對於sortBy運算元的一些理解
阿新 • • 發佈:2018-12-17
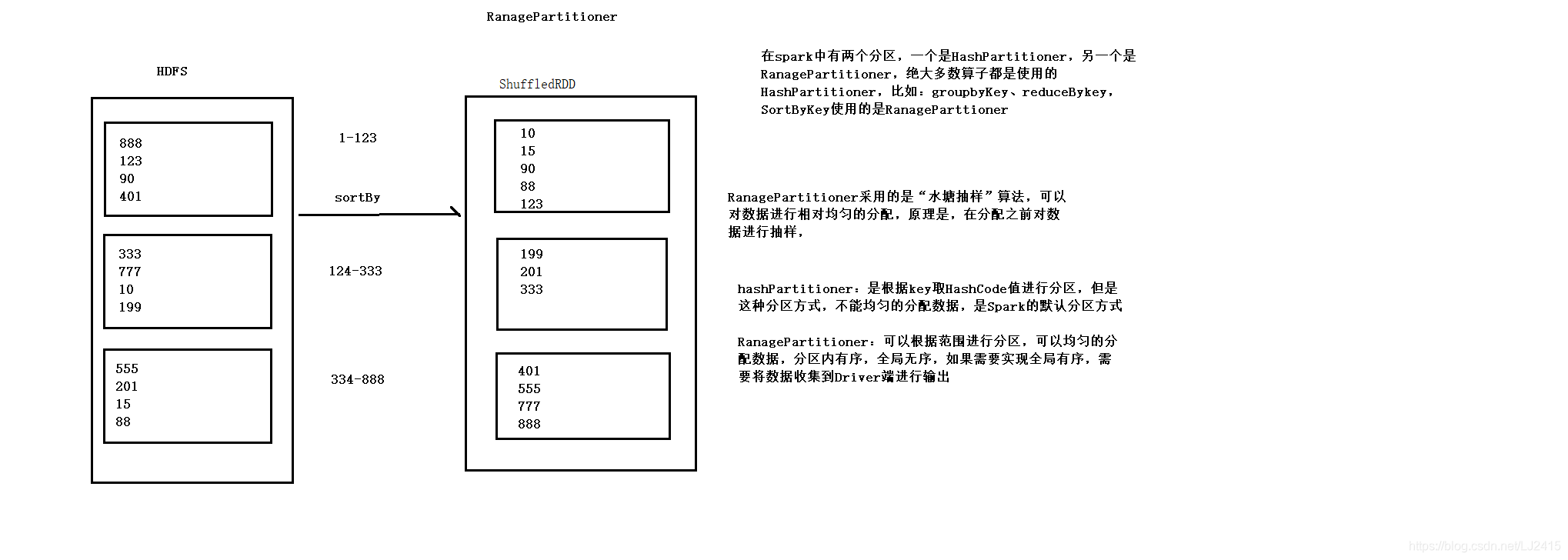
package day03 import org.apache.spark.{SparkConf, SparkContext} /** * RanagePartitioner採用的是"水塘抽樣"演算法,可以對資料進行相對均勻的分配 * 原理是,.在分配之前對資料進行抽樣 * * 與hashPartitioner不同的是,hashPartitioner是根據key取HashCode值進行分割槽,但是這種分割槽方式 * 不能均勻的分配資料,是Spark的預設分割槽方式 * * RanagePartitioner:可以根據範圍進行分割槽,可以均勻的分配資料,分割槽內有序,全域性無序 * 如果需要實現全域性有序,需要將資料收集到Driver端進行輸出 */ object RanagePartitioner { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("RanagePartitioner").setMaster("local[*]") val sc =new SparkContext(conf) val list =Array(1,22,3,4,5,90,66,55,87,34,22,99) val numbers=sc.parallelize(list) //區域性有序,全域性有序 val result =numbers.sortBy(x=>x) //定義一個函式變數 val func =(index:Int,it:Iterator[Int])=>{ println(s"index:${index}, ele:${it.toList.mkString(",")}") it } val result2=result.mapPartitionsWithIndex(func) //收集到Driver端 result2.collect().foreach(println(_)) sc.stop() } }