
【18.10.22】雜湊(Hash)函式
阿新 • • 發佈:2018-12-17
雜湊資料結構是一種非常簡單,實用的資料結構。原理是將資料通過一定的hash函式規則,然後儲存起來。使查詢的時間複雜度近似於O(1)。進而大大節省了程式的執行時間。
雜湊表的原理如圖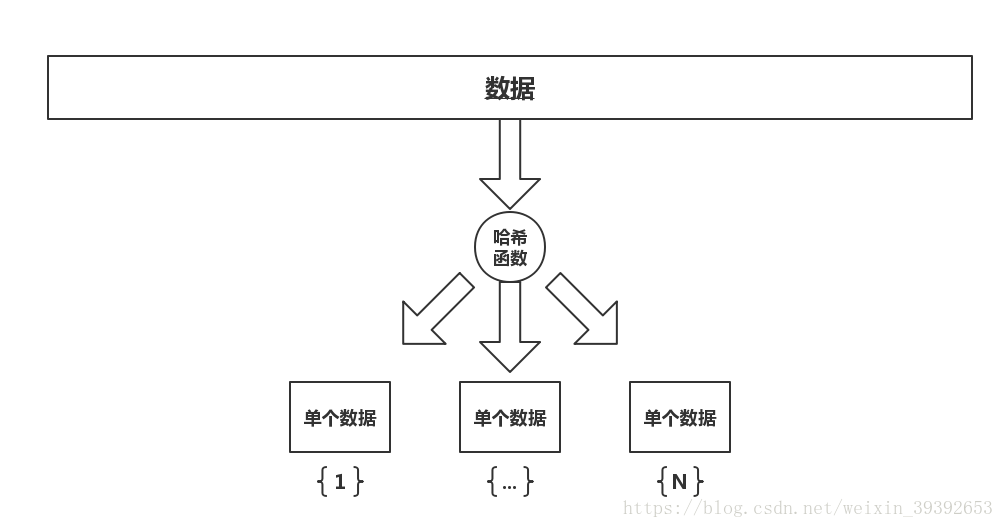
原來的資料可以直接通過雜湊函式儲存起來,這樣在搜尋的時候,等於每一個數據都有了自己的特定查詢號碼,所以在查詢時,可以通過雜湊函式,一步直接找到(不考慮衝突)。所以時間複雜度,接近O(1)。
但是雜湊最大的困擾就是雜湊函式在解決問題是會出現衝突,例如說,將16和32存在餘數為0-7的地方,那麼16先進去,餘數為0,那麼32再進去是餘數還是0,怎麼解決這一問題呢?這裡引進了兩種方法。
(開放定址)線性探測法
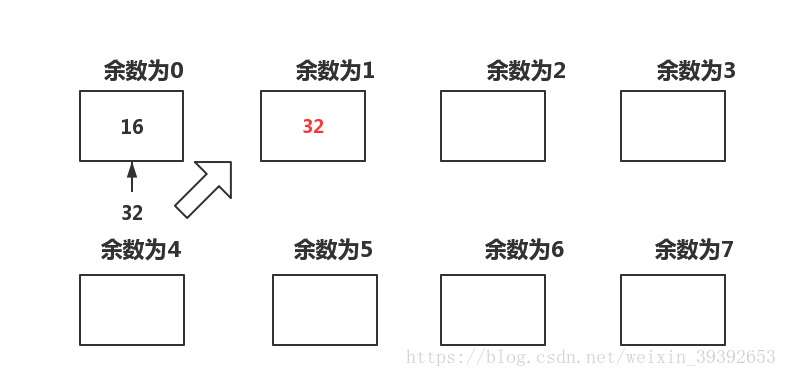
32原本也應該放在餘數為0的位置,但是餘數為0的地方已經有數字了,就向後一位放到餘數為1的位置。假設下一次放64,那麼64就放到餘數為2的地方,這樣查詢64,主需要3次,也就找到了。複雜度還是比單鏈表的O(n)要快很多。用程式碼來表示是這樣的。
標頭檔案
#define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include <stdio.h> typedef int Key; typedef enum//狀態機,用於記錄位置儲存資料的狀態 { EMPTY,//空的 EXIST,//有資料的 DELETED//刪除過得 }State; typedef struct Element//狀態 { Key key; State state; }Element; typedef int(*HashFuncType)(Key key, int capacity); typedef struct HashTable { Element * table; int size; int capacity;//容量 HashFuncType HashFunc; }HashTable; int HashSearch(HashTable *pHT, Key key); void HashDestroy(HashTable *pHT); void HashInit(HashTable *pHT, int capaicity, HashFuncType HashFunc); int mod(Key key, int capacity); void ExpandIfRequired(HashTable *pHT); int HashInsert(HashTable *pHT, Key key); int HashRemove(HashTable *pHT, Key key);
在擴容的地方引入了一個負載因子的概念,負載因子 = 雜湊表中元素個數/散列表的長度,一般大小定義在0.7到0.8之間,超過0.8會影響雜湊表的效率。但是增大負載因子的數值可以減少雜湊表所佔記憶體空間。反之減少負載因子的數值可以增加搜尋效率。
函式的.c檔案
#define _CRT_SECURE_NO_WARNINGS 1 #include "Hash.h" #include <stdio.h> #include <assert.h> void HashInit(HashTable *pHT, int capaicity, HashFuncType HashFunc) { pHT->table = (Element *)malloc(sizeof(Element)* capaicity); assert(pHT->table); pHT->size = 0; pHT->capacity = capaicity; pHT->HashFunc = HashFunc; for (int i = 0; i < capaicity; i++) { pHT->table[i].state = EMPTY; } } void HashDestroy(HashTable *pHT) { free(pHT->table); } int HashSearch(HashTable *pHT, Key key) { int index = pHT->HashFunc(key, pHT->capacity); while (pHT->table[index].state != EMPTY) { if (pHT->table[index].key == key&&pHT->table[index].state == EXIST) { return