot(kind = 'bar', stacked = True) Survived_len = len(Pclass_Survived.count()) Pclass_index = np.arange(len(Pclass_Survived.index)) Sum1 = 0 for i in range(Survived_len): SurvivedName = Pclass_Survived.columns[i] PclassCount = Pclass_Survived[SurvivedName] Sum1, Sum2= Sum1 + PclassCount, Sum1 Zsum = Sum2 + (Sum1 - Sum2)/2 for x, y, z in zip(Pclass_index, PclassCount, Zsum): #新增資料標籤 plt.text(x,z, '%.0f'%y, ha = 'center',va='center' ) #修改x軸標籤 plt.xticks(Pclass_Survived.index-1, Pclass_Survived.index, rotation=360) plt.title('Survived status by pclass')
可以看到一等艙人員的倖存機會遠大於三等艙, 果然和船艙等級相關.
其中的列聯表就等同於以下操作:
#生成Survived為0時, 每個Pclass的總計數 Pclass_Survived_0 = df_train.Pclass[df_train['Survived'] == 0].value_counts() #生成Survived為1時, 每個Pclass的總計數 Pclass_Survived_1 = df_train.Pclass[df_train['Survived'] == 1].value_counts() #將兩個狀況合併為一個DateFrame Pclass_Survived = pd.DataFrame({ 0: Pclass_Survived_0, 1: Pclass_Survived_1})
3. Name
姓名, 總數891個且有891種不同的結果, 直接拿來討論, 沒多大意義. 但是值得注意的是姓名中有頭銜存在, 頭銜又是身份地位的象徵, 想必身份地位越高, 應當更容易倖存. 先提取出Name中的頭銜特徵:
#提取出頭銜 df_train['Appellation'] = df_train.Name.apply(lambda x: re.search('\w+\.', x).group()).str.replace('.', '') #檢視有多種不同的結果 df_train.Appellation.unique()
array(['Mr', 'Mrs', 'Miss', 'Master', 'Don', 'Rev', 'Dr', 'Mme', 'Ms',
'Major', 'Lady', 'Sir', 'Mlle', 'Col', 'Capt', 'Countess',
'Jonkheer'], dtype=object)
頭銜名稱的解讀: Mr 既可用於已婚男性, 也可用於未婚男性, Mrs 已婚女性, Miss 通常用來稱呼未婚女性, 但有時也用於稱呼自己不瞭解的年齡較大的婦女, Master 男童或男嬰, Don 大學教師, Rev 牧師, Dr 醫生或者博士, Mme 女士, Ms 既可用於已婚女性也可用於未婚女性, Major 陸軍少校, Lady 公候伯爵的女兒, Sir 常用來稱呼上級長官, Mlle 小姐, Col 上校(常用於陸空軍), Capt 船長, Countess 指伯爵夫人, Jonkheer 鄉紳.
頭銜太多了, 決定將其歸類, 那麼如何歸類呢? 先檢視下其與性別對應的人數:
Appellation_Sex = pd.crosstab(df_train.Appellation, df_train.Sex) Appellation_Sex.T

決定將將少數部分歸為'Rare', 將'Mlle', 'Ms'用'Miss'代替, 將'Mme'用'Mrs'代替.
df_train['Appellation'] = df_train['Appellation'].replace(['Capt','Col','Countess','Don','Dr','Jonkheer','Lady','Major','Rev','Sir'], 'Rare')
df_train['Appellation'] = df_train['Appellation'].replace(['Mlle','Ms'], 'Miss')
df_train['Appellation'] = df_train['Appellation'].replace('Mme', 'Mrs')
df_train.Appellation.unique()
array(['Mr', 'Mrs', 'Miss', 'Master', 'Rare'], dtype=object)
頭銜和倖存相關嗎?
#繪製柱形圖 Appellation_Survived = pd.crosstab(df_train['Appellation'], df_train['Survived']) Appellation_Survived.plot(kind = 'bar')plt.xticks(np.arange(len(Appellation_Survived.index)), Appellation_Survived.index, rotation = 360) plt.title('Survived status by Appellation')
頭銜中Master, Miss, Mrs的倖存機會均大於Mr 和 Rare.

