
從零開始學推薦系統一:基於鄰域的演算法
本系列文章會從最簡單的推薦系統到目前主流的推薦系統解決方案做總結。
1. 基於鄰域的演算法
基於鄰域的演算法是推薦系統中最基本的演算法,在業界得到了廣泛應用。基於鄰域的演算法分為兩大類,一類是基於使用者的協同過濾演算法,另一類是基於物品的協同過濾演算法。
1.1 基於使用者的協同過濾演算法(UserCF)
定義:
在一個線上個性化推薦系統中,當一個使用者A需要個性化推薦時,可以先找到和他有相似興趣的其他使用者,然後把那些使用者喜歡的、而使用者A沒有聽說過的物品推薦給A。
步驟:
- 找到和目標使用者興趣相似的使用者集合。
- 找到這個集合中的使用者喜歡的,且目標使用者沒有聽說過的物品推薦給目標使用者。
設使用者u和使用者v ,N(u)表示使用者u曾經有過正反饋的物品集合,N(v)表示使用者v曾經有過正反饋的物品集合。可以通過下面幾種方法計算使用者的興趣相似度。
- Jaccard公式簡單地計算u和v的興趣相似度:
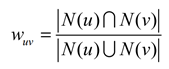
- 或者通過餘弦相似度計算:
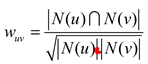
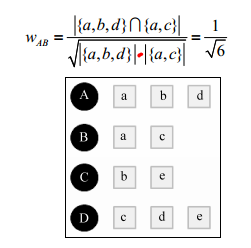
舉例:
使用者A對物品{a, b, d}有過行為,使用者B對物品{a, c}有過行為,利用餘弦相似度公式計算使用者A和使用者B的興趣相似度為:
同理,可以計算出使用者A和使用者C、 D的相似度:
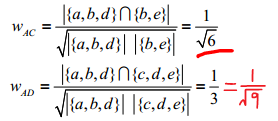
分析:
以上例子對兩兩使用者通過利用餘弦相似度計算相似度。這種方法的時間複雜度是O(|U|*|U|),這在使用者數很大時非常耗時

這裡的W是餘弦相似度中的分子部分,然後將W除以分母可以得到最終的使用者興趣相似度。
得到使用者之間的興趣相似度後, UserCF演算法會給使用者u推薦和他興趣最相似的K個使用者喜歡的物品。如下的公式度量了UserCF演算法中使用者u對物品 i 的感興趣程度:

其中, S(u, K)包含和使用者u興趣最接近的K個使用者, N(i)是對物品 i 有過行為的使用者集合,即使用者v的集合, wuv是使用者u和使用者v的興趣相似度, rvi代表使用者v對物品i的興趣。
舉例:
以上圖為例,對使用者A進行推薦。選取K=3,使用者A對物品c、 e沒有過行為,因此可以把這兩個物品推薦給使用者A。根據UserCF演算法,使用者A對物品c、 e的興趣是:
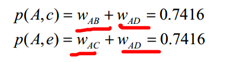
分析:
使用MovieLens資料集上的離線實驗來評測基礎演算法的效能。 UserCF只有一個重要的引數K,即為每個使用者選出K個和他興趣最相似的使用者,然後推薦那K個使用者感興趣的物品:
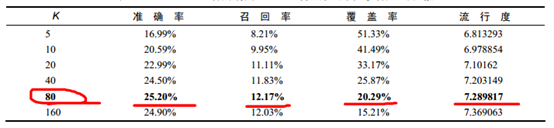
可以發現引數K是UserCF的一個重要引數,它的調整對推薦演算法的各種指標都會產生一定的影響。
準確率和召回率:
可以看到,推薦系統的精度指標(準確率和召回率)並不和引數K成線性關係。在MovieLens資料集中,選擇K=80左右會獲得比較高的準確率和召回率。因此選擇合適的K對於獲得高的推薦系統精度比較重要。當然,推薦結果的精度對K也不是特別敏感,只要選在一定的區域內,就可以獲得不錯的精度。
流行度:
可以看到,在3個數據集上K越大則UserCF推薦結果就越熱門。這是因為K決定了UserCF在給你做推薦時參考多少和你興趣相似的其他使用者的興趣,那麼如果K越大,參考的人越多,結果就越來越趨近於全域性熱門的物品。
覆蓋率:
可以看到,在3個數據集上, K越大則UserCF推薦結果的覆蓋率越低。覆蓋率的降低是因為流行度的增加,隨著流行度增加, UserCF越來越傾向於推薦熱門的物品,從而對長尾物品的推薦越來越少,因此造成了覆蓋率的降低。
使用者相似度計算的改進
餘弦相似度計算使用者興趣過於粗糙。
改進思路:兩個使用者對冷門物品採取過同樣的行為更能說明他們興趣的相似度。
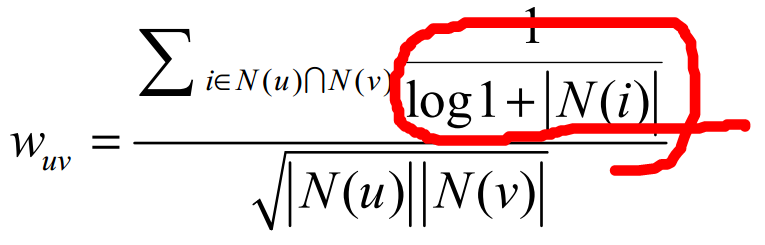
通過1/log(1+|N(i)|)懲罰了使用者u和使用者v共同興趣列表中熱門物品對他們相似度的影響。這種演算法叫做User-IIF演算法。
同樣地,對UserCF-IIF的推薦效能,並將其和UserCF進行對比:

可以看到,UserCF-IIF在各項效能上略優於UserCF。這說明在計算使用者興趣相似度時考慮物品的流行度對提升推薦結果的質量確實有幫助。
基於使用者的協同過濾總結
- 隨著著網站的使用者數目越來越大,計算使用者興趣相似度矩陣將越來越困難,其運算時間複雜度和空間複雜度的增長和使用者數的增長近似於平方關係。
- 很難對推薦結果作出解釋。
1.2 基於物品的協同過濾演算法(ItemCF)
基於物品的協同過濾演算法是目前業界應用最多的演算法。
定義:
給使用者推薦那些和他們之前喜歡的物品相似的物品。
步驟:
- 計算物品之間的相似度。
- 根據物品的相似度和使用者的歷史行為給使用者生成推薦列表。
物品的相似度:
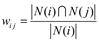
其中分母 |N(i)| 是喜歡物品 i 的使用者數,而分子 |N(i) ∩N(j)| 是同時喜歡物品 i 和物品 j 的使用者數。上述公式可以理解為喜歡物品 i 的使用者中有多少比例的使用者也喜歡物品 j 。
分析:
但上述公式存在一個問題,即如果物品 j 很熱門,很多人都喜歡,那麼Wij就會很大,接近1。即會造成任何物品都會和熱門的物品有很大的相似度,導致出現長尾效應。
物品相似度計算的改進
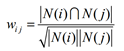
通過懲罰物品j的權重,從而減輕了熱門物品會和很多物品相似的可能性。
用ItemCF演算法計算物品相似度時也可以首先建立使用者—物品倒排表(即對每個使用者建立一個包含他喜歡的物品的列表),然後對於每個使用者,將他物品列表中的物品兩兩在共現矩陣C中加1。
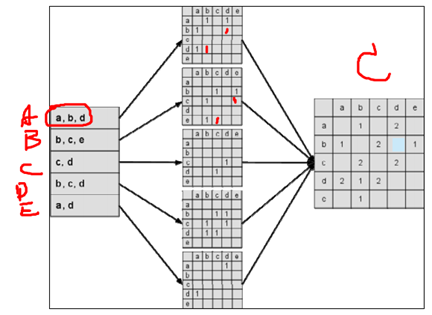
上圖左邊是輸入的使用者行為記錄,每一行代表一個使用者感興趣的物品集合。右邊矩陣C中的 C[i][j] 記錄了同時喜歡物品 i 和物品 j 的使用者數。最後,將C矩陣歸一化可以得到物品之間的餘弦相似度矩陣W。
在得到物品之間的相似度後, ItemCF通過如下公式計算使用者u對一個物品 j 的興趣:
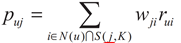
這裡N(u)是使用者喜歡的物品的集合, S(j,K)是和物品 j 最相似的K個物品的集合, wji是物品j和i的相似度, rui是使用者u對物品 i 的興趣度。(對於隱反饋資料集,如果使用者u對物品 i 有過行為,那麼rui=1)
該公式的含義是,和使用者歷史上感興趣的物品越相似的物品,越有可能在使用者的推薦列表中獲得比較高的排名。
例子:
使用者喜歡《C++ Primer中文版》和《程式設計之美》兩本書。然後ItemCF會為這兩本書分別找出和它們最相似的3本書,並根據公式的定義計算使用者對每本書的感興趣程度。

