
WFST加權有限狀態機
WFST在語音識別中的應用,要從Mohri的《Weighted Finite-State Transducers in Speech Recognition》這篇論文開始說起。首先看下面簡單的WFST圖,它是一個有向圖,狀態轉移弧上有輸入符號、輸出符號以及對應的權重值。下圖中的輸入符號和輸出符號相同,當然在多數情況下它們是不相同的,在語音識別中,輸入可能是發聲的聲韻母,輸出是一個個漢字或詞語。
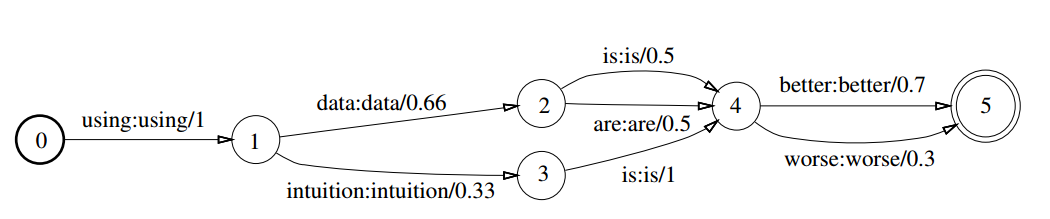
WFST的基本操作
WFST是基於半環代數理論的,詳細的半環理論可以看上面Mohri的論文或者找其它資料學習。簡單的一個半環代數結構定義為
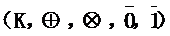
,它包含元素集合K,兩個基本操作和兩個基本單元。半環必須滿足以下定理:

在語音識別中經常使用的有Log半環和熱帶半環:
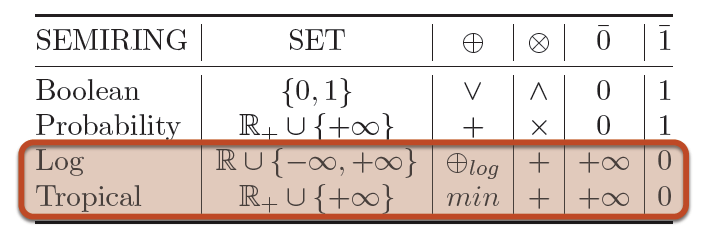
⊕log is defined by: x ⊕log y = −log(e−x + e−y).
合併操作
合併操作用於將兩個WFST合併成,合併可以用於存在多個WFST時,將它們合併到一個WFST,用於語音識別中。如下,將A和B
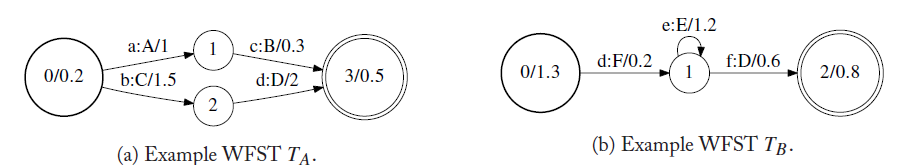
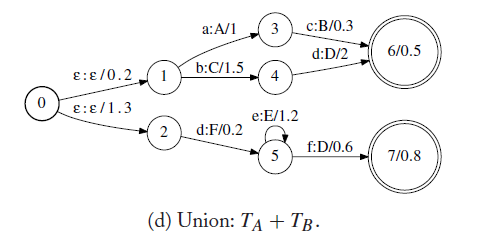
組合操作
組合操作用於合併不同層次的WFST,用於將前一個WFST的輸出符號同後一個WFST的輸入符號做合併,生成由前一個WFST的輸入符號到後一個WFST輸出符號的狀態機。假設WFST A中有一條轉移弧,輸入x,輸出y,權重是a;WFST B中有一條轉移弧,輸入是y,輸出是z,權重是b,那麼A和B的組合後,就會生成一條輸入是x,輸出是z,權重為ab。下圖為對a和b做組合操作
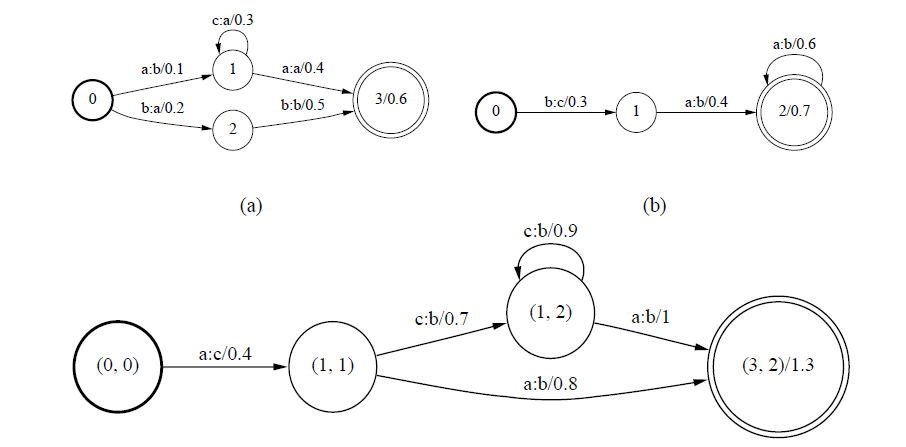
確定化操作
確定化操作用於去除WFST的冗餘,對於WFST的每一個狀態,它的每一個狀態對於同一個輸入符號,只有一個轉移弧。確定化的加權有限狀態器的優勢在於它的非冗餘性,對於確定化的加權有限狀態器,一個給定的輸入符號序列最多隻有一條路徑與其對應,這樣可以降低搜尋演算法的時間和空間複雜度。下圖為對a做確定化操作,得到b
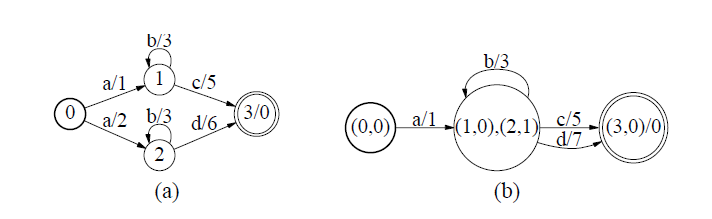
權重推移
權重前推操作將轉移弧的權重都向加權有限狀態器的初始狀態推移,這樣在採用搜尋演算法去找到最大或者最小路徑時,可以在早期就丟棄一些不可能的路徑。下圖為對a做權重前推操作,得到b