4. Sex
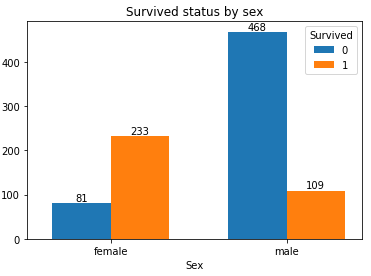
性別, 女士優先, 但在這種緊急關頭, 會讓女士優先上救生艇嗎?上資料:
#生成列聯表 Sex_Survived = pd.crosstab(df_train['Sex'], df_train['Survived']) Survived_len = len(Sex_Survived.count()) Sex_index = np.arange(len(Sex_Survived.index)) single_width = 0.35 for i in range(Survived_len): SurvivedName = Sex_Survived.columns[i] SexCount = Sex_Survived[SurvivedName] SexLocation = Sex_index * 1.05 + (i - 1/2)*single_width #繪製柱形圖 plt.bar(SexLocation, SexCount, width = single_width) for x, y in zip(SexLocation, SexCount): #新增資料標籤 plt.text(x, y, '%.0f'%y, ha='center', va='bottom') index = Sex_index * 1.05 plt.xticks(index, Sex_Survived.index, rotation=360) plt.title('Survived status by sex')
結果可以看出, 女性中的倖存率遠高於男性(也就是說女性優先上救生艇)
5. Age
由於Age特徵存在缺失值, 處理完缺失值, 再對其進行分析.
6. SibSp
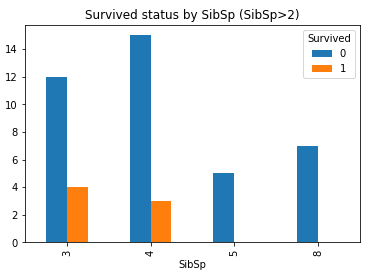
從之前的描述性統計瞭解到, 兄弟姐妹與配偶的人數最多為8, 最少為0, 哪個更容易生存呢?
#生成列聯表 SibSp_Survived = pd.crosstab(df_train['SibSp'], df_train['Survived']) SibSp_Survived.plot(kind = 'bar') plt.title('Survived status by SibSp')
可以看到, 大部分的SibSp為0, 且倖存率不大, 當SibSp數量為1,2時倖存率又有所增加, 再往上又降低.

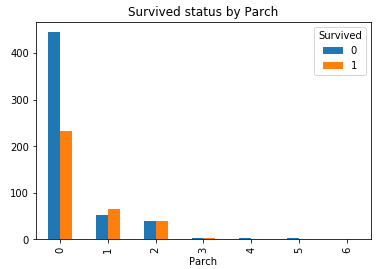
7. Parch
通過上面的描述性統計瞭解到, 同樣也可以分為大家庭(最多為6), 小家庭(最小為0), 他們的倖存率如何呢?
Parch_Survived = pd.crosstab(df_train['Parch'], df_train['Survived']) Parch_Survived.plot(kind = 'bar') plt.title('Survived status by Parch')
同樣可以看到, 大部分Parch為0, 倖存率不大, 當為1,2,3時, 有所增加, 再往上又有所減小.

8. Ticket
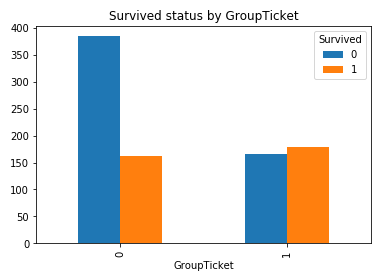
總人數891, 船票有681種, 說明部分人共用一張票, 什麼人能共用一張票呢? 想必應該認識, 就需要對他們進行歸類, 共用票的分為一類, 獨自使用的分為一類:
#計算每張船票使用的人數 Ticket_Count = df_train.groupby('Ticket', as_index = False)['PassengerId'].count() #獲取使用人數為1的船票 Ticket_Count_0 = Ticket_Count[Ticket_Count.PassengerId == 1]['Ticket'] #當船票在已經篩選出使用人數為1的船票中時, 將0賦值給GroupTicket, 否則將1賦值給GroupTicket df_train['GroupTicket'] = np.where(df_train.Ticket.isin(Ticket_Count_0), 0, 1) #繪製柱形圖 GroupTicket_Survived = pd.crosstab(df_train['GroupTicket'], df_train['Survived']) GroupTicket_Survived.plot(kind = 'bar') plt.title('Survived status by GroupTicket')
很明顯, 船上有同伴比孤身一人倖存的機會大.