可以看到, ItemCF的一個優勢就是可以提供推薦解釋,即利用使用者歷史上喜歡的物品為現在的推薦結果進行解釋。
分析:
ItemCF演算法離線實驗的各項效能指標的評測結果:
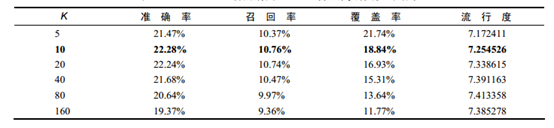
精度(準確率和召回率)
可以看到ItemCF推薦結果的精度也是不和K成正相關或者負相關的,因此選擇合適的K對獲得最高精度非常重要。
流行度
和UserCF不同,引數K對ItemCF推薦結果流行度的影響也不是完全正相關的。隨著K的增加,結果流行度會逐漸提高,但當K增加到一定程度,流行度就不會再有明顯變化。
覆蓋率
K增加會降低系統的覆蓋率。
物品相似度計算的改進
兩個物品產生相似度是因為它們共同出現在很多使用者的興趣列表中。換句話說,每個使用者的興趣列表都對物品的相似度產生貢獻。那麼,是不是每個使用者的貢獻都相同呢?
未必。有些使用者雖然活躍,但是買這些書並非都是出於自身的興趣,而且這些書覆蓋了當當網圖書的很多領域,所以這個使用者對於他所購買書的兩兩相似度的貢獻應該遠遠小於一個只買了十幾本自己喜歡的書的文學青年。即:活躍使用者對物品相似度的貢獻應該小於不活躍的使用者。
ItemCF-IUF演算法
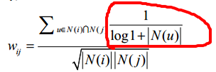
上式增加使用者活躍度對數的倒數這個引數來修正物品相似度的計算公式。

ItemCF-Norm 演算法
研究中發現如果將ItemCF的相似度矩陣按最大值歸一化,可以提高推薦的準確率。因此,如果已經得到了物品相似度矩陣w,那麼可以用如下公式得到歸一化之後的相似度矩陣w':
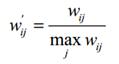
歸一化的好處不僅僅在於增加推薦的準確度,它還可以提高推薦的覆蓋率和多樣性。

可以看到,歸一化確實能提高ItemCF的效能,其中各項指標都有了比較明顯的提高。
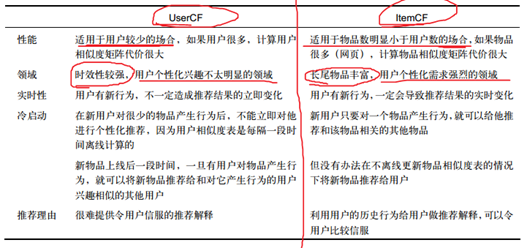
1.3 UserCF和ItemCF的綜合比較
UserCF給使用者推薦那些和他有共同興趣愛好的使用者喜歡的物品。
ItemCF給使用者推薦那些和他之前喜歡的物品類似的物品。.
所以,UserCF的推薦結果著重於反映和使用者興趣相似的小群體的熱點,既社會化。而ItemCF的推薦結果著重於維繫使用者的歷史興趣,即個性化。
因此,在新聞推薦中使用UserCF,原因有三:
- 使用者的興趣不是特別細化,絕大多數使用者都喜歡看熱門的新聞。
- 物品的更新速度遠遠快於新使用者的加入速度,而且對於新使用者,完全可以給他推薦最熱門的新聞。
- 這類網站使用者數相對較穩定,維護使用者相似度矩陣代價較小。
在圖書、電子商務和電影網站中使用ItemCF,原因有三:
- 在這些網站中,使用者的興趣是比較固定和持久的,即對物品熱門程度並不是那麼敏感。
- 這些網站的物品更新速度不會特別快,一天一次更新物品相似度矩陣對它們來說不會造成太大的損失,是可以接受的。
- 這類網站物品數相對較穩定,維護物品相似度矩陣代價較小。
總結
1.4 哈利波特問題
在設計ItemCF演算法之初發現ItemCF演算法計算出的圖書相關表存在一個問題,就是很多書都和《哈利波特》相關。也就是說,購買任何一本書的人似乎都會購買《哈利波特》。後來他們研究發現,主要是因為《哈利波特》太熱門了,確實是購買任何一本書的人幾乎都會購買它。
但實際上,這些書與《哈利波特》並不同屬同一型別。換句話說,哈利波特問題描述的是兩個不同領域的最熱門物品之間往往具有比較高的相似度。
解決辦法:
其中一個辦法是可以在分母上加大對熱門物品的懲罰,比如採用如下公式:
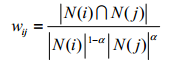
其中α∈[0.5 ,1] 。通過提高α,就可以懲罰熱門的物品 j 。而更好的方法是依靠引入物品的內容資料解決這個問題,比如對不同領域的物品降低權重等。