index; }//如果雜湊表存滿,這裡就是死迴圈,但是雜湊表不會被存滿 index = (index + 1) % pHT->capacity;//便於返回第一個 } return -1; } int mod(Key key, int capacity) { return key % capacity; } void ExpandIfRequired(HashTable *pHT) { int i = 0; if (pHT->size * 10 / pHT->capacity < 7)//引用負載因子,保證衝突率儘量低 { return; } /*int newCapacity = pHT->capacity * 2; Element * newTable = (Element *)malloc(sizeof(Element)* newCapacity); assert(newTable); for (i = 0; i < newCapacity; i++) { newTable[i].state = EMPTY; } free(pHT->table); pHT->table = newTable; pHT->capacity = newCapacity;*///資料搬移太麻煩 HashTable newHT; HashInit(&newHT, pHT->capacity * 2, pHT->HashFunc); for (i = 0; i < pHT->capacity; i++) { if (pHT->table[i].state == EXIST) { HashInsert(&newHT, pHT->table[i].key); } } free(pHT->table); pHT->table = newHT.table; pHT->capacity = newHT.capacity; } int HashInsert(HashTable *pHT, Key key) { ExpandIfRequired(pHT);//擴容 int index = pHT->HashFunc(key, pHT->capacity); while (1) { if (pHT->table[index].key == key && pHT->table[index].state == EXIST) { return -1; } if (pHT->table[index].state != EXIST) { pHT->table[index].key = key; pHT->table[index].state = EXIST; pHT->size++; return 0; } index = (index + 1) % pHT->capacity; } } int HashRemove(HashTable *pHT, Key key) { int index = pHT->HashFunc(key, pHT->capacity); while (pHT->table[index].state != EMPTY) { if (pHT->table[index].key == key && pHT->table[index].state == EXIST) { pHT->table[index].state = DELETED; return 0; } index = (index + 1) % pHT->capacity; } return -1; }
雜湊桶
雜湊桶就是將陣列和連結串列結合起來解決雜湊函式的衝突問題,原理用俗話講,就是數組裡存的的是一個連結串列的地址,16,放進去,在放32進去,找的時候餘數為0,就從16,往後繼續找,直到找到32為止。畫個圖。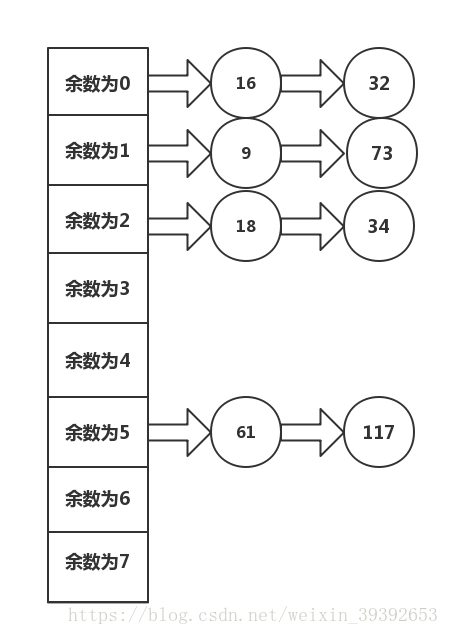
首先是標頭檔案
#define _CRT_SECURE_NO_WARNINGS 1
typedef int Key;
typedef struct Node
{
Key key;
struct Node * Next;
}Node;
typedef struct HashBucket
{
int size;
int capacity;
Node ** array;
}HashBucket;
void HashBucketInit(HashBucket *pHB, int capacity);
void HashBucketDestroy(HashBucket *pHB);
void ListDestroy(Node *first);
Node * HashBucketSearch(HashBucket *pHB, Key key);