9. Fare
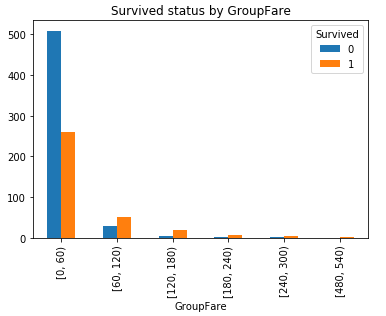
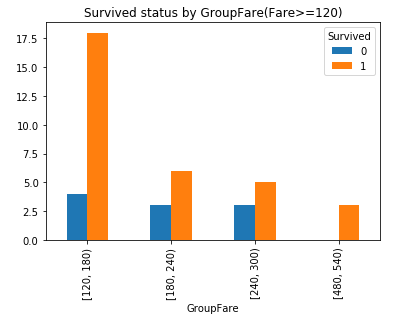
票價, 最小為0, 最大為512.3292, 生存率到底和票價有沒有關係呢?對Fare進行分組對比:
#對Fare進行分組: 2**10>891分成10組, 組距為(最大值512.3292-最小值0)/10取值60 bins = [0, 60, 120, 180, 240, 300, 360, 420, 480, 540, 600] df_train['GroupFare'] = pd.cut(df_train.Fare, bins, right = False) GroupFare_Survived = pd.crosstab(df_train['GroupFare'], df_train['Survived']) #GroupFare_Survived.plot(kind = 'bar') #plt.title('Survived status by GroupFare') GroupFare_Survived.iloc[2:].plot(kind = 'bar') plt.title('Survived status by GroupFare(Fare>=120)')
可以看到隨著票價的增長, 倖存機會也會變大.
10. Cabin
由於含有大量缺失值, 處理完缺失值再對其進行分析.
11.Embarked
同樣也含有缺失值, 處理完缺失值在對其進行分析.
以上便是對特徵中無缺失部分進行分析, 下一步則會在特徵工程中對缺失部分進行處理
4. 特徵工程
4.1 缺失值處理
缺失值主要是由人為原因和機械原因造成的資料缺失, 在pandas中用NaN或者NaT表示, 它的處理方式有多種:
1. 用某些集中趨勢度量(平均數, 眾數)進行對缺失值進行填充.
2. 用統計模型來預測缺失值, 比如迴歸模型, 決策樹, 隨機森林
3. 刪除缺失值
4. 保留缺失值
究竟採用處理方式呢, 應當結合具體的場景進行選擇.
在缺失值處理之前, 應當將資料拷貝一份, 以保證原始資料的完整性
train = df_train.copy()
4.1.1 Embarked缺失值處理
通過以上, 我們已經知道Embarked欄位中缺失2個, 且資料中S最多, 達到644個, 佔比644/891=72%, 那麼我們就採用眾數進行填充.
train['Embarked'] = train['Embarked'].fillna(train['Embarked'].mode()[0])
4.1.2 Cabin缺失值處理
Cabin缺失687個, 佔比687/891=77%, 缺失資料太多, 是否刪除呢? 艙位缺失可能代表這些人沒有艙位, 不妨用'NO'來填充.
train['Cabin'] = train['Cabin'].fillna('NO')
4.1.3 Age缺失值處理
Age缺失177個, 佔比177/891=20%, 缺失資料也不少, 而且Age在本次分析中也尤其重要(孩子和老人屬於弱勢群體, 應當更容易獲救), 不能刪除也不能保留, 那麼到底採用哪種方式呢? 由於是第一次專案, 就採用簡單點的, 採用與頭銜相對應的年齡中位數進行填補.