WFST在語音識別中的應用
在語音識別中,隱馬爾可夫模型(HMM)、發音詞典(lexicon)、n-gram語言模型都可以通過WFST來表示。對於語音識別,其目標函式是:
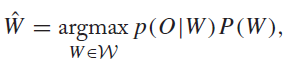
其中p(O|W)為聲學模型,p(W)為語言模型。將上述公式貝葉斯展開:
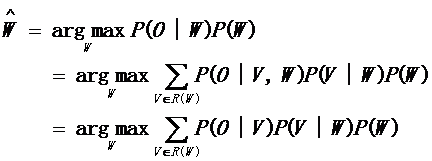
其中V是音素序列,P(V|W)表示單詞W的發音概率。另外,P(O|V,W)的概率只與V有關,P(O|V,W) = P(O|V)
在語音識別中,通常會對概率取log運算,所以上式等同於下面:
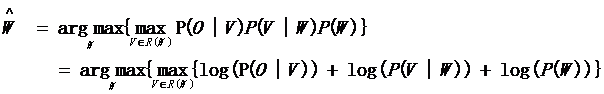
基於上述公式,可以將語音識別分成三個部分,如下:
| 表示式 |
知識源 |
權重意義 |
WFST表示 |
|---|---|---|---|
| -logP(W) |
語言模型 |
wG(W→W) |
G |
| -logP(V/W) |
發音詞典模型 |
wL(V→W) |
L |
| -logP(O/V) |
聲學模型 |
wH(O→V) |
H |
採用知識源的方式替換上述的公式,得到:
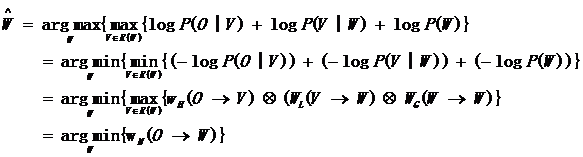
一個完整的語言識別加權有限狀態轉換器可以表達為:
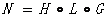
。在引入音素窗後,上式在H後增加音素窗的變化
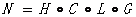
。
通常N的組成由後往前進行,先進行LG的組合,再進行CLG的組合,最後進行HCLG的組合,即N = Min(H C Min(Det(L * G)))。
語言模型G
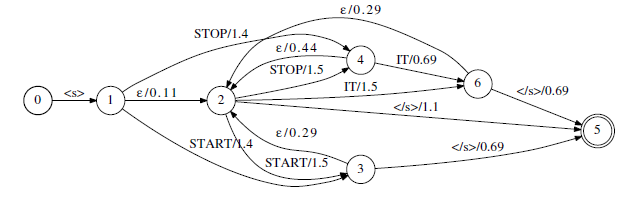
在語音識別中,語言模型用n-gram模型表示,常用的有bigram、trigram。n-gram模型與一個(n-1)階馬爾可夫鏈相似,所以可以用WFSA來表示。如下是一個簡單的語言模型”start it”和“stop it”轉成WFSA的示例:
發音詞典模型L
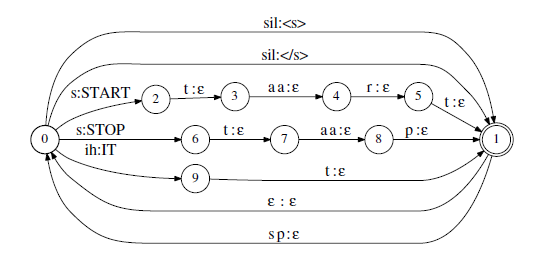
發音詞典模型表示一個單詞有哪些音素序列串構成。當用WFST來表示L模型時,輸入是音素串,到達終止狀態時,輸出一個相對應的單詞。

上下文相關音子模型C
上下文相關音子模型用於將三音子序列轉換為音素序列,這通常很容易構造,只需要輸入三音子串,輸出其central音素即可。
聲學模型H
聲學模型用HMM來進行建模,對於輸入的MFCC特徵,通過GMM或者DNN計算出當前幀對應的HMM發射態的概率。
將上述的HCLG通過組合以及相關的操作後,得到一個完整的解碼圖,配合GMM或者DNN模型去計算每一幀對應HMM狀態的概率,採用Viterb或者beam-search演算法,可以得到完整語音對應權重最小的文字,即為最後的解碼結果。