void ExpandIfRequired1(HashBucket *pHB);
int HashBucketInsert(HashBucket *pHB, Key key);
int HashBucketRemove(HashBucket *pHB, Key key);
然後是.c檔案
#define _CRT_SECURE_NO_WARNINGS 1
#include "HashBucket.h"
#include <stdio.h>
#include <stdlib.h>
void HashBucketInit(HashBucket *pHB, int capacity)
{
pHB->array = (Node **)malloc(sizeof(Node *)*capacity);
for (int i = 0; i < capacity; i++) {
pHB->array[i] = NULL; // 空連結串列
}
pHB->capacity = capacity;
pHB->size = 0;
}
void ListDestroy(Node *first)
{
Node *next;
Node *cur;
for (cur = first; cur != NULL; cur = next)
{
next = cur->Next;
free(cur);
}
}
void HashBucketDestroy(HashBucket *pHB)
{
int i = 0;
for (i = 0; i < pHB->capacity; i++)
{
ListDestroy(pHB->array[i]);
}
free(pHB->array);
}
Node * HashBucketSearch(HashBucket *pHB, Key key)
{
int index = key % pHB->capacity;
Node *cur = pHB->array[index];
while(cur != NULL)
{
if (cur->key ==key)
{
return cur;
}
cur = cur->Next;
}
return NULL;
}
void ExpandIfRequired1(HashBucket *pHB)
{
int i = 0;
Node *node;
if (pHB->size < pHB->capacity)
{
return;
}
HashBucket NB;
HashBucketInit(&NB, pHB->capacity * 2);
for (i = 0; i < pHB->capacity; i++)
{
for (node = pHB->array[i]; node != NULL; node = node->Next)
{
HashBucketInsert(&NB, node->key);
}
}
HashBucketDestroy(pHB);
pHB->array = NB.array;
pHB->capacity = NB.capacity;
}
int HashBucketInsert(HashBucket *pHB, Key key)
{
ExpandIfRequired1(pHB);
if (HashBucketSearch(pHB, key) != NULL)
{
return -1;
}
int index = key % pHB->capacity;
Node *first = pHB->array[index];
Node *node = (Node *)malloc(sizeof(Node));
node->key = key;
node->Next = NULL;
first = node->Next;
pHB->array[index] = node;
pHB->size++;
return 0;
}
int HashBucketRemove(HashBucket *pHB, Key key)
{
int index = key % pHB->capacity;
Node *prev = NULL;
Node *cur = pHB->array[index];
while (cur != NULL)
{
if (cur->key == key)
{
if (prev == NULL)
{
pHB->array[index] = cur->Next;
}
else
{
prev->Next = cur->Next;
}
free(cur);
}
prev = cur;
cur = cur->Next;
}
return -1;
}