#求出每個頭銜對應的年齡中位數 Age_Appellation_median = train.groupby('Appellation')['Age'].median() #在當前表設定Appellation為索引 train.set_index('Appellation', inplace = True) #在當前表填充缺失值 train.Age.fillna(Age_Appellation_median, inplace = True) #重置索引 train.reset_index(inplace = True)
此時, 就完成了對Age欄位中缺失值的填充.
檢查一下, 檢查是否存在缺失值, 有多種方法, 這裡採用第三種: 順帶看下均值, 中位數
#第一種: 返回0即表示沒有缺失值 train.Age.isnull().sum() #第二種: 返回False即表示沒有缺失值 train.Age.isnull().any() #第三種: 描述性統計 train.Age.describe()
count 891.000000 mean 29.392447 std 13.268389 min 0.420000 25% 21.000000 50% 30.000000 75% 35.000000 max 80.000000 Name: Age, dtype: float64
完成了缺失值的處理, 接下來對缺失特徵進行分析
4.2 缺失特徵分析
4.2.1 Embarked
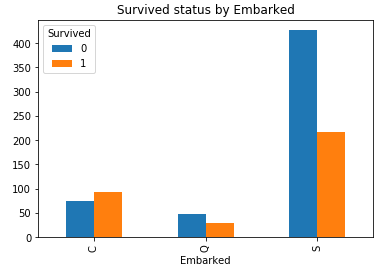
#繪製柱形圖 Embarked_Survived = pd.crosstab(train['Embarked'], train['Survived']) Embarked_Survived.plot(kind = 'bar') plt.title('Survived status by Embarked')
C港生存機會明顯高於Q港, S港, C港的有錢人多嗎?這裡不再深究, 現能確定的是它與生存相關.
4.2.2 Cabin
#將沒有艙位的歸為0, 有艙位歸為1. train['GroupCabin'] = np.where(train.Cabin == 'NO', 0, 1) #繪製柱形圖 GroupCabin_Survived = pd.crosstab(train['GroupCabin'], train['Survived']) GroupCabin_Survived.plot(kind = 'bar') plt.title('Survived status by GroupCabin')
有艙位的比沒有艙位的倖存機會大.

4.2.3 Age
#對Age進行分組: 2**10>891分成10組, 組距為(最大值80-最小值0)/10 =8取9 bins = [0, 9, 18, 27, 36, 45, 54, 63, 72, 81, 90] train['GroupAge'] = pd.cut(train.Age, bins) GroupAge_Survived = pd.crosstab(train['GroupAge'], train['Survived']) GroupAge_Survived.plot(kind = 'bar') plt.title('Survived status by GroupAge')
正如料想的那樣: 小孩倖存機會更大.

到現在我們已經完成所有特徵的分析, 接下來看一下能否在這些特徵的基礎上提取一些新的特徵.
4.3 新特徵的提取
通過以上的分析, 我們已經瞭解到生存率相關的特徵:
Pclass, Appellation(Name中提取), Sex, GroupAge(對Age分組), SibSp, Parch, GroupTicket(對Ticket分組), GroupFare(對Fare分組), GroupCabin(對Cabin分組), Embarked.
1. Pclass中沒有更多資訊可供提取, 且為定量變數, 這裡不作處理.
2. Appellation是定性變數, 將其轉化為定量變數:
train['Appellation'] = train.Appellation.map({'Mr': 0, 'Mrs': 1, 'Miss': 2, 'Master': 3, 'Rare': 4}) train.Appellation.unique()
3. Sex是定性變數, 將其轉化為定量變數, 即用0表示female, 1表示male
train['Sex'] = train['Sex'].map({'female': 0, 'male': 1})
4. 按照GroupAge特徵的範圍將Age分為10組.
train.loc[train['Age'] < 9, 'Age'] = 0 train.loc[(train['Age'] >= 9) & (train['Age'] < 18), 'Age'] = 1 train.loc[(train['Age'] >= 18) & (train['Age'] < 27), 'Age'] = 2 train.loc[(train['Age'] >= 27) & (train['Age'] < 36), 'Age'] = 3 train.loc[(train['Age'] >= 36) & (train['Age'] < 45), 'Age'] = 4 train.loc[(train['Age'] >= 45) & (train['Age'] < 54), 'Age'] = 5 train.loc[(train['Age'] >= 54) & (train['Age'] < 63), 'Age'] = 6 train.loc[(train['Age'] >= 63) & (train['Age'] < 72), 'Age'] = 7 train.loc[(train['Age'] >= 72) & (train['Age'] < 81), 'Age'] = 8 train.loc[(train['Age'] >= 81) & (train['Age'] < 90), 'Age'] = 9 train.Age.unique()
array([2., 4., 3., 6., 0., 1., 7., 5., 8.])
