
關於Jmeter長時間壓測的視覺化監控報告
最近有個測試專案,是針對雲平臺的資料庫連線穩定性測試,一般做穩定性測試想到的工具是Loadrunner,因為“成熟穩定”,但是這麼重量級的工具不適合搬到雲平臺上開展測試。而Jmeter作為一款優秀的開源測試工具,屬於經量級的,但是基於java的穩定性還是不如Loadrunner。【關於jmeter的特性和效能優化,可以參見我的另一篇文章《針對性能測試工具Gatling與Jmeter的比較及看法》】
首先將Jmeter輕量包(免安裝)上傳到雲平臺,這次肯定是要分散式測試了(因為要測試20臺虛擬機器與阿里Mysql連線的穩定性),每一臺虛擬機器都部署上JDK和Jmeter,並啟動jmeter-server。主控機的jmeter肯定不能用GUI模式呼叫了(要是那樣的話不得記憶體溢位或卡到死),直接通過以下命令呼叫(好處就不說了):
jmeterHome3.1\bin\jmeter -n -t jmeterHome3.1\bin\MysqlTest.jmx -R 10.2.116.116,10.2.116.118,[省略後面的IP] -l DashReport\log-20180413.csv -e -o DashReport\htmlReport-20180413
如果是要生成不被覆蓋的測試報告,可以通過自動生成日期時間來新生成報告:
Windows下的執行指令碼樣例為:
@echo off
set a=%time:~0,2%%time:~3,2%%time:~6,2%
set b=0%time:~1,1%%time:~3,2%%time:~6,2%
if %time:~0,2% leq 9 (set c=%b%)else set c=%a%
jmeterHome3.2\bin\jmeter -n -t rfAppTest.jmx -l DashReport\log-%Date:~0,4%%Date:~5,2%%Date:~8,2%%c%.csv -e -o DashReport\htmlReport-%Date:~5,2%%Date:~8,2%%c%
pause
Linux下的執行指令碼樣例為:
#!/bin/bash
Cur_Dir=$(cd "$(dirname "$0")"; pwd)
$Cur_Dir/jmeterHome3.2/bin/jmeter -n -t $Cur_Dir/jmeterHome3.2/bin/websocket-test.jmx -l $Cur_Dir/DashReport/log-$(date -d "today" +"%Y%m%d%H%M%S").csv -e -o $Cur_Dir/DashReport/htmlReport-$(date -d "today" +"%m%d%H%M%S")
對於遠端負載機較多的情況,就可以在jmeter-server檔案上配置,然後用 -r (上面是用-R)來表示啟動遠端壓力機。上面的命令除了生成報告日誌csv,還有通過DashReport自動生成檢視報告。關於如何產生DashReport視覺化測試報告,可以參考我的另一篇文章 Jmeter和Ant的html報告優化及Dashboard Report介紹【https://blog.csdn.net/smooth00/article/details/78728060】。
按理到這一步,就達到我的要求了,但是經過實際操作後發現問題的嚴峻性了,那就是隨著測試時間的延長(不到4小時),發現log-20180413.csv報告檔案越來越大,當超過1G後,問題就暴露了,這麼大的監控日誌如何轉換成html報告(實際上只有最近1個小時的監控資料能夠轉換,再長時間的就處理不過來了,更別提我要進行跨天的測試監控),另外一個嚴峻的問題是,隨著測試檔案的越來越大,對Jmeter造成了挑戰,這就是最大的不穩定因素,磁碟的讀寫瓶頸,隨時都可能讓它崩潰。(注:這個問題在Windows下表現尤為明顯,在Linux下就算產生再大的報告檔案也不至於讓Jmeter出現執行異常,但是最終要將超過幾個G的報告轉為html報告也會是件要命的事,需要找個記憶體高的機器專門用來轉換html報告)
這時候我的想法就是如何將測試監控日誌儲存到資料庫,第一個方案就是通過Beanshell來計算JDBC請求的響應時間,分別通過BeanShell PreProcessor和BeanShell PostProcessor來獲取請求前和請求後的時間戳,然後相減算出時間差:
import java.util.Date;
long planDate2 = System.currentTimeMillis();//planDate是在PreProcessor生成的時間戳
long conTime=planDate2-Long.valueOf(vars.get("planDate")).longValue();
vars.put("connTime",conTime.toString());
同時獲取每臺壓力機的IP
String addr = InetAddress.getLocalHost().getHostAddress();//獲得各個壓力機IP
vars.put("addrIP",addr);
然後把請求的響應時間、壓力機IP、請求開始的時間戳,把這些資料通過JDBC的insert請求插入到資料庫表中,作為監控資料,然後通過視覺化平臺展現出來(我用的是我們APM工具當中的自定義輪詢查詢的方式),展現效果如下:
按理這樣也算達到我的目的了,但是接著又出現一個新問題,就是這種輪詢展現的方式過於機械化,因為輪詢的時間是1分種一次,精度上不夠,又不能靈活的選擇監控時間段,這樣隨著測試時間的拉長,測試曲線圖密度越來越大,最後就不直觀了。而且還有個更嚴重的問題,如果Jmeter出問題了,也沒法第一時間發現和排查。
看來我的想法跟實際還是有不小差距,上網專門查了一下,發現Jmeter其實是有相關的功能的,即 Jmeter + Grafana + InfluxDB的方式,於是我又開始用最短的時間,配置了InfluxDB、Grafana(開始以為這個部署過程會很長,沒想到這兩工具也是輕量化的,不用安裝也能執行)。
1、下載,grafana-5.0.4.windows-x64.zip和influxdb-1.5.1_windows_amd64.zip,為什麼下載Windows版本,主要是因為懶得在Linux下配置,先用順Windows下的再說。
(1)到官網下載influxdb,https://portal.influxdata.com/downloads,說是要翻牆下,其實也不用,只要右鍵檢視網站原始碼,就能看到下載連結:

(2)到官網下載grafana,https://grafana.com/grafana/download?platform=windows
除了windows版本,還有linux版本,我們可以將兩版本合到一起,做成一個通用包。
2、直接解壓,就可以開始配置和使用
(1)針對influxdb,修改influxdb.conf檔案(jmeter通過2003埠連)
[[graphite]]
enabled = true
database = "jmeter"
bind-address = ":2003"
protocol = "tcp"
consistency-level = "one"
把http的8086埠的註釋也去掉(grafana通過8086埠連)
[http]
# Determines whether HTTP endpoint is enabled.
enabled = true
# The bind address used by the HTTP service.
bind-address = ":8086"
啟動influxdb,通過CMD到influxdb的目錄下,直接命令 influxd -config influxdb.conf 啟動
(2)針對Jmeter,新增“監聽器 -> Backend Listener”,並配置“Backend Listener”,主要配置Host,如下圖:

注意IP和埠的配置要正確。
以上的配置,跟預設情況不一樣的是,將summaryOnly設為false,useRegexpForSamplersList設為true,並配置了samplersList的正則表達試為JDBC.*,目的是可以監聽所有以JDBC名稱開頭的Request請求。
(3)針對grafana,很簡單,到Grafana安裝目錄中的bin目錄下,雙擊grafana-server.exe啟動程式
訪問http://localhost:3000,用admin(密碼admin)登入,開始配置:
第一步、配置資料庫,在設定-->Data Sources,新增,配置以下畫圈的部分就可以了,然後直接儲存通過

第二步,在面板中新增Graph,選擇Data Source為jmeter,在查詢條件中,選擇你要監控的指標,可以添選多個指標
 配置好了,就能看到圖了。如果看不到圖,請用Jmeter多發幾次請求。可以選擇最右上角的監控時間段來精確化的監控指定時間段的測試資料:
配置好了,就能看到圖了。如果看不到圖,請用Jmeter多發幾次請求。可以選擇最右上角的監控時間段來精確化的監控指定時間段的測試資料:

以上是我配置後產生的監控效果圖,由於可以實時監控,檢視歷史監控,按15分種、半小時、1小時、1天的不同時段展現,很好的解決了我要求長時間監控測試的目的。測試資料不再通過檔案儲存,避免了磁碟IO限制的問題,也解決了測試時間過長,報告無法讀取和展現的問題。
另外用這種測試模式,我們還可以達到Jmeter分散式叢集的去中心化,讓Master不再負責各節點測試資料的收集和處理(交給influxdb來完成),只專注於slave的排程,甚至可以進行多master-slave部署,由Jenkins進行同步排程測試。
附:幾種我們常用的監控指標:
| 名稱 |
描述 |
| jmeter.all.h.count |
所有請求的TPS |
| jmeter.<請求名稱>.h.count |
對應<請求名稱>的TPS |
| jmeter.all.ok.pct99 |
99%的請求響應時間 |
| jmeter.<請求名稱>.ok.pct99 |
對應<請求名稱>99%的請求響應時間 |
| jmeter.all.test.startedT |
執行緒數 |
為了能方便的同時啟動influxDB和Grafana,我專門寫了啟動指令碼,有兩份,一份是windows版的,一份是Linux版的
Windows版的
@echo off
start cmd /k ""%~dp0influxdb-1.5.1/influxd.exe" -config "%~dp0influxdb-1.5.1/influxdb.conf""
cd "%~dp0grafana-5.0.4\bin"
start cmd /k "grafana-server.exe"
Linux版的(為了後臺執行並且避免程序衝突,linux版的寫的比較複雜一些):
#!/bin/bash
# Author:zheng
# Date:2018-04-18
InstanceCount=1
Cur_Dir=$(cd "$(dirname "$0")"; pwd)
influxdb_v=influxdb-1.5.1
grafana_v=grafana-5.0.4
chmod -R 777 $Cur_Dir/$influxdb_v/bin
chmod -R 777 $Cur_Dir/$grafana_v/bin
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----Current directory is " $PWD
# 檢查$ProcessName例項是否已經存在
#while [ 1 ] ; do
#$PROCESS_NUM獲取指定程序名的數目
PROCESS_NUM=`ps -ef | grep "influxd" | grep -v "grep" | wc -l`
if [ $PROCESS_NUM -lt $InstanceCount ];
then
StopCount=`expr $InstanceCount - $PROCESS_NUM `
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----influxd service [total $StopCount] was not started."
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----Starting influxd service[total $StopCount] ."
(nohup $Cur_Dir/$influxdb_v/bin/influxd -config $Cur_Dir/$influxdb_v/influxdb.conf) >>/dev/null 2>&1 &
else
PROCESS_PID=`pidof -s influxd | awk '{print $1}'`
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "---kill influxd [pid $PROCESS_PID]"
pidof -s influxd | awk '{print $1}' | xargs kill -9
sleep 2
echo "----Restart influxd service[total $InstanceCount]."
(nohup $Cur_Dir/$influxdb_v/bin/influxd -config $Cur_Dir/$influxdb_v/influxdb.conf) >>/dev/null 2>&1 &
fi
PROCESS_NUM=`ps -ef | grep "grafana-server" | grep -v "grep" | wc -l`
if [ $PROCESS_NUM -lt $InstanceCount ];
then
StopCount=`expr $InstanceCount - $PROCESS_NUM `
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----grafana service [total $StopCount] was not started."
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----Starting grafana service[total $StopCount] ."
cd $Cur_Dir/$grafana_v/bin
(nohup ./grafana-server) >>/dev/null 2>&1 &
else
PROCESS_PID=`pidof -s grafana-server | awk '{print $1}'`
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "---kill grafana-server [pid $PROCESS_PID]"
pidof -s grafana-server | awk '{print $1}' | xargs kill -9
sleep 2
echo "----Restart grafana service[total $InstanceCount]."
cd $Cur_Dir/$grafana_v/bin
(nohup ./grafana-server) >>/dev/null 2>&1 &
fi
sleep 2
Grafana作為一款輕量級的報表工具,功能還是很強大的,以下是我配置的指標效果圖(有點花哨):
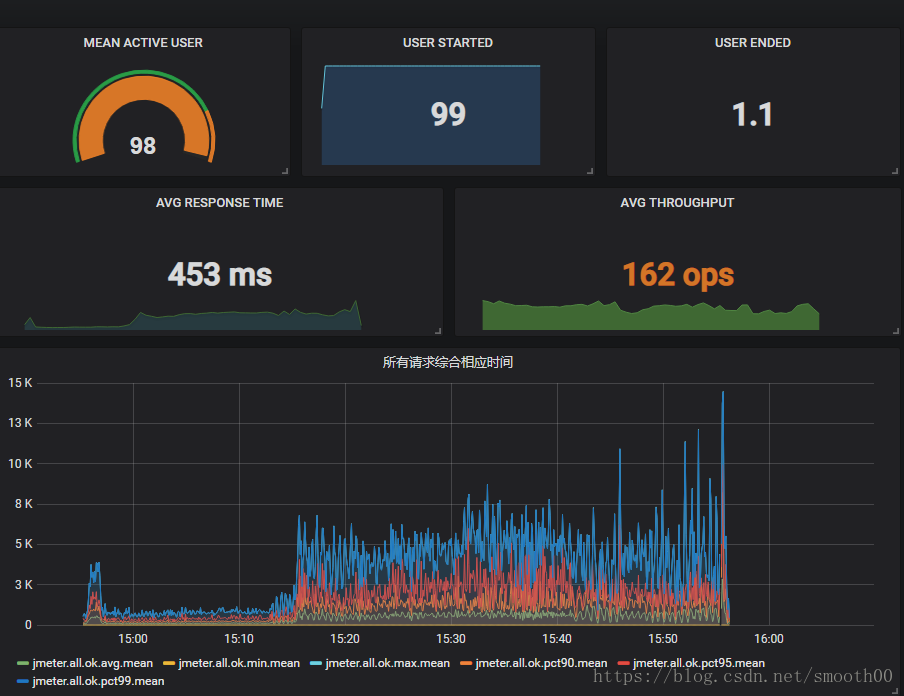

補充說明:
針對Jmeter的Backend Listener如果在implementation選項中選擇第二項,我們將會得到不一樣的監控效果:

重新配置一下引數:

再次發起測試,我們會發現influxDB的表結構出現了變化,變成單獨建立一個總的jmeter表(原來的方式是一個統計指標建立一張表,會有很多張表):

這樣的表資訊量大,可以方便構建更直觀的監控檢視:

測試監控完全依賴埠的連通性,請確保2003和8086埠的通達,否則監控不到資料時,也不會有相關的報錯提示。
需要軟體測試資料的小夥伴,可以來加群:747981058。群內會有不定期的發放免費的資料連結,這些資料都是從各個技術網站蒐集、整理出來的,如果你有好的學習資料可以私聊發我,我會註明出處之後分享給大家。