5. 將SibSp和Parch這兩個特徵組合成FamilySize特徵
#當SibSp和Parch都為0時, 則孤身一人. train['FamilySize'] = train['SibSp'] + train['Parch'] + 1 train.FamilySize.unique()
array([ 2, 1, 5, 3, 7, 6, 4, 8, 11], dtype=int64)
6. GroupTicket是定量變數, 不作處理
7. 按照GroupFare特徵的範圍將Fare分成10組:
train.loc[train['Fare'] < 60, 'Fare'] = 0 train.loc[(train['Fare'] >= 60) & (train['Fare'] < 120), 'Fare'] = 1 train.loc[(train['Fare'] >= 120) & (train['Fare'] < 180), 'Fare'] = 2 train.loc[(train['Fare'] >= 180) & (train['Fare'] < 240), 'Fare'] = 3 train.loc[(train['Fare'] >= 240) & (train['Fare'] < 300), 'Fare'] = 4 train.loc[(train['Fare'] >= 300) & (train['Fare'] < 360), 'Fare'] = 5 train.loc[(train['Fare'] >= 360) & (train['Fare'] < 420), 'Fare'] = 6 train.loc[(train['Fare'] >= 420) & (train['Fare'] < 480), 'Fare'] = 7 train.loc[(train['Fare'] >= 480) & (train['Fare'] < 540), 'Fare'] = 8 train.loc[(train['Fare'] >= 540) & (train['Fare'] < 600), 'Fare'] = 9train.Fare.unique()
array([0., 1., 4., 2., 8., 3.])
8. GroupCabin是定量變數, 不作處理
9. Embarked是定類變數, 轉化為定量變數.
train['Embarked'] = train.Embarked.map({'S': 0, 'C': 1, 'Q': 2})
現有特徵:
PassengerId, Survived, Pclass, Name, Appellation, Sex, Age, GroupAge, SibSp, Parch, FamilySize, Ticket, GroupTicket, Fare, GroupFare, Cabin, GroupCabin, Embarked.
刪除重複多餘的以及與Survived不相關的:
train.drop(['PassengerId', 'Name', 'GroupAge', 'SibSp', 'Parch', 'Ticket', 'GroupFare', 'Cabin'], axis = 1, inplace =True)
刪除後, 現有特徵:
Survived, Pclass, Appellation, Sex, Age, FamilySize, GroupTicket, Fare, GroupCabin, Embarked.
到這裡, 資料就處理完了, 下一步就是建立模型
5. 構建模型
用sklearn庫實現機器學習演算法 考慮用到的演算法有: 邏輯迴歸, 決策樹
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split X=train[['Pclass', 'Appellation', 'Sex', 'Age', 'FamilySize', 'GroupTicket', 'Fare', 'GroupCabin', 'Embarked']] y=train['Survived'] #隨機劃分訓練集和測試集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) #邏輯迴歸模型初始化 lg = LogisticRegression() #訓練邏輯迴歸模型 lg.fit(X_train, y_train) #用測試資料檢驗模型好壞 lg.score(X_test, y_test)
0.8044692737430168
作為第一次專案實戰, 0.8的結果還算不錯, 再試試決策樹
from sklearn.tree import DecisionTreeClassifier#樹的最大深度為15, 內部節點再劃分所需最小樣本數為2, 葉節點最小樣本數1, 最大葉子節點數10, 每次分類的最大特徵數6 dt = DecisionTreeClassifier(max_depth=15, min_samples_split=2, min_samples_leaf=1, max_leaf_nodes=10, max_features=6) dt.fit(X_train, y_train) dt.score(X_test, y_test)
0.8268156424581006
決策樹的引數是我自己隨意取的, 但對比邏輯迴歸模型有明顯提升.
對於這些引數後期會進一